





Stability AIは11月21日(現地時間)、同社の生成画像モデル「Stable Diffusion」をベースにした生成動画用の最初の基礎モデル「Stable Video Diffusion」を研究プレビュー用途で公開した。
テキストから動画を生成
Stable Video Diffusionは、毎秒3~30の可変フレームレートで動く14フレームおよび25フレームの動画を生成できる2つのモデルで構成されており、3フレーム/秒で単純計算すると最長8秒強の動画が生成できることになる。
公開されたデモ動画を見ると「Ice dragon in the mountains(山の上のアイスドラゴン)」「Astronaut walking on the moon(月面を歩く宇宙飛行士)」「Two Blue Jays on the top of a building(建物の屋上に2匹の青カケス)」といった自然言語から数秒の動画が見事生成されているのがわかる。

一枚の画像から360度ビューを作成することも可能なようだ。
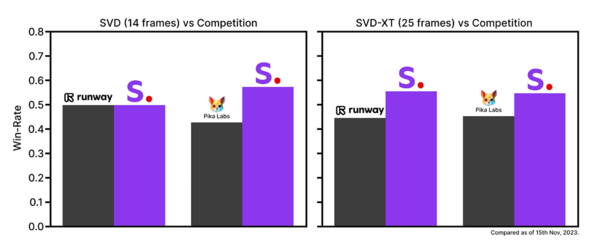
同社によるユーザー嗜好調査によると、競合となる「runaway」「Pika Labs」の基礎モデル(いずれも非公開)との比較でも優位な結果が出ているという。
なによりStable Video Diffusionのすごいところは、基本的にクローズドサービスであるrunawayやPika Labsと異なり、研究プレビュー用途ながらモデルおよび、モデルをローカルで実行するためのウェイト(重み)を公開しているところだ。
ユーザーはウェイティングリストに登録することで、これらすべてを無料で利用できるようになる。要求されるマシンスペックは高そうだがいよいよ夢の「Text to Movie」が自分の部屋でも実現できるのだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















