




GMOインターネットグループ
「GMO GPUクラウド」ベアメタルサービス搭載GPUの実力を検証
GMOインターネットグループの、GMOインターネット株式会社(代表取締役 社長執行役員:伊藤 正 以下、GMOインターネット)は「GMO GPUクラウド」において、2024年11月より提供している「NVIDIA H200 Tensor コアGPU」(以下、H200 GPU)、および2025年12月にベアメタル構成にて国内最速クラスで提供開始した「NVIDIA HGX B300 AI インフラストラクチャ」(以下、B300 GPU)を導入したGPUクラウドサービスの、性能特性を検証しました。生成AI開発から運用までの実用性と演算性能の両面を評価するため、以下3つのベンチマーク(性能検証)を実施した結果を公開いたします。
【実施したベンチマークの概要】
1.大規模言語モデル(LLM)の学習ベンチマーク:「学習効率」と「演算速度」を評価する指標
LLMを実際に学習(ファインチューニング)させ、目標の品質(損失)に到達するまでの学習完了時間を測るベンチマーク
2.vLLM bench throughputによる推論ベンチマーク:単位時間あたりに生成可能な「トークン量(処理スループット)」を評価する指標
LLM推論のバッチ処理をできるだけ高速に実行し、1秒あたりに生成できる出力トークン数(output tokens/s)など最大スループットを測る推論性能ベンチマーク
3.HPL Benchmark によるベンチマーク:高精度な数値計算の処理能力を評価する指標
密行列の連立一次方程式(Ax=b)を解く処理を通じて、浮動小数点演算性能(GFLOPS)を測定するHPC系の基礎計算性能ベンチマーク 科学技術計算における複雑で精密な数値計算の性能を測定
これらのベンチマークにより、生成AIの開発から運用までの実用性能と、演算性能の両面から「B300 GPU」、「H200 GPU」の各々の特性を検証し、ワークロードに応じた最適なGPUを選択できる参考情報を提供します。
今回の検証では生成AIワークロードにおいて、「B300 GPU」は「H200 GPU」と比較して学習で約2倍、推論では約2.5倍の処理性能を発揮することが確認されました。一方、スーパーコンピュータの性能評価に用いられるHPL Benchmark では、「B300 GPU」は「H200 GPU」の2.1%(約47分の1)の性能に留まりました。
これは「B300 GPU」が生成AIワークロードに特化した高い性能を有している一方で、科学技術計算など計算結果の正確性を求めるユースケースにおいては依然として「H200 GPU」が適している可能性を示唆しています。
【ベンチマークテストの概要と結果】
1. 大規模言語モデル(LLM)の学習ベンチマーク
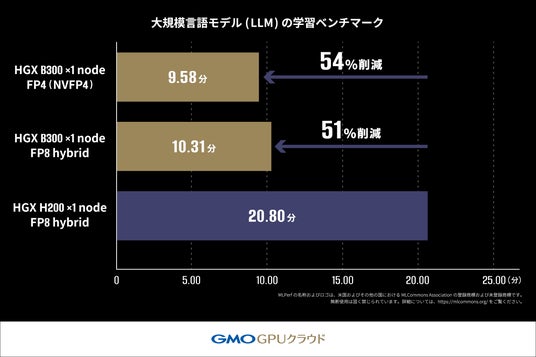
本ベンチマークでは、MLPerf (R) Training v5.1(※1) が規定している Closed Division のルールに従い、Llama2 70B モデルを用いて「B300 GPU」および「H200 GPU」上での LoRA ファインチューニング(※2)にかかる学習時間を測定しました(※3)。
評価指標にはクロスエントロピー損失(※4)を用い、目標値(0.925)に達するまでの時間を測定しています。
このベンチマークにおいて、「H200 GPU」搭載機材では 20.80 分(Unverified)かかっていた学習時間が 「B300 GPU」搭載機材では 10.31 分(Unverified)で完了し、約2倍の速度で処理が完了しました。
さらに、NVIDIA Blackwell アーキテクチャより新たに対応したFP4(※5)を用いた測定ではFP8 hybrid(※6) を使用した学習よりもさらに短い時間で処理が完了しており、FP4の高い演算性能を活かすことにより学習でもその恩恵を受けることができる可能性を示しています【表1】。
【表1:大規模言語モデル(LLM)ベンチマーク時間比較】
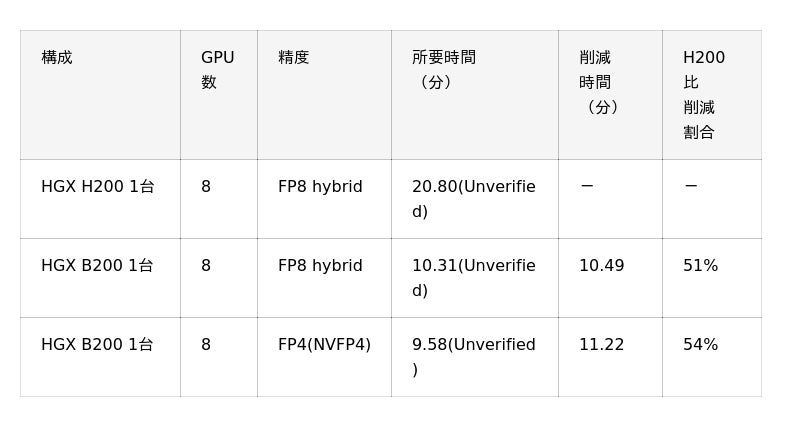
[お詫びと訂正]2026年1月23日(金)18:00
初出時、表1の「構成」に誤記がありました。訂正してお詫び申し上げます。
誤:HGX B200 1台
正:HGX B300 1台
(※1)MLPerf (R)とは、MLCommons Associationが管理する機械学習システムの性能測定における国際的なベンチマーク標準。
MLPerf の名称およびロゴは、米国およびその他の国における MLCommons Association の登録商標および未登録商標です。無断使用は固く禁じられています。詳細については、www.mlcommons.orgをご覧ください。
(※2)LoRAファインチューニングとは、大規模言語モデルを効率的に学習させる手法。
(※3)本稿で記載している結果は 非公式(Unverified)であり、MLCommons Association に提出し、審査・承認を受けた公式結果ではありません。
(※4)クロスエントロピーとは、AIモデルの予測精度を測定する指標。モデルの予測と正解データの差異を数値化したもので、値が小さいほど学習が進み、高精度なモデルであることを示す。
(※5)FP4 (4ビット浮動小数点演算) とは、データを4ビット(従来の半分)で表現する演算方式。メモリ使用量を削減し処理速度を向上させることで、AIモデルの学習・推論を高速化します。NVIDIA Blackwellアーキテクチャから新たに対応した技術。
(※6)FP8 hybridとは、8ビット浮動小数点演算と高精度演算を組み合わせた混合精度学習手法。
2. vLLM bench throughput(※7)による推論ベンチマーク
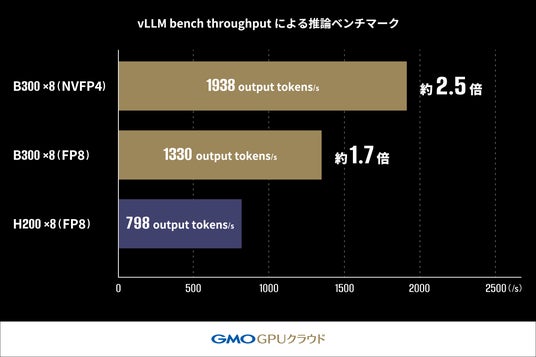
本ベンチマークでは、vLLMのOffline Throughput Benchmark(※8)を用い、Llama-3.1-405B-Instructモデルの推論スループットを測定しました。LLM推論のバッチ処理における「H200 GPU」および「B300 GPU」が1秒あたりに生成できる出力トークン数(output tokens/s)の最大処理能力を比較しています(※9)。評価は1秒あたりの出力トークン数(output tokens/s)を指標としています。このベンチマークにおいて、「H200 GPU」(FP8)構成では798 tokens/sであったスループットが、「B300 GPU」(FP8)構成では、約170%(約1.7倍)の1330 tokens/sまで向上しました。さらに、FP4(NVFP4)を適用した構成では1938 tokens/sを達成し、「H200 GPU」構成に対し約250%(約2.5倍)の性能向上を確認しました。この結果から、FP4の活用が大規模モデルの推論パフォーマンスを向上させるための、有力な手段の一つであることがうかがえます 【表2】。
【表2:大規模言語モデル(LLM)推論スループット比較】
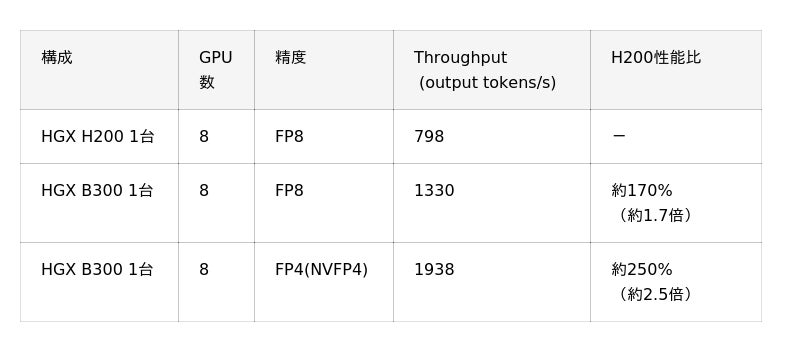
(※7)vLLM bench throughput 大規模言語モデル推論エンジン「vLLM」のベンチマークツール。1秒あたりに生成できるトークン数(スループット)を測定することで、本番環境でのAIサービスの応答性能や処理能力を評価。
(※8)Offline Throughput Benchmarkとは、vLLM bench throughputで実行するベンチマークモードで、バッチ処理における最大スループットを測定するモード。
(※9)計測条件:モデル:Llama-3.1-405B-Instruct, プロンプト数:2048, 入力長:2048 tokens, 出力長:256 tokens。VRAM容量に応じてシーケンス数・バッチあたりの最大トークン数は各構成で調整。
3. HPL Benchmark によるベンチマーク
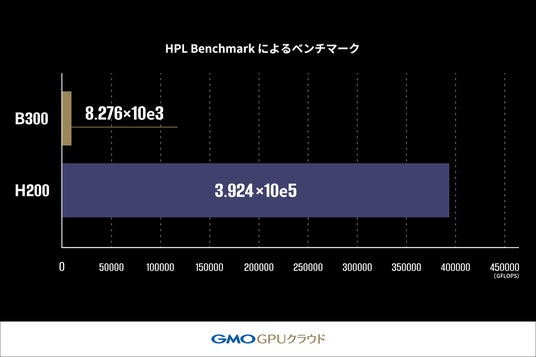
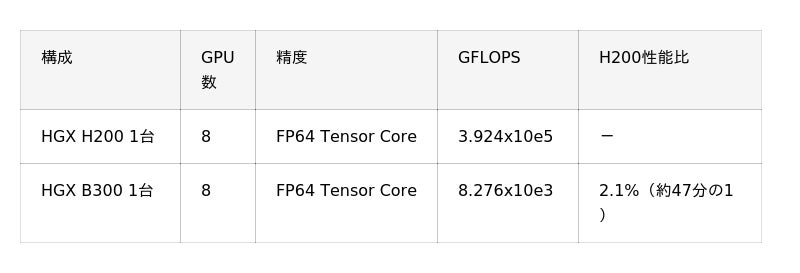
本ベンチマークでは HPL Benchmark(※10)を用いて「B300 GPU」搭載機材および「H200 GPU」搭載機材の LINPACK 性能(※11)を比較しました。HPL Benchmark では浮動小数点演算性能を測定し、1秒間に実行できる演算回数を GFLOPS (10億回の浮動小数点演算/秒)という単位で算出し、ベンチマークのスコアとします。この値が高いほど高性能であることを示します。
その結果、「B300 GPU」搭載機材の性能は「H200 GPU」搭載機材の2.1%(約47分の1)となりました。これは「B300 GPU」がAI ワークロードに最適化された設計であることが要因であると考えられます。科学計算など高精度な演算を必要とする場面では「H200 GPU」が依然として有用であると考えられます。【表3】。
この結果から、「B300 GPU」は低精度演算(FP4/FP8)を用いる生成AIワークロードに特化した設計である一方、高精度演算(FP64)が求められる科学技術計算においては「H200 GPU」が適していることがうかがえます。
これは「B300 GPU」が生成AIに最適な低精度演算(FP4/FP8)に特化している一方、HPL Benchmarkで測定される高精度演算(FP64)は「H200 GPU」の方が優れているためです。したがって、科学技術計算など高精度な数値演算を必要とする場面では「H200 GPU」が有用であると考えられます。
【表3:HPL Benchmark 浮動小数点演算性能比較】
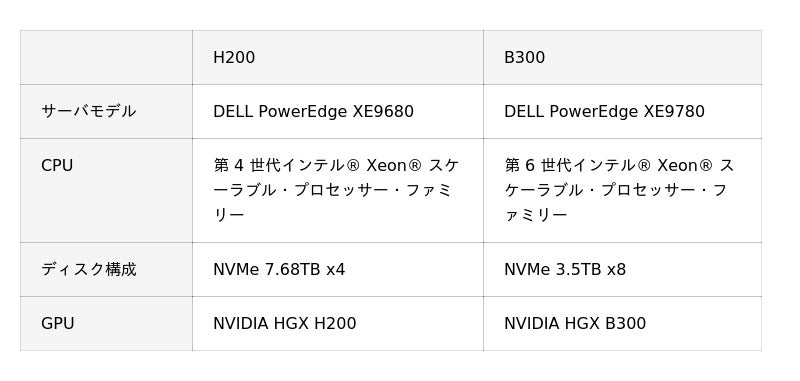
■実施環境
(※10)HPL Benchmarkは スーパーコンピュータの性能評価に用いられる国際標準ベンチマーク。
(※11)LINPACK性能とは、複雑な数式を正確に解く計算能力。わずかな誤差も許されない科学技術計算(気象予測、創薬研究等)での性能を示す指標。スーパーコンピュータの性能評価でも使用されます。
【GMOインターネット インフラ・運用本部 プロジェクト統括チーム
エグゼクティブリード 佐藤嘉昌 コメント】
今回のベンチマーク結果は、当社が用意した環境・条件下での検証結果となりますが、「B300 GPU」と「H200 GPU」の性能特性の違いを示す一つのデータとしてご参考いただけると考えています。「GMO GPUクラウド」は、お客様の開発目的や利用用途に寄り添い、より効率的に計算資源を活用いただけるよう、技術協力を継続的に行い、AI開発環境における技術向上に寄り添ってまいります。このような検証情報の提供を通じて、お客様のGPUクラウドサービスの選択をサポートし、日本のAI産業の発展に貢献してまいります。
【今後の展開】
GMOインターネットは、「GMO GPUクラウド」を通じて、生成AI分野に取り組む企業や研究機関に向け、ワークロード特性に応じて最適なGPUクラウドサービスを選択できる柔軟な計算環境を提供していきます。
今回の性能検証結果を踏まえ、生成AIの学習・推論といったAIワークロードに強みを持つ「B300 GPU」と、高精度な数値計算を必要とする用途に適した「H200 GPU」を、お客様のユースケースに応じて柔軟に組み合わせてご提案いたします。単なるGPUリソースの提供にとどまらず、お客様の開発目的や利用用途に応じた環境のカスタマイズから運用最適化まで、技術面・コスト面の両面で伴走支援を提供いたします。これにより、開発期間の短縮とコスト低減に貢献し、国内AI産業の発展を促進します。
【「GMO GPUクラウド」について】(URL:https://gpucloud.gmo/)
「GMO GPUクラウド」は、NVIDIA H200 Tensor コアGPUを搭載し、国内初となる高速ネットワーク NVIDIA Spectrum-X と高速ストレージを実装しています。
2024年11月に発表された世界のスーパーコンピュータ性能ランキング「TOP500」(※12)においては、世界第37位・国内第6位にランクインし、商用クラウドサービスとしては国内最速クラスの計算基盤を提供しています。さらに、2025年6月には電力効率を競う世界ランキング「Green500」(※13)にて世界第34位・国内第1位を獲得し、高性能と省電力性の両立が国際的に評価されました。加えて、2025年12月にはNVIDIAの次世代GPU「NVIDIA Blackwell Ultra GPU」を搭載した「NVIDIA HGX B300」のクラウドサービス提供を開始しました。(※14)
(※12)「GMO GPUクラウド」世界のスーパーコンピュータランキングTOP500で37位にランクイン(2024年11月時点)
(※13)「GMO GPUクラウド」電力効率を競う世界ランキング「Green500」で世界34位、国内1位を獲得
(※14)「GMO GPUクラウド」「NVIDIA HGX B300」のクラウドサービスを国内最速クラスで提供開始
■過去参考リリース

【サービスに関するお問い合わせ先】
●GMOインターネット株式会社
ドメイン・クラウド事業本部 GPUクラウド事業部
お問い合わせ:
https://gpucloud.gmo/form/
【GMOインターネット株式会社】(URL:https://internet.gmo/)
会社名 GMOインターネット株式会社 (東証プライム市場 証券コード:4784)
所在地 東京都渋谷区桜丘町26番1号 セルリアンタワー
代表者 代表取締役 社長執行役員 伊藤 正
事業内容 ■インターネットインフラ事業
ドメイン登録・販売(レジストラ)事業
クラウド・レンタルサーバー(ホスティング)事業
インターネット接続(プロバイダー)事業
■インターネット広告・メディア事業
資本金 5億円
【GMOインターネットグループ株式会社】(URL:https://group.gmo/)
会社名 GMOインターネットグループ株式会社 (東証プライム市場 証券コード:9449)
所在地 東京都渋谷区桜丘町26番1号 セルリアンタワー
代表者 代表取締役グループ代表 熊谷 正寿
事業内容 持株会社(グループ経営機能)
■グループの事業内容
インターネットインフラ事業
インターネットセキュリティ事業
インターネット広告・メディア事業
インターネット金融事業
暗号資産事業
資本金 50億円
Copyright (C) 2026 GMO Internet, Inc. All Rights Reserved.
本記事はアフィリエイトプログラムによる収益を得ている場合があります




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























