





楽天は3月21日、日本語に最適化した高性能の大規模言語モデル(LLM)「Rakuten AI 7B」など3種を発表した。
いずれも仏Mistral AIの「Mistral-7B-v0.1」をベースに開発されており、パラメーター数は70億。商用利用可能な「Apache 2.0」ライセンスでHuggingFaceからダウンロード可能。
高品質なデータで事前学習
発表されたのは基盤モデルの「Mistral-7B-v0.1」のほか、同モデルを元にしたインストラクションチューニング済モデル「Rakuten AI 7B Instruct」と、それをさらにファインチューニングしたチャットモデル「Rakuten AI 7B Chat」の3種類。
いずれもMistral AIのオープンモデル「Mistral-7B-v0.1」をベースに、大規模な日本語と英語のデータを用いた事前学習を繰り返すことで開発された。
事前学習には、インターネット上に存在する膨大な日本語と英語のデータを使用しており、独自のフィルタリング機能によるデータの選別・抽出と、関連情報をメタデータとして付与するアノテーション作業によってデータの質が向上されている。
また、日本語に最適化された独自の形態素解析器(プロンプトをトークン単位に分割する仕組)を使用することで、従来よりテキスト処理の効率化も実現したという。
ベンチマークではオープンな日本語LLMのトップに
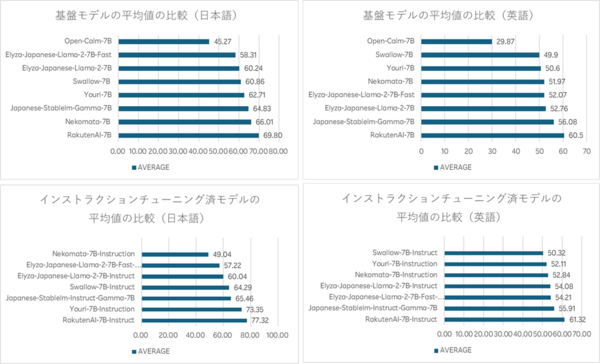
LLM用ベンチマーク「LM Evaluation Harness」を使用した評価では、日本語で基本モデルが平均69.8ポイント、チューニング済モデルが平均77.3ポイントを、英語で基本モデルが平均60.5ポイント、チューニング済モデルが平均61.3ポイントを獲得し、オープンな日本語LLMの中では最高水準の結果を示した。
同社CDO(Chief Data Officer)のティン・ツァイ氏は、「コストや品質、性能の面で様々な顧客ニーズを解決するための最適なツールが提供可能」とし、今後もLLMの開発を通じて得た知見をオープンソースコミュニティと共有していくという考えを示している。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















