Google Analytics 4の生データをAmazon Redshiftに継続的レプリケーション

本記事はCDataが提供する「CData Software Blog」に掲載された「Google Analytics 4 の生データを Amazon Redshift に継続的レプリケーション」を再編集したものです。
Google Analytics 4 (GA4) は生データをBigQueryにシームレスにエクスポート可能なため、Webサイトの閲覧情報と実際の購買情報など、BigQuery で管理している様々なデータと組み合わせて分析できる点が魅力です。
しかし、Amazon Redshift などBigQuery 以外からは通常GA4の生データにアクセスできず、Google Analytics APIやCSV、サードパーティ製品のコネクタ経由で取得可能な集計データのみの利用となってしまうため、精度の高い柔軟な分析が難しい点が悩みの種です。
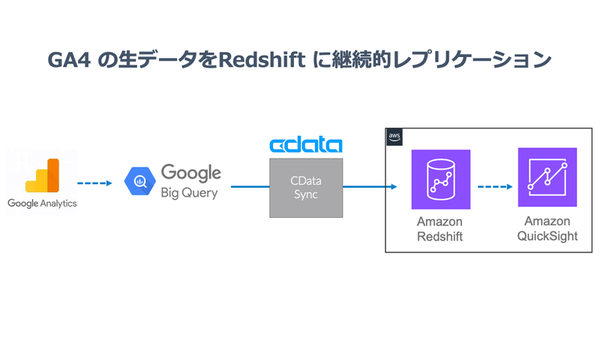
今回は上記の課題を解決するため、CData が提供しているパイプラインツール「CData Sync」を使用して BigQuery に蓄積されたGA4の生データを Redshift に自動で継続的にレプリケーションするフローを構築してみたいと思います。
レプリケーションまでの流れ
CData Syncを使ったレプリケーションの手順は以下です。
1. テスト環境の準備
2. Google CloudにてBigQueryの設定
3. GA4をBigQuery のプロジェクトに連携させる
4. CData SyncにRedshiftとBigQueryへの接続設定を追加
5. CData Syncにジョブを追加
6. CData Syncにレプリケーションタスクの追加
7. CData Syncでレプリケーションジョブのスケジュール実行
なお今回の構成ではRedshiftはすでに構築済みで、CData SyncはRedshiftにアクセス可能なVPC 内のWindows Server上にインストールする前提です。
Redshift 環境がない場合は以下のチュートリアルを参考に構築してみてください。
手を動かしなら学ぶ Analytics サービス入門
それではさっそく始めてみましょう。
1. テスト環境の準備
テスト環境の準備として、Webページの作成やGA4の初期設定を行います。すでに環境がある場合はこのセクションは飛ばしてください。
CData Sync環境の準備
CData Syncは30日間の無償トライアルが可能ですので、CData SyncをインストールするWindowsサーバー上にインストーラをダウンロードしてexe ファイルを実行すればすぐに利用が開始できます。
https://www.cdata.com/jp/sync/
Amazon LinuxなどWindows以外のプラットフォームをお使いの場合はクロスプラットフォーム用インストーラー(.tar)をダウンロードしていただければOK です。
Amazon S3 にてテスト用Webページの設置
GA4でWebページのアクセス情報を取得するためにテストページを作成します。
今回は「Amazon S3を使用して静的ウェブサイトをホスティングする」を参考にテスト用のホスティング環境を作成しました。
S3上にホスティング環境ができたらファイル名を index.html としたシンプルなHTMLファイルを作成してS3バケットにアップロードします。
HTMLファイルが保存できたら、バケットの「プロパティ」タブ下部にある「静的ウェブサイトホスティング」のエリアに表示されているURLにブラウザでアクセスしてWebページが表示可能か確認します。

GA4によるデータ収集の設定
作成したテストページの閲覧情報をGoogle Analytics 4で取得するため、以下のドキュメントを参考に設定します。
[GA4] アナリティクスで新しいウェブサイトまたはアプリのセットアップを行う
テストページ用のHTMLファイルにGoogleタグを設定したら、S3バケットに上書き保存します。
Google タグを追加したHTMLファイルをS3バケットに保存できたら再度ブラウザでWebページにアクセスし、Googleアナリティクスのダッシュボードでテストページへのアクセス状況が表示されるかを確認しましょう。

2. Google Cloud にてBigQuery の設定
続けてGA4データのエクスポート先となるBigQuery環境を追加します。
GA4と同様のGoogleアカウントでGoogle Cloudの管理画面にログインし、以下公式ガイドを参考にしてGoogle Cloudプロジェクトを新しく追加後、BigQuery APIを有効化します。
ステップ 1: Google API Consoleプロジェクトを作成し、BigQueryを有効にする

3. GA4をBigQuery のプロジェクトに連携させる
以下のドキュメントを参考に、GA4側でBigQueryとのリンクを設定します。
ステップ 3: Googleアナリティクス 4プロパティをBigQueryにリンクする
設定ができたらGA4にて 「管理 > サービス間のリンク設定 > BigQuery のリンク > リンクしたBigQueryのプロジェクト >データ ストリームとイベントの設定」を開き、エクスポートするデータ ストリーム の項目にテストページに設定したデータストリームが選択されているか確認しておきましょう。
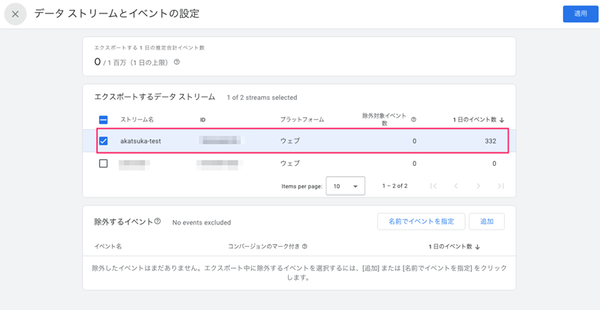
3-1. GA4からBigQueryへエクスポートされたかを確認
GA4からBigQuery へのエクスポートタイプが「毎日」になっている場合はデータのエクスポートに1日程度かかります。
作成したBigQueryのプロジェクトに analytics_xxxxxx のようなデータセットが作成され、その配下に日次のテーブルがevents_YYYYMMDD の形式で作成されていれば成功です。
参考までに、今回の検証では翌日の午前6時ごろにテーブルが作成されていました。

4. CData SyncにRedshift とBigQuery への接続設定を追加
いよいよCData Syncを使ってレプリケーションの設定を行なっていきます。
まずは CData SyncにRedshift とBigQuery の接続設定をそれぞれ追加します。
4-1. CData SyncにRedshiftとの接続を追加
4-1-1. CData Syncのダッシュボードの「接続」メニューにて「接続を追加」をクリック

4-1-2. 「コネクタを選択」画面でRedshift を選択

4-1-3. 「新しい接続」接続画面でRedshiftへの接続情報を登録して「保存およびテスト」をクリックし、CData SyncからRedshiftへの接続を確認
参照:CData Sync - Amazon Redshift

4-2. CData Sunc に BigQuery との接続を追加
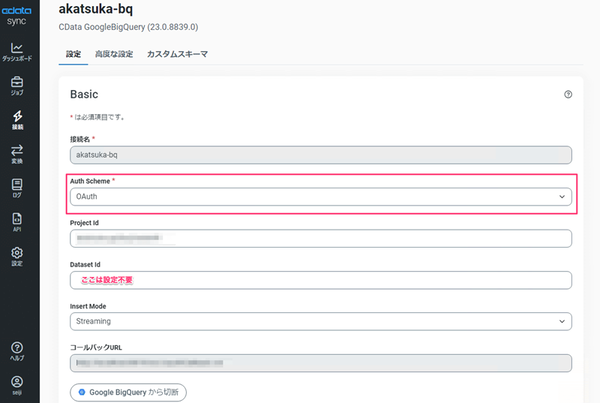
Redshift の接続設定と同様にCData SyncからBigQueryへの接続を追加します。
Redshift との接続設定と異なる点は、「Auth Scheme」に「OAuth」指定をしている点です。
参照:CData Sync - Google BigQuery
5. CData Syncにジョブを設定
CData Sync管理画面左側の「ジョブ」メニューから「ジョブ」に移動後、右上の「ジョブを追加」をクリックしてソース(BigQuery)への接続情報と同期先(Redshift)への接続情報を登録します。

6. CData Syncにレプリケーションタスクの追加
一般的なタスク設定では、「ジョブ」にある「タスク」タブを開いて「タスクを追加」をクリックし、データソースとなるテーブル名を選択しますが、BigQuery にエクスポートされるGA4のデータは、「events_YYYYMMDD」のテーブル名で1日ごとに保存されるため、固定のテーブル名での指定ができません。
こういった場合、CData Syncでは以下の手順のようにレプリケーション時にBigQuery 側のテーブル名を動的に生成して指定する処理を追加して対応します。
6-1. ジョブにPre-Job イベントを設定
「Events」タブの「Pre-Job」にて変数にジョブ実行時の月日を取得してセットする処理を追加します。
の直後にジョブ実行日の前日の日付を「yyyyMMdd」のフォーマットで取得し、環境変数「yesterday」に登録しています。

6-2. CData Syncにレプリケーションタスクの追加
Pre-Jobイベントで設定した環境変数を使って動的にテーブル名を取得する処理を追加するため、「ジョブ」にある「タスク」タブを開いて「タスクを追加」をクリックし、カスタムクエリを有効にします。
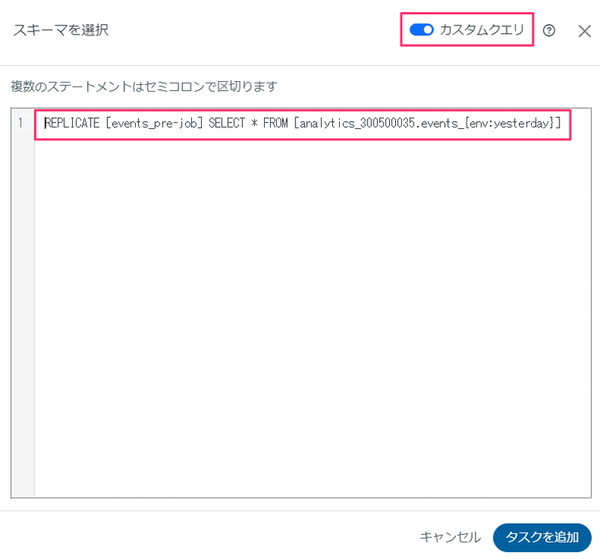
カスタムクエリの登録画面が開いたら以下のクエリを指定します。
REPLICATE [events_pre-job] SELECT * FROM [analytics_300500035.events_{env:yesterday}]
・events_pre-job : Redshift 側に自動で作成する任意のテーブル名
・env:yesterday : Pre-Job イベントで設定したジョブ実行日の前日の日付
・analytics_300500035 : BigQuery のデータセット名
・events_{env:yesterday} : 日次で作成されるテーブル名
カスタムクエリで利用できる日付フォーマッタの詳細については公式ドキュメントをご参照ください。
なお、同期先のテーブルを月毎に作成したり、年月カラムの追加も可能ですのでこちらも必要に応じてご活用ください。
6-3. CData Syncでレプリケーションタスクの動作確認
ソースデータへの接続、同期先への接続、およびデータフローとなるジョブとタスクが作成されましたので、実際にタスクを実行してレプリケーションを行なってみます。

手動でタスクを実行したらジョブの履歴で、レプリケーションが実行されたかを確認します。
Redshiftのクエリエディタ V2 でもテーブル名 「events_pre-job」で新規にテーブルが追加され、データが保存されたことが確認できます。

補足として、今回はBigQuery 側に日次で個別に作成されるテーブルからレプリケーションを行うため、差分同期の設定は不要でしたが、固定のデータソースから定期的に差分のみ同期を行いたい場合は以下のように差分レプリケーションの対応も可能です。

7. CData Syncでジョブのスケジュール実行
意図したレプリケーションの実施が確認できたら、ジョブの「概要」タブ内にある「スケジュール」の項目で自動実行するスケジュールを設定します。

以上でBigQueryに蓄積されたGA4の生データをRedshiftに自動で継続的にレプリケーションするフローが完成しました。
最後に Amazon QuickSight で Redshift にレプリケーションされたデータを可視化してみましょう。

簡単なサンプルですが、QuickSight で可視化もできました。
ぜひみなさんの環境でもお試しください!
本記事はアフィリエイトプログラムによる収益を得ている場合があります