

はじめに
こんにちは、ヘルプデスクの光武です。
2023年11月のAWS re:Inventで生成AIアシスタント、Amazon Qが発表されました。
その中でヘルプデスクと特に関わりがありそうなAmazon Q in Connectに興味がありますが、その前にそもそもAmazon Qがどのような回答を行うことができるのか気になりました。
プレビュー期間ということで、様々なデータソースに対応していますが、今回はS3を利用したデータソースの連携を行ってみました。
Amazon Q作成前に
Amazon Qは現在、バージニア北部(us-east-1)とオレゴン(us-west-2)しか対応していないため、今回リージョンをバージニア北部で作成します。
Amazon Qを作成する前に、先にバージニア北部でS3を作成しておきます。
特に設定はないのでデフォルトのまま作成でOK。
Amazon Qの作成
作成手順
Amazon Qの作成に移っていきます。
サービスからAmazon Qを選択します。
ApplicationのCreate Applicationから作成します。

Application nameはそのままでOK。
Create and use a new service roleを選択、Service role nameもそのままでOK。
その他設定もそのままで行います。
Createを押すと作成開始されます。

次にデータソースについての設定を行います。
RetrieverではUse native retrieverを選択します。
Index Provisoningを最小の1にしておきます。
その他設定はそのままで進めます。
Nextを押します。

Connect data sourcesではAmazon S3を選択します。
多くの種類のデータソースが対応しており、非常に便利ですね。
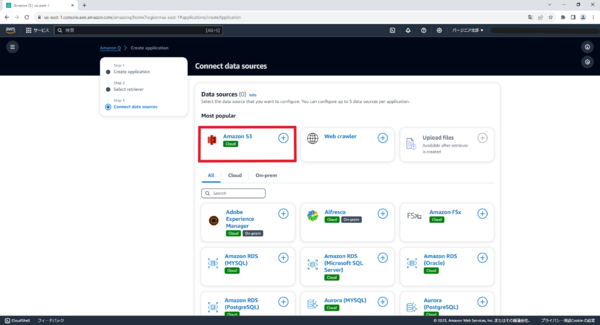
Data source nameに任意の名前を入力します。
Virtual Private Cloud(VPC)を選択します。今回はNo VPCで行います。
IAM roleはCreate a new service rolwを選択します。
Role nameはそのままでOK。
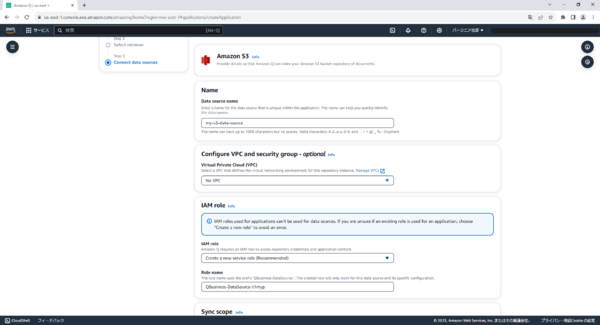
Sync scopeのEnter the data source locationで先ほど作成したS3を選択します。
Maximum file size, Advanced settings, Filter patternsはそのままで行います。
Sync modeはFull SyncとNew, modified, or deleted content syncがあります。
今回は下のNew, modified, or deleted content syncを選択します。
Sync run scheduleでは同期の頻度を設定できます。
細かく設定できますが、今回はRun on demandを選択します。

その他設定はそのままでAdd data sourceを選択します。
ページ下部のFinishを選択してアプリケーション設定完了となります。
Preview web experienceから実際に試してみることができます。
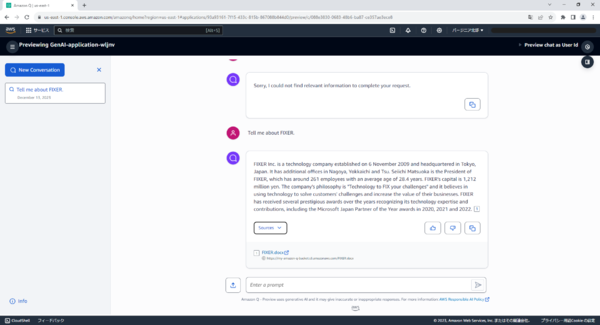
試しに何か質問してみます。
FIXERについて質問すると、回答は「Sorry, I could not find relevant information to complete your request.」と返ってきました。
まだS3にはファイルを入れていないのでもちろん回答が返ってくるはずがありません。
Amazon Qは回答をソースに持たない時は、このように表示されるようです。

では、S3にソースとなるファイルをアップロードします。FIXERについての説明を英語に翻訳して記述したファイルをアップロードしてみます。

しかし、先ほどSync run scheduleでRun on demandを選択したので、まだSyncされていません。
先ほど作成したData source nameを選択し、Sync nowを押すことで同期が開始されます。

Current sync stateがSyncing-crowling→Syncing-indxing→Idleとなり、Last sync statusがComplited、Data source stateがActiveになれば成功です。
Last sync statusは、失敗した場合はFailed、いくつか成功したが失敗したものがあった場合はCompleted with errorsとなります。
上手くいかなかったときにCloudWatchで確認したところ、1つ当たりのファイルサイズが5MB以下でないとエラーとなることが分かりました。

もう一度同じ質問をしてみます。
ファイルに書かれていた内容とソースを示して回答されました。
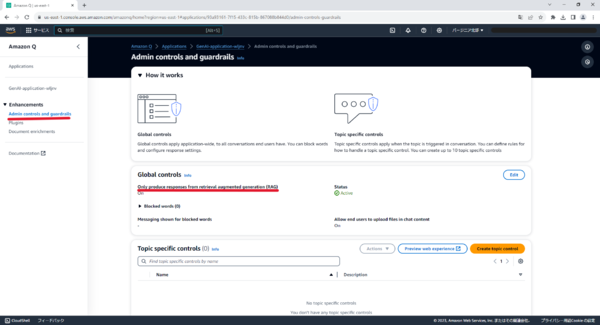
色々試して分かったこと
Admin controls and guardrailsを押し、Editを押し、Only produce responses from retrieval augmented generation(RAG)のチェックボックスを外すと、回答を持っていなくてもChatGPTのように生成するようになります。
反対に言えば、Onにしておけばソースからしか回答しなくなり、ハルシネーションを減らすことができます。
ちなみに本来は英語でしか質問を受け付けませんが、この状態だとその他の言語で質問したとき、質問した言語で回答することがあります。
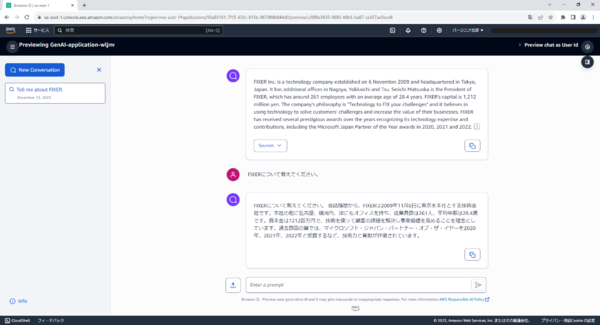
質問の隣にファイルをアップロードする場所があり、会話中のみソースとして読み込ませることもできます。

また、今回VPCの設定で「No VPC」で行いましたが、VPCを用いる場合はこちらを参考に先にVPC、サブネット、セキュリティグループを作成してデータソース設定の際に割り当てる必要があります。
さらにそのまま実行しても権限の不足でSyncが失敗しました。こちらにある「If you are using an Amazon VPC, you must add the following VPC access permissions to your policy」に記載されているアクセス許可をもとに参照するS3を設定するときに作成したIAMロールに追加することで実行できました。
おわりに
Amazon Qの作成とS3を利用したデータソースの連携を行ってみました。
あまり文章に大きな変更を行わず、抜き出して出力してくれるといった印象でした。
また、ソースにないことは回答しないと設定することが容易であるという特徴もあります。
まだ日本語は対応していませんが、将来的に対応されることが楽しみです。
ヘルプデスクをアップデートできる「Amazon Q in Connect」も試せればと思います。
光武 祥慶/FIXER
(みつたけ よしちか)
2023年度新卒で入社、ゲームはすることもみることも好きです。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
TECH
自治体業務でどう使う? 生成AIアイデアソンに自治体職員が挑戦 -
TECH
アンケート分析」「トーク台本作成」を効率化、お客様サポート業務でのGaiXer活用 -
TECH
生成AIのプロンプトがうまく書けないときのアプローチ(演繹法/帰納法) -
TECH
“GPT-10”が登場するころ、プロンプトエンジニアはどうなっているか? -
TECH
生成AIは複雑な計算が苦手、だからExcelを使わせよう -
TECH
BPEの動作原理を学び、自作トークナイザーを実装してみた -
TECH
エンジニアとプロンプトエンジニアの違い、「伝える」がなぜ重要なのか -
TECH
システムエンジニア目線で見たプロンプトエンジニアリングのコツ -
TECH
学生向けの生成AI講義で人気があったプロンプト演習3つ(+α) -
TECH
ユースケースが見つけやすい! 便利な「Microsoft 365 Copilot 活用ベストプラクティス集」を入手しよう -
TECH
Gemini CLIのここがすごい! Go+Vue3のアプリを作らせてみた - この連載の一覧へ




