これならローカルLLMが現実解に AI開発の救世主あらわる
AI開発にデスクトップPCという選択肢 RAG博士がAI TOPに未来を感じた

AIトレーニングに最適化された妥協のないハードウェア
冒頭に、「Train Your Own AI On Your Desk」を謳うAI TOPの製品コンセプトとハードウェアについて説明してくれたのは、ギガバイトの黃俊忠氏だ。

AI TOPのハードウェアについて説明してくれたギガバイトの黃俊忠氏
まず前提として、AI TOPがフォーカスしているのは、AIベンダーが扱う兆規模パラメーターではなく、億規模のパラメーターのモデルチューニングだという。「最大40~50億パラメーターのLLMのチューニングにフォーカスしている」(黃氏)とのこと。セキュリティ要件の高いカスタムデータセット、ローカルファインチューニング、RAG、ローカルインターフェイスなどでの改善を繰り返し行なう際にAI TOPが最適だという。
ハードウェア面でのコアになるのは、もちろんマザーボード。専用マザーボードである「TRX 50 AI TOP」では、Ryzen 7000/9000シリーズや、Core Ultra 200Sシリーズといったコンシューマー向けCPUを利用でき、最大2TBのDDRメモリ、最大4基のRAID化されたSSDに対応。サージプロテクションを備えた10Gbps LAN×2を備え、複数のAI TOPマシンでのクラスタリングでの動作も可能となっている。また、最大6基のSSD、40GbpsのThunderbolt4×2を備えた「W790」も用意されている。RAIDのエンクロージャーと接続することで、AIトレーニングに必要なデータも高速にやりとりできる。

グラフィックカード4枚挿しが可能なTRX50 AI TOP
最大の特徴はマルチGPUのサポートだ。両者ともPCIe 5.0のスロット×4を備えており、グラフィックカードを最大4枚まで搭載できる。これを実現したのは、複数枚のグラフィックカードを前提とした優れた冷却機構のおかげ。「通常のグラフィックカードは、大型ファンを搭載しており、これでスロットを消費してしまうが、AI TOPのグラフィックカードであれば2スロットで済む」と黃氏は語る。
とはいえ、通常のデスクトップPCに搭載できるGPUのVRAMは24~32GB程度に過ぎない。しかし、AI TOPではパートナーであるPHISONのSSDを用いることで、メモリのキャパシティを拡張することができ、デスクトップPCでのAIトレーニングを現実解に近づける。多少速度は落ちるが、モデルの分割ロードなどの技法により、より大きなモデルも扱えるメリットは大きいだろう。「通常のPCでは、ワットあたり0.34トークンしか処理できない。しかし、メモリをSSDで拡張できるAI TOPではワットあたり2.63トークンまでの処理が可能だ。これにより、規模の大きなAIモデルを扱うことができる」と黃氏はアピールする。SSDのシーケンシャル速度も読み込みで7200MB/s、書き込みで6500MB/sを実現しており、通常の5倍の速度を誇るという。
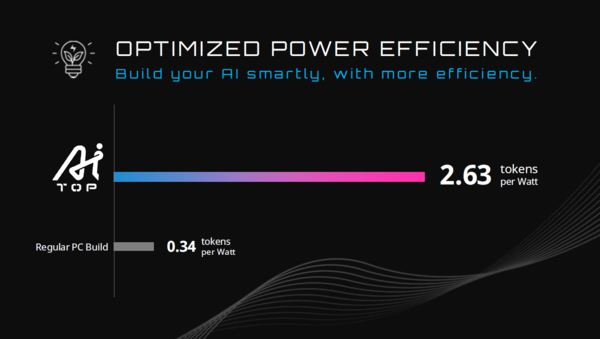
AI TOPではワットあたり2.63トークンの処理が可能
また、信頼性の高いAIトレーニングのためのパーツの耐久性にも配慮されているほか、センサーによって動作状況はつねにモニタリングされているという。「AIのトレーニングではすさまじい回数の書き込みが行なわれる。50億パラメーターのレベルで書き込みを行なうと、SSDは数ヶ月で使い物にならなくなる。しかし、耐久性の高いAI TOPのSSDは5年以上も動作する」(黃氏)とのこと。電源もサーバーグレードの耐久性を誇り、4枚のグラフィックカードまでサポート。80 Plus Platinumの認証を得ているため、電力効率も92~93%と極めて高い。家庭用電源でも利用できる点もローカルLLMの実現には大きなポイントだ。
このようにAI TOPは、マザーボード、グラフィックカード、電源まで含めて、AIトレーニングには最適なスペックを実現している。しかもモデルサイズに合わせてアップグレード可能。どの製品も10~20万円台とかなり高価だが、AI開発のためには格安と言えるプレミアムハードウェアなのだ(関連記事:GIGABYTE AI TOPマザーボードはなぜ超高額なのか? AI研究者にはむしろ格安と言える製品だった)。
GUI環境でファインチューニングを実現 AI TOP Utilityのデモを披露
こうしたAIトレーニングに最適化されたAI TOPのハードウェア上で動作するのが、AI専用ソフトウェアの「AI TOP Utility」である。AI TOPでは、AI TOP Utilityの永久ライセンスが付与されており、日々のAIトレーニングを効率化する。AI TOPの魅力の1つとも言えるこのAI TOP Utilityについてはギガバイトの黎光線氏と黃偉豪氏が説明してくれた。

AI TOP Utilityについてデモを交えて説明してくれたギガバイトの黎光線氏(左)と黃偉豪氏(右)
AI TOP Utilityのダッシュボードでは、CPUやVRAM/DRAM、SSDなどのハードウェアのステータスがグラフ表示されるほか、トレーニングの進捗やロス、ログなども一望できるようになっている。さっそくファインチューニングのデモを見せてもらおう。
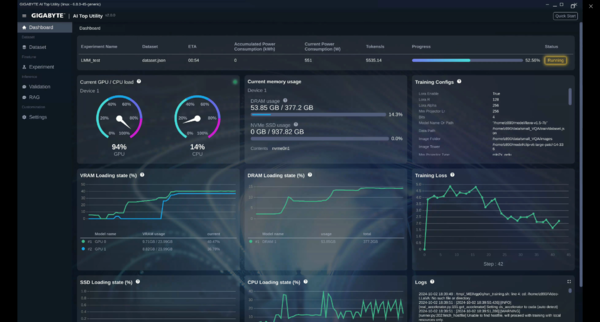
ハードウェアの動作やチューニングの様子を一望できる最新のAI TOP Utility 2.0
ファインチューニングはまずデータセットの生成からスタートする。テキストデータをセットすると、言語やフィールド、ハードウェアの状態から最適なLLMを選択してくれる。400以上を超えるオープンソースのLLMから利用でき、Llama 2/3.2(Meta)やGemma/BERT(Google)、GPT-2(OpenAI)のほか、話題のDeepSeekやQwen(Alibaba)も選択できる。これらはすべてギガバイトのAI研究所でテスト済みだという。

ギガバイトでテスト済みのオープンソースLLM
LLMを選択したら、モデルをダウンロード。先ほど生成したJSON形式のデータセットを指定できるほか、画像や動画も選択できる。あとは、VRAM、DRAM、SSDなどのオフロード設定を行ないトレーニングの実験を開始。トレーニングの状況はダッシュボードで確認できる。ちなみにAI TOP2台をThunderboltやEthernetで相互接続したマルチモードでの動作も可能で、1台に比べて最大1.8倍の高速化も可能になっている。
トレーニングが終了したら、さっそくバリデーション(検証)のフェーズ。ここでもAI TOP Utility上からチャット形式で精度を確認できる。テキストのみならず、画像や動画のチェックもOK。そのままRAG向けのデータセットを構築し、ベクトルデータベースに格納することも可能だ。

マルチモーダル対応なので、テキストから画像生成も可能
AI TOPについてのプレゼンを聞いた野村氏は、データクレンジングの精度についても質問を寄せた。現実世界では、データはかなり粗雑で、扱いにくいものも多い。これをどの程度、自動的にクレンジングしてくれるか、気になったようだ。
これに対しては4000文字のPDFファイルでデモを披露する。必要なテキストと画像を抽出し、不要なテキストや記号を除去。次のバージョンでは、GUIで操作の履歴を見ながら処理をチェックすることが可能になるそうだ。また、正確さ(Accuracy)に関しての表示に関しても、現在のバージョンでは実装されていないが、今後のバージョンアップで搭載される予定。ギガバイトの2人から強調されたのはAI TOP Utilityが日々バージョンアップされ、強化されているといのことだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります