




個別の変更点を詳しく見ていく
まずは「1」だが、これはWin32のNLS(National Language Support)関連のAPIにおける問題点。ただし、この構造体や関連のAPIなどを使っていないアプリケーションは無関係である。構造体とは、APIなどに引き渡すデータ構造で、日時を表現したこの構造体を使って、ローカル時間などを得るために利用するが、これらはすべて廃止予定であり、かつWindows Vistaから実装されたAPIなので、あまり影響はないと思われる。ただしマイクロソフトのWindows関連のソフトウェアで使われている確率が高いと考えられる。
また「4つ以上の日本語の元号を処理できない」とは、マイクロソフトが以前言っていた「和暦 (われき) がハードコードされたモジュール」(新元号に関するマイクロソフト製品別対応、https://www.microsoft.com/ja-jp/mscorp/newera/default.aspx)の部分だと考えられる(ほかにもあるかもだが)。この構造体では年号を数字で指定し、これをAPI側が解釈するのだが、API内部で元号はレジストリを読むのではなく、1~4の数字をそのまま明治、大正、昭和、平成と解釈するようになっていたのであろう。つまり、令和を表す5を指定しても、解釈できない作りになっていたのだと思われる。
「2」は、本連載でも以前紹介したレジストリキー「HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\Calendars\Japanese\Eras」のことである。
「3」は、アップデートをかける前にいろいろな条件で試してみたが、現象を発生させることができなかった。DateTimePickerは、XAMLコントロールの1つで、WPFやUWPで使われるGUI部品(コントロール)。カレンダーコントロールなどを使って、日時をユーザーに指定してもらうためのものだ。カレンダーコントロールの和暦対応がうまく動いていなかったのだと思われる。
「4」は、5月1日になって元号が切り替わる瞬間の動作の問題のようだ。Windowsの標準アプリを含め、一般にアプリケーションでは、起動時に読み込んだシステムの設定状態のうち、頻繁に変わりそうもないものについては、動作中の設定値の変化を調べないことが多い。元号に関しても、数十年に一回という頻度なので、普通は起動時に設定を読めば、問題ないはず。ただその数十年に一回で問題が発生するのかもしれない。次回の改元のときに正しく動作することを期待しよう。
「5」は、「令和」合字のフォントパターンである。ざっと、標準添付の日本語フォントで合字をだしてみたが、ちゃんと定義されているようだ。全部、代替フォントなのかとおもったら、一部はちゃんとデザインが違う。

標準の日本語フォントと令和合字の表示。よく見ると令のひとやねの部分やその下の横棒の長さ、和のくちへんなどに違いが見える
「6」も合字関連で、MS-IMEが「れいわ」の読みで正しく合字を候補として表示するかどうか、IMEパッドの文字コード表で令和合字を表示できるといったことだ。なお、Windows付属の文字コード表でも正しく表示されていた。
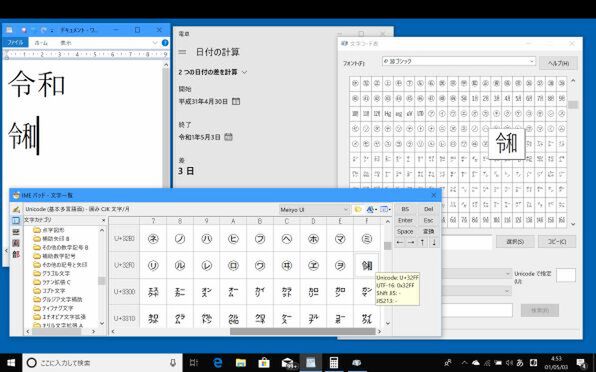
MS-IMEのIMEパッドや文字コードアプリなどは正しく令和合字とコードを表示できる
「7」も、筆者の環境では現象を確認できなかった。しかし、ここも「カレンダーコントロール」を使っているようなので、「3」と同じ原因の問題であろう。
「8」の「代替フォント」(フォールバックフォント)とは、指定されたフォントに文字の形(グリフ)が定義されていない場合に、他のフォントファイルから持ってきて代用するグリフのことだ。Windowsのフォントファイルには、すべての文字のグリフが定義されているわけではなく、一部の文字のグリフしか含まれていない。
たとえば、絵文字はすべてのフォントファイルに含まれているわけではないが、Windowsでは、どのフォントを指定しても、絵文字を表示させることができる。これが「代替フォント」という機能だ。今回のパッチでは、令和合字を含まないフォントファイルのために、令和合字を代替フォントとして登録したのだと思われる。
「9」は、簡単にいうと「令和」を「れいわ」として読み上げることだ。パッチ適用前には「令和」は「よしかず」(誰かの名前?)と読み上げていた。パッチを適用するとちゃんと「れいわ」と読み上げてくれる。
このほか、ちょっと気になったのが、令和合字のUnicode正規化処理だ。令和パッチのあと検証してみたが、令和合字は正規化できなかった。
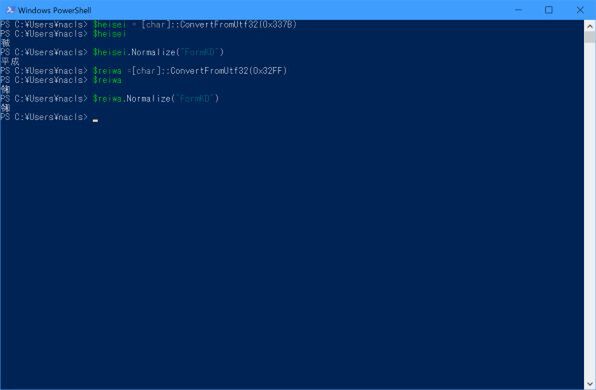
パッチを当てても令和合字は「令和」の2文字には正規化できなかった
.NET Frameworkには、Unicode文字を正規化する関数として文字列オブジェクトに「Normalize」というメソッドがある。マイクロソフトのドキュメントによれば、「.NETは、Unicode規格で定義されている4つの正規化形式(C、D、KC、およびKD)をサポートしています(.NET supports the four normalization forms (C, D, KC, and KD) that are defined by the Unicode standard)」と以下のページに記載がある。
●String.Normalize Method
https://docs.microsoft.com/en-us/dotnet/api/system.string.normalize?view=netframework-4.8
つまり、Normalizeメソッドは、Unicodeのルール通りに正規化するわけだ。しかし、今回の令和パッチでは、この動作を確認することはできなかった。以前この連載で示したように、平成合字は「平成」の2文字に正規化される。これについてはマイクロソフトのサイトに以下の記述があった。
漢字による元号のフルネームは、漢字合字による元号の名称に正規化できます。その逆も同様です。たとえば、平成の元号を表現する2文字はそれに相当する「平成合字」に変換されます。その逆も同様です。ただし、マイクロソフトは、新元号の正規化機能をサポートするための更新プログラムをリリースしません。
漢字による元号のフル ネームと漢字合字による元号の名称は、日本の文化固有の比較を示す場合でも、文字列の比較時に異なる文字列として処理されます。 これは仕様によるものであり、マイクロソフトは、日本の新元号に関するこの動作を変更しません。
●日本の元号変更に関する Windows の更新プログラムについて - KB4469068
https://support.microsoft.com/ja-jp/help/4469068/summary-of-new-japanese-era-updates-kb4469068
これをそのまま受け取るとすると、マイクロソフトは、令和合字を「令和」の2文字にする「正規化」をサポートしないことになる。実際の開発者に話を聞くに、そもそもNormalizeメソッドは以前から、Unicode正規化にちゃんと対応していないので信用してないとのこと。
となると、上記の説明は「WindowsはUnicode正規化にはもう対応しないよ」という、事実上の公式宣言なのか。だったら、ドキュメントを書き換えておいてほしかった(時間を無駄にしました)。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第519回
PC
「セキュアブート」に「TPM」に「カーネルDMA保護」、Windowsのセキュリティを整理 -
第518回
PC
WindowsにおけるUAC(ユーザーアカウント制御)とは何? 設定は変えない方がいい? -
第517回
PC
Windows 11の付箋アプリはWindowsだけでなく、スマホなどとも共有できる -
第516回
PC
今年のWindows 11には26H2以外に「26H1」がある!? 新種のCPUでのAI対応の可能性 -
第515回
PC
そもそも1キロバイトって何バイトなの? -
第514回
PC
Windows用のPowerToysのいくつかの機能がコマンドラインで制御できるようになった -
第513回
PC
Gmailで外部メール受信不可に! サポートが終わるPOPってそもそも何? -
第512回
PC
WindowsのPowerShellにおけるワイルドカード -
第511回
PC
TFS/ReFS/FAT/FAT32/exFAT/UDF、Windows 11で扱えるファイルシステムを整理する -
第510回
PC
PowerShellの「共通パラメーター」を理解する -
第509回
PC
Windowsにも実装された、生成AIと他のシステムを接続するためのプロトコル「MCP」とは何か? - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




































