機田ゆん
筆者は、オリジナルキャラクターを持っている。機田ゆんという。
通常、イラストレーターさんにキャラクターデザインを渡していろんな構図の機田ゆんのイラストを描いてもらっている。
常々、生成AIでキャラクターデザインを反映させてイラストを生成するにはどうしたらいいのだろうかと考えていた。
機田ゆんの髪型はボブに襟足の長い、くらげのような髪型をしている。
ChatGPTの画像生成AI「DALL・E」を使って言葉(テキスト)で試してみたところ、この髪型を再現して生成させることができなかった。

くらげ……
ChatGPTにキャラクターの画像を読み込ませて、言語化してもらって、その言葉を使ってまた生成するのをやってみても、無理らしい。
言葉でキャラクターデザインを伝えるのは無理そうだ。服装も安定しない。
言葉でダメなら、絵から絵を生成するのはどうだろうか? 下絵のようなものを読み込ませて、そこから生成したらキャラクターデザインが反映されるのではないだろうか。
絵から絵を生成できるツールを探したところ、Stable Diffusionでできるようだ。Stable Diffusion は画像生成AIのひとつだ。オンラインでも使えるがローカルに落として使うと、無料だし色々複雑なことができる。
そこで、Stable DiffusionをローカルPCでやろうと思ってPythonを入れてGitからダウンロードしてみたが、VRAMが足らずに動かせなかった。
つまり、パソコンのGPUスペックが足りなかったのだ。
VRやるときにも困るし、そろそろガツンとVRAMの載ったパソコンが欲しいものだ。
とはいえ、すぐポンっと数十万出せるわけではないので、いったん他の方法で考えなくてはいけない。
Stable Diffusionが使えるiPadアプリを試す
探していたところ、macOSのアプリで「Draw Things」というものを見つけた。iPadやiPhoneでも使えるアプリで、Stable Diffusion が使えるらしい。幸いiPadを持っている。iPadにDraw Thingsを入れて使ってみることにした。

アプリを入れてみる
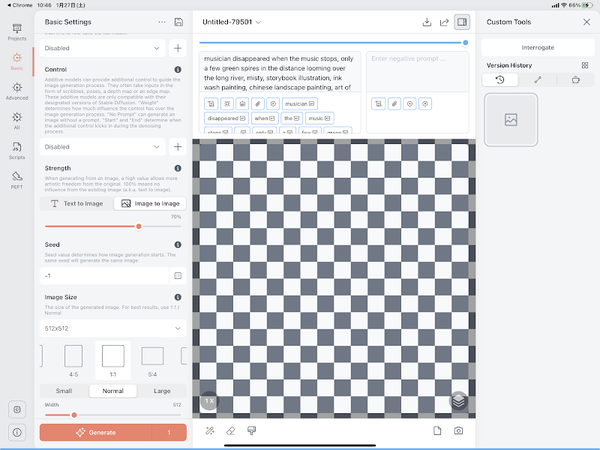
こんな感じの画面。セッティングのStrengthのところでimage to image(画像から画像生成)が選べる。
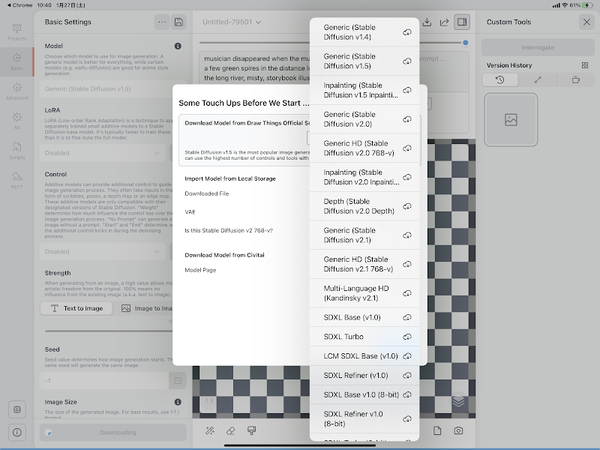
画像生成AIのモデルを選べるようだ

元の絵として、下手くそな絵を描いてみた
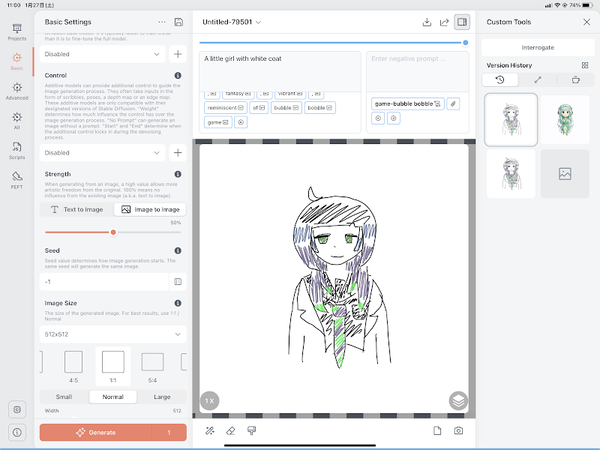
読み込ませる
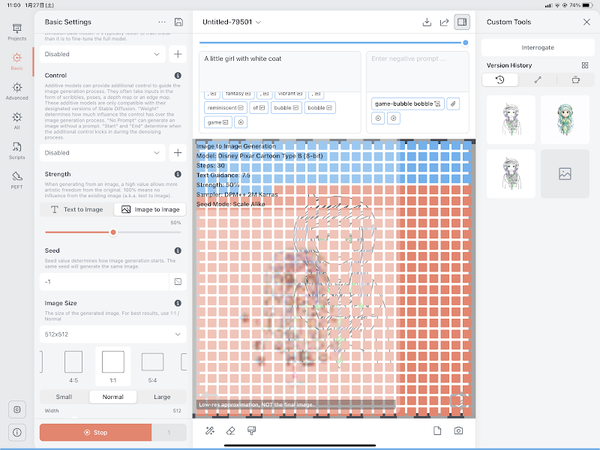
上部に文字を入力して、設定のStrengthで読み込ませた画像と文字の、どちらをどれくらい優先するかを決められる
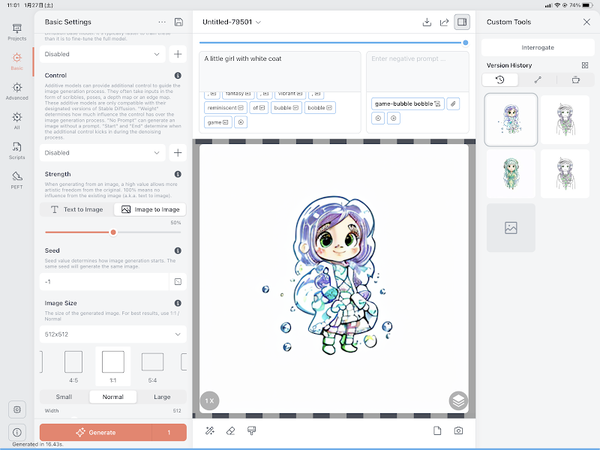
そうなるか……

モデルをアニメ調のものにしてみた。ダウンロードする

そうなるか……
テキストによる指示と画像の指示の飲み込む割合を決める、Strength設定がかなりキモのようだ。
上のものはテキストと画像の割合を50%でやったものだ。
身体があると難しそうなので、顔だけでやってみよう。

顔だけの元絵
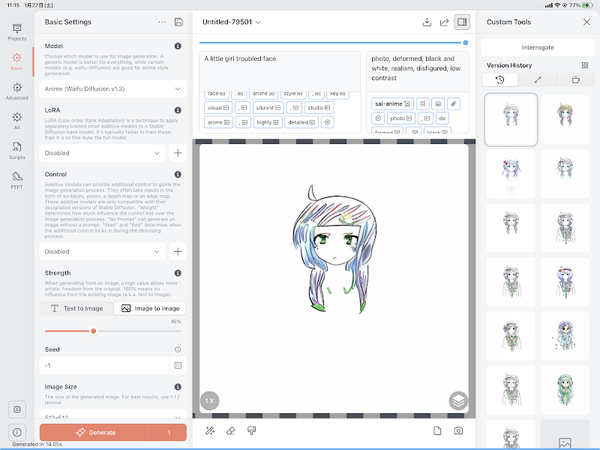
テキストの割合が35%。画像の割合が多い場合
元絵をちょっと可愛くした感じだ。
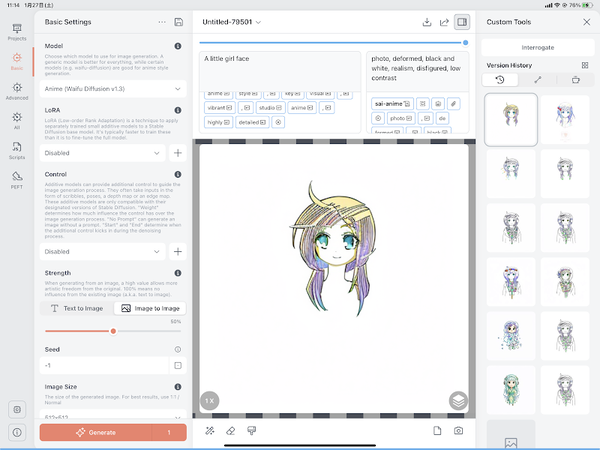
50%。少しテキスト側の解釈が入ってくる。
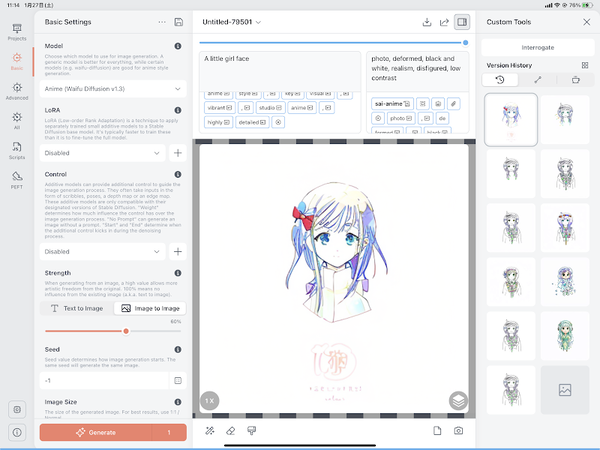
テキストが60%。もう可愛い女の子になっている。
と、こういう具合で文字の割合を増やすと可愛くなっていく。
元絵が下手くそすぎるからだけど。
絵が小さすぎて、キャラデザが反映されないのかな?絵をわかりやすく丁寧に大きく描いてみる。

大きく描いてみた
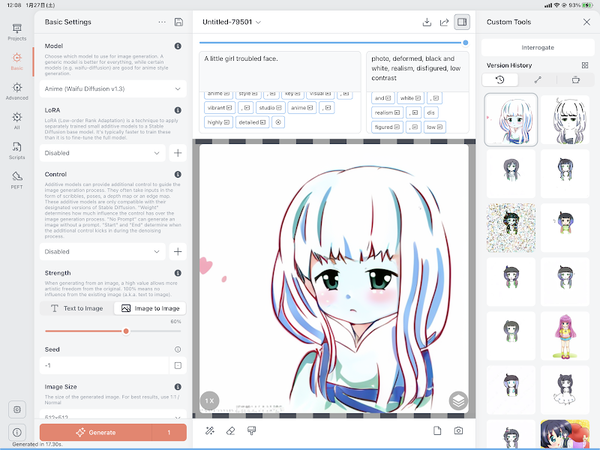
テキストの割合が60%。キャラデザは踏襲されてる気配あるけど、かわいくない……
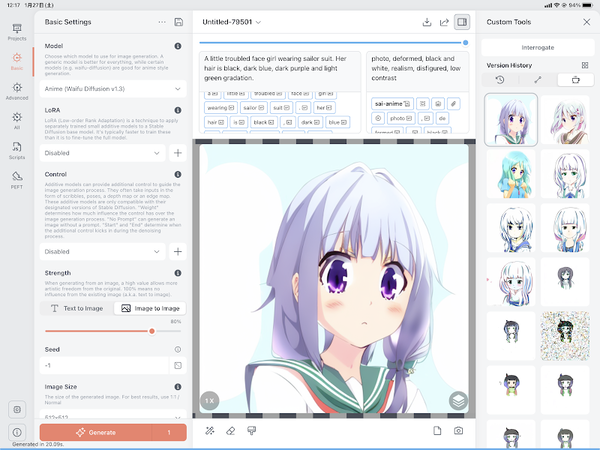
テキストの割合が80%。もう別のキャラデザでは!?
結論。元の絵が上手くないから、元絵を優先させて生成させるとかわいくなくなる。かわいくしようと思って文字の割合を上げると別のキャラになる。「絵描くの上手くなりてえ」とこんなに思ったことはない。
「LoRA」でゆんちゃんを学習させればいいんじゃん!!
さて、ここで筆者は気づいたのである。
LoRAって、名前は聞いたことあるけど、なんだ……? 設定のところにあるぞ……?
LoRAとは、特定の人物やキャラクターだけを学習させて、その人物やキャラを出力できるようにしたり、特定のポーズを学習させて複雑なポーズをさせたりできるやつらしい!!!
これじゃん!!!
ゆんちゃんを学習させればいいんじゃん!!!
ちなみに、芸能人や漫画のキャラを学習させてしまって問題になったりもしているらしい。筆者のは完全個人所有キャラなので無問題だ。
しかし、ここでまたVRAMの壁が立ちはだかる。
学習するのに、大きなVRAMが必要らしい……。LoRAをやりたくてもうどうしようもなくなっていた筆者は必死に検索をかけた。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
- 第346回 「そこそこ稼ぐおじさん」でいいのか? 迷ったあなたへ
- 第345回 順調なのに不安 その違和感、実は“次のサイン”です
- 第343回 メディアアート再燃?「TOKYO PROTOTYPE」に人が殺到した理由
- 第342回 休職中の同僚を「ずるい」と思ってしまうあなたへ
- 第341回 3Dモデルを必死にリギングした結果、「AIが優秀すぎる」ことに気づいた
- 第340回 VRChatでロボットになりたい筆者、最終的にBlenderを選んだ理由
- 第339回 復職が不安なあなたへ。“戻らない復職”を私が選んだ理由
- 第338回 DJをやってみようと思い立った
- 第337回 「子どもを預けて働く罪悪感が消えない」働く母親の悩みに答えます
- 第336回 ChatGPT、Gemini、Claude──特徴が異なるAI、どう使い分ける?
- この連載の一覧へ