検索エンジンによるマーケティング(SEO)はROIが高く、正しく運用すればオーガニック検索からの良質なトラフィックを得られる有用なビジネスツールです。しかしキーワードやリンク以上にテクニカルな要素もたくさんあり、注意を怠ると収益のチャンスを逃します。
この記事ではテクニカルなSEOにおける5つの落とし穴を紹介します。どれもはまりがちなものです。
過剰なRobots.txtファイル
robots.txtファイルは、Googleのクローラーが適切にインデックスを作成できるSEOの重要なツールです。過去の記事で紹介したとおり、検索エンジンのインデックスの対象外にしたほうがいいページやフォルダーもあり不可欠なファイルが、robots.txtファイルのエラーがSEOに関する問題を頻繁に引き起こす場合もあります。
Webサイトの移行でサーバー全体に対するアクセスを制限して重複する内容を移行すると、Webサイト全体がインデックスから外れてしまうことがあります。移行後にサイトのトラフィックが伸びないときは 、robots.txtファイルが下記のようになっていないことを確認してください。
User-agent: *
Disallow: /これでは、クローラーがWebサイトにアクセスできません。
robots.txtにクロールを許可する詳細なコマンドを書きます。次のようにDisallowの行には具体的なページやフォルダを指定します。
User-agent: *
Disallow: /folder/copypage1.html
Disallow: /folder/duplicatepages/
Disallow: *.ppt$Webサイトの移行が目的でrobots.txtファイルを作成したら、移行完了後にボットがクロールできるようにしてください。
不用なnoindexタグ
meta robotsタグはrobots.txtファイルとセットで使います。robots.txtではクローラーが外部サイトからリンクをたどってアクセスすることを制限できないため、対象外にしたいページがインデックスされてしまうことがあります。robots.txtでアクセスを制限するページはmeta robotsタグでも制限すべきです。
meta robots noindexタグ(noindexタグ)にインデックスしたくないページを加えます。ページの<head>にシンプルなタグを加えるだけです。
<meta name="robots” content=”noindex”>meta robots noindexタグでページをインデックスさせない手法はよく使います。意図せずページがインデックスされない場合(Googleのsite: 演算子で確認できます)は、meta robots noindexタグを確認してください。
site: 演算子でインデックスに登録されているページ数を確認して実際のページ数より大幅に少なければ、Webサイトをクロールしてみます。WooRankのWebサイトクロール機能で自分のサイトをクロールしてからINDEXINGをクリックすると、meta robotsタグでアクセスを制限しているページが一覧で表示されます。
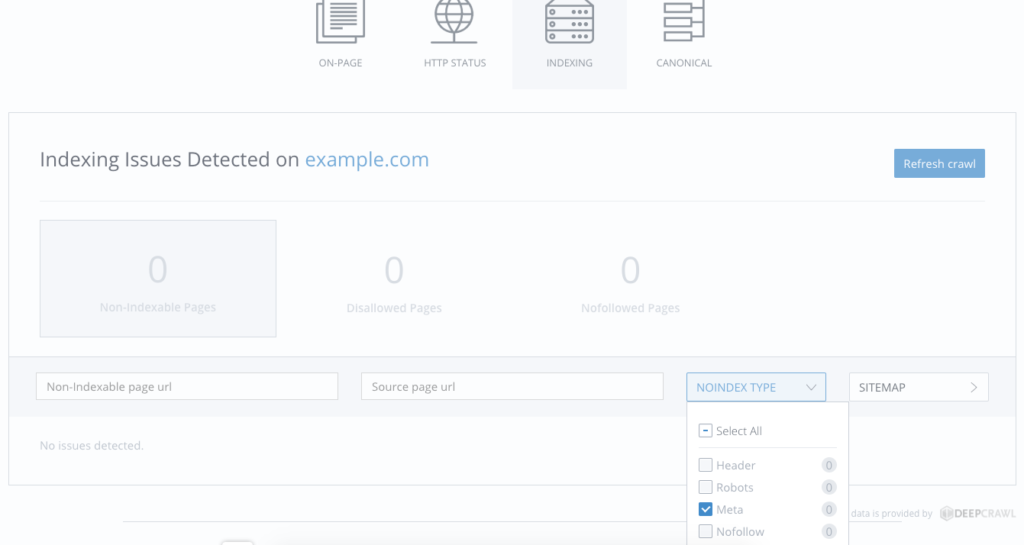
これでmeta robotsの問題が解決しました。
リダイレクトが最適化されていない
301リダイレクトをどうしても避けられないことがあります。301(新しい302を含む)はリンクジュースやオーソリティ、ランキングパワーを維持したままページを移動できますが、実装のミスや設定後に解除を忘れるユーザーエクスペリエンスとSEOを損ねてしまいます。
301リダイレクトがSEOを損なうパターンを4つ紹介します。
リダイレクトチェーン
www.example.com/search-engine-optimization のページを www.example.com/SEO へ移行し、さらに数カ月後www.example.com/marketing/SEOへ移行したとします。
これでリダイレクトチェーンが発生しました。
リダイレクトチェーンは、あるURLのリンクがほかのURLへリダイレクトし、そのURLが3番目のURL(4番目、5番目と続く)にリダイレクトしている状態です。何回もページを移行したときに起こります。
すべての3xx系リダイレクトはリンククオリティを損ないませんが、リダイレクトのたびにページを読み込む時間が増えるので、リダイレクトの積み重ねは避けるべきです。ミリ秒にこだわりすぎているように思えるかもしれませんが、0.1秒単位の遅れがコンバージョンに影響を及ぼすことを考えると、こだわる価値があります。リダイレクトを2、3個つなげると、最終ページが表示されるまでにユーザーを2、3秒待たせることになります。
さらに、リダイレクトチェーンは直帰率も高めます。
そこでクローラーを使ってリダイレクトチェーンを探します。Screaming Frog SEO Spiderにはリダイレクトチェーンを検出してレポートで表示する便利な機能があります。このレポートには対処不可能な外部リダイレクトチェーンも含まれます。
内部リンクのリダイレクト
リダイレクトするURLに被リンクをはられることは防ぎにくいですが、コントロール可能な内部リンクに3xx系のリダイレクトを使うのは、読み込み時間を必要以上に長くするので避けましょう。
リダイレクトしている内部リンクを調べるには、Google Search Consoleにアクセスして「検索トラフィック」の「内部リンク」にアクセスし、ダウンロードしてください。
Excelのconcatenate関数を使ってドメイン名をURLの前に挿入して、URLをクローラーにコピーペーストすれば、3xx系のステータスを返す内部リンクを取得できます。これで自分のサイト内でリダイレクトしているリンクを一覧で確認できます。
見つけたリンクを新しいURLに更新すれば修正完了です。
Canonical URLのリダイレクト
canonical URLとは、Webサイトのcanonに従った正式なURLのことです。そのため、canonicalタグにリダイレクトするURLを設定することは絶対に避けてください。
検索エンジンはcanonicaタグに従ってページのランキング属性をひも付けます。canonicaタグで301リダイレクトをすると、クローラーは2ステップを踏んでリンクにたどり着きます。リダイレクトチェーンさせるようなものです。
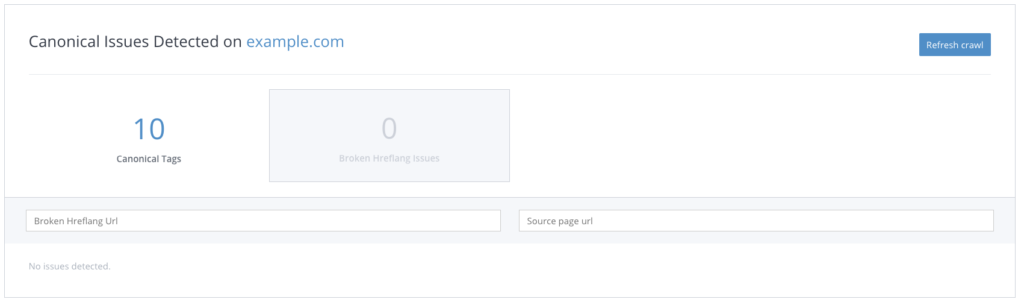
自分のWebサイトをクロールしてcanonicalタグに設定されているURLの一覧を作り、3xx系のステータスを返すURLを探します。canonicalタグを更新(場合によってはサーバーを更新)して、リダイレクトしないURLをcanonicalタグに設定します。
Canonical URLのミスマッチ
canonical URLの不一致はcanonical URLのリダイレクトと同様にSEOを損なうテクニカルなエラーです。canonicalの不一致、またはcanonicalのミスマッチとは、あるページのcanonicalタグのURLがほかのページで使われていてcanonical URLと一致していないことです。
おもに次の2つのパターンがあります。
- サイトマップミスマッチ:canonical タグのリンクがサイトマップのURLと一致していない場合に起こる
- 相対リンク:canonicalタグで検索エンジンは絶対リンクしか認識しない。ファイル名やフォルダ名、パスを使うだけでは不十分だ
canonicalタグはコンテンツが重複しているときに正しいページへリンクジュースを集約する重要なツールです。URLが一致していないと全体の戦略が崩れ、検索エンジンに重複したページがたくさん存在するように見えて(サイトのサイズに比べて)しまいます。さらに、リンクの価値の大部分が単一ページだけに集まってしまうのです。
hreflangのリターンタグのエラー
hreflangタグは検索エンジンやほかのWebクローラーに応じてページを提示します。また特定の国のユーザーを対象にしたページであると示すためにも使われます。多言語のWebサイトではhreflangタグをページに埋め込みます(もしまだなら埋め込むべきです)。
hreflangに関してよくあるテクニカルなエラーは「リターンタグ」です。このエラーはページAにはページBを参照するhreflangタグがあるのに、ページBにページAを参照するhreflangタグがないときに起こります。
ページAは以下の通りです。
<link rel="alternate” hreflang=”en” href=”https://www.example.com/page-A”>
<link rel="alternate” hreflang=”es” href=”https://www.example.com/page-B”>ページBには次のタグしかありません。
<link rel="alternate” hreflang=”es” href=”https://www.example.com/page-B”>hreflangは、すべてのページにほかのバージョンへの参照を埋め込む必要があります。またページ自身の参照も必要です。自身への参照の不足がhreflangのリターンタグエラーのもっともよくある原因でしょう。
リターンタグエラーを起こしているhreflangタグは、Google Search Consoleの検索トラフィックの下のインターナショナル ターゲティングで確認できます。

WooRankのSite Crawlのエラーでも、hreflangのリターンタグエラーやCanonical URLエラーを検出できます。
最後に
紹介した5つのSEOテクニカルエラーを解決してもWebサイトがGoogle検索のトップに表示されません。それにはたくさんのページ内とページ外のSEOが必要です。しかし、エラーを検出して修正すれば、GoogleのクローラーがWebサイトを正確にインデックスします。これがテクニカルSEOの最終ゴールです。
※本記事はWooRankのSEOシリーズの1つです。SitePointでの記事公開に協力してくれたパートナーへのサポートに感謝します。
(原文:5 Technical SEO Traps to Dodge)
[翻訳:内藤 夏樹/編集:Livit]
本記事はアフィリエイトプログラムによる収益を得ている場合があります