




モルフォ
新規コーパス開拓・整備を通じて国産の大規模言語モデル(LLM)構築に貢献
モルフォグループにおいてAIの事業化を担う、株式会社モルフォAIソリューションズ(所在地:東京都千代田区、代表取締役:神田武、以下 モルフォAIS)は、日本語LLM(Large Language Model:大規模言語モデル)の学習データを生成するための、AI-OCR(Optical Character Recognition:光学文字認識)出力サービスを2023年から提供しています。
このたび、大学共同利用機関法人 情報・システム研究機構 国立情報学研究所 (所在地:東京都千代田区、所長:黒橋 禎夫、以下 国立情報学研究所) より、日本語学術論文に特化したAI-OCRの開発を受託しましたのでご報告します。当該事業を通じて、国立情報学研究所が推進する日本語に強い国産LLMの開発に貢献していきます。

開発の概要
国立情報学研究所は、2024年4月1日、文部科学省の「生成AIモデルの透明性・信頼性の確保に向けた研究開発拠点形成」事業を実施する拠点として、新たにLLMの研究開発を行う「大規模言語モデル研究開発センター(以下、LLM研究開発センター)」を開設しました(※1)。LLM研究開発センターは、1750億パラメータ規模の国産LLM構築に向けて、コーパス整備、計算環境整備、評価用ベンチマーク作成などを行うとともに研究開発用のLLM構築を進めています。
LLM研究開発センターでは、日本語学術論文PDFからのテキストデータ抽出を進めています。学術論文 PDF からの本文抽出は、レイアウト(テキストフロー)解析、構造解析(本文領域推定)などの前処理を要します。これらの機能を備えた各種ツールは英語論文を前提にチューニングされているものが多く、特定の論文誌に限定されない汎用かつ実用的に日本語論文の本文抽出が可能なものを用意する必要がありました。
モルフォAISは、LLM研究開発センターからの委託事業として、日本語学術論文に特有のレイアウトの認識や、本文領域のテキスト抽出を可能とするAI-OCRの機能開発を行います。これにより、国産LLM構築のために必要となる良質かつ大量の日本語のテキストデータの生成に貢献していきます。
モルフォAISが提供するOCRテキスト出力サービス
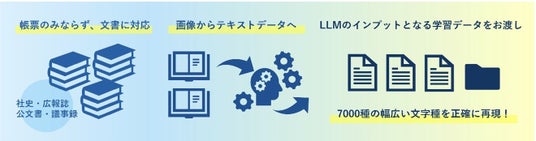
画像として保存された文書のデジタル化のためにはOCRが必要となりますが、市販OCRの多くは請求書や領収書といった「帳票向け」に開発されたものです。日本語の文書は多様なレイアウト(縦書き、横書き、多段組等)、多様な文字種が混在するため、市販のOCRでは読み順を含めた正確な日本語の抽出が難しいという課題があります。
モルフォAISの提供するAI-OCR出力サービスは、上記の市販OCRが苦手としている文章の読み順まで含めた高精度のテキスト生成を行います。これによって、組織が保有するスキャン画像データから多様かつ正確な日本語を生成することで、日本語LLMの学習データの作成を支援します。
サービス内容、特徴、実績
<サービス内容>
既存文書(社史・広報誌・公文書・議事録等)のデジタル化とLLM学習データへの変換
<特徴>
- 文書に対応したAI-OCR
- - LLMに入力する際に重要な読み順まで再現
- - 文字種は約7000種類で、複雑な漢字も読み取り可能
- 画像(JPEG,PDF,PNG等)が含まれている雑多な文書を、テキスト(様々なフォーマット)で出力可能
<実績>
様々な機関向けにテキスト生成を実施済み
(沖縄県豊見城市/ボローニャ大学/順天堂大学/滋賀県立図書館 等多数)
お申込み・問い合わせ窓口
https://frog-ai-ocr.morphoai.com/
こちらより無償トライアル頂く事が可能です。
FROG AI-OCR紹介
FROG AI-OCRは、お手軽にOCR適用業務が行えるようNDLOCRの高精度なOCR処理に加えて、校正・テキスト出力機能も1つのパッケージとしてご提供しております。機能は全てクラウドで利用可能で、出力テキストの確認・修正作業を効率良く行うことが可能となります。FROG AI-OCRは、国立国会図書館がCC BYのライセンスで公開しているNDLOCR(https://github.com/ndl-lab/ndlocr_cli)をコアエンジンとして利用しています。
注釈
※1:国立情報学研究所に「大規模言語モデル研究開発センター」新設
~国産LLMを構築し、生成AIモデルの透明性・信頼性を確保する研究開発を加速~
https://www.nii.ac.jp/news/release/2024/0401.html
関連プレスリリース
2022年6月14日
世界初(注1)近代書籍対応の市販AI-OCRソフト「FROG AI-OCR」新発売
~デジタルアーカイブ事業・読書バリアフリー法対応に最適、図書館OCRの決定版~
https://www.morphoinc.com/news/20220614-jpr-mais_frog_aiocr
2023年12月19日
モルフォAIソリューションズ、LLM向けの日本語データセット生成サービスを提供開始
~文書画像からAI-OCRでテキストデータ作成、良質な日本語LLM構築に貢献~
https://www.morphoinc.com/news/20231219-jpr-mais_ocr
株式会社モルフォAIソリューションズについて
モルフォAIソリューションズは、AI(人工知能)の事業化に取り組む企業です。行政、電力、交通、製造といった社会インフラの領域で、AI-OCR、AIカメラをはじめとする最先端のAI技術の導入と実運用を推進しております。
- 所在地:東京都千代田区神田錦町2−2−1KANDA SQUARE 11階 WeWork内
- 代表者:代表取締役 神田 武
- 設立:2019年12月
- 事業内容:AIコンサルティング、システムインテグレーション、SW・HW販売など
- ホームページ:https://www.morphoai.com
株式会社モルフォについて
モルフォは「画像処理/AI(人工知能)」の研究開発型企業です。高度な画像処理技術を組み込みソフトウェアとして、国内外のスマートフォン、半導体メーカを中心にグローバルに展開しています。また、カメラで捉えた画像情報をエッジデバイスやクラウドで解析する、AIを駆使した画像認識技術を車載や産業IoT分野へ提供し、様々なイノベーションを先進のイメージング・テクノロジーで実現しています。
- 所在地:東京都千代田区神田錦町 2-2-1 KANDA SQUARE 11階WeWork内
- 代表者:代表取締役社長 平賀 督基(まさき)、【博士(理学)】
- 設立:2004年5月26日
- 資本金:1,783,958千円(2023年10月31日現在)
- 事業内容:画像処理およびAI(人工知能)技術の研究・製品開発。スマートフォン・半導体・車載・産業IoT向けソフトウェア事業をグローバルに展開。
- ホームページ:https://www.morphoinc.com/
- Facebook:https://www.facebook.com/morphoinc
- X:https://twitter.com/morpho_inc
お問合せ先
株式会社モルフォAIソリューションズ 神田
メール:contact@morphoai.com

")


 FMVWK3E155_AZ")


















")













/3.1(Gen 1)/3.0/2.0 RUF3-K64GA-BK/N")

+380 5色マルチパック BCI-381+380/5MP 長さ:5.3cm 幅:13.9cm 高さ:10.75cm")
 扉付タップラン 電源タップ 延長コード 125V 3m 3個口 ホワイト WBT-N3030B(W)")
 2025 用/iPad 第10世代 2022 用 10.9インチ フイルム ガイド枠付き 強化 ガラス 保護フイルム あいぱっど 11世代/10世代 対応 NTB22I574 1枚")
/iPad 各種対応(シルバー 0.9m)")



