

2019年9月に都内で開催されたNW-JAWSのセッション中、筆者の心をもっとも強く惹きつけたのが、スカイアーチネットワークスの福島 厚さんの「18xlargeなら100Gbps出せるのか」というものだった。100Gbpsである。そんな速度がどこに必要なのかと問うのは野暮というもの。高性能なものが手に入ればそのパフォーマンスを確かめたくなる。そこに理由も理屈もいらない。福島さんのチャレンジに筆者は胸を躍らせつつ取材に臨んだ。

スカイアーチネットワークスの福島 厚さん
100GbEを提供すると発表されたけど、本当に100Gbps出るの?
2018年のre:Inventで発表されたEC2 C5nインスタンスは、「100Gbpsのネットワークスループットを提供する」と謳っていた。この発表を聞いた福島さんには、単純な疑問が浮かんだという。それは、かつて読んだ技術書「詳解システム・パフォーマンス(オライリー・ジャパン)」にあった一節を思い出したからだという。
「私が読んだのは少し古い版ですが、そこには4チャネルのPCIeスロットにデュアル10GbEインターフェイスを接続しても、カードの最大帯域幅の制限により最大20Gbps、さらにスロットの最大帯域幅の制限により16Gbpsにまで性能が抑えられると書かれていました。AWSのEC2にも様々な制限が考えられます。単純にNICの性能だけが100GbEだったとしても、他のボトルネックはないのかと考えたのです」(福島さん)
クラウドとはいえ、雲の向こうには物理的な機械が設置されており、CPUやメモリなどの制限は存在する。たとえばDDR4-2666規格のメモリを使っていれば、チャネル当たりの通信速度は約170Gbps。100Gbpsの通信を実現するためには、そもそも内部のデータ処理がメモリのスループットの半分以上を占めることになる。もちろんCPUもボトルネックになり得る。100Gbpsを実現するためにはMTU9001だとして150万パケットを1秒間で処理しなければならない。3GHzのCPUなら約2000サイクルで1パケットの通信処理を行なわなければならない。しかもこれはいずれも、通信に全力を傾けた場合の試算である。

クラウドとは言え、物理の壁は超えられない
また、100GbEを利用できるインスタンスは限られている。高性能なインスタンスでなければ、100GbEを利用できないのだ。あまりに高価なインスタンスでは福島さんは、100GbEを利用できるc5n.18xlargeの利用料金を調べた。
「価格表を見ると、1時間当たり日本円換算で500円くらいでした。通信速度を計るために対向でインスタンスを用意すると1時間当たり約1000円ということになります。つまり、検証のために数時間使うだけなら、サウナに1回行く程度の金額で済む訳です」(福島さん)
高性能なCPUにメモリ、100GbEインターフェイスを用意するには100万円ほどかかるので、数千円で試せるのは手頃だと福島さんは言う。もっとも、実際には検証中に寝落ちしてしまい1万円ほどかかってしまったそうだが……それでも実機の100分の1のコストで100GbEのパフォーマンスを検証できるのはクラウドならではだ。
最大パフォーマンスを発揮するには複数のプロセス、スレッドをうまく使うべし
まずは、c5n.18xlargeを対向でセットアップした。OSはAmazon Linux 2、MTUはOSデフォルトの9001。5~6ストリームでデータを流してiperf3で計測したところ、25Gbps当たりで頭打ちになってしまった。どうやら特定のCPUがボトルネックになっているようだが、c5n.18xlargeでは70以上ものCPUがあり、どのCPUがボトルネックになっているのか特定するのが難しい。iperf3は単一プロセスで多重化しているので処理が特定のCPUに偏るので、それがボトルネックになっている可能性があった。
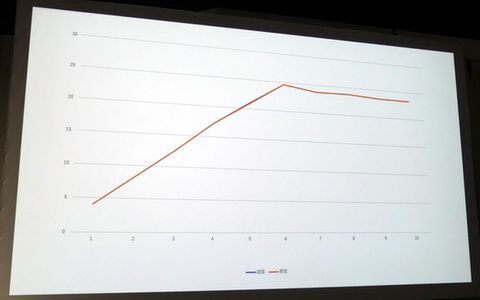
25Gbpで頭打ち
「測定方法を変えました。複数プロセスを利用することにして、各プロセス1ストリームとし、10プロセス30ストリームまで測定しました」(福島さん)
パフォーマンスの限界を見たい。その気持ちはわかるが、けっこう面倒くさい領域に踏み込んでいるようでもある。しかも、/proc/interruptでRSSが有効になっていることを確認。複数プロセッサの処理には効果的なはずだとチェックし、キャッシュも有効に働くよう設定した。
「先に述べたように、c5nは70以上のCPUがあるので、複数プロセスでパフォーマンスを出すために処理をCPUに割り当てるのがとても面倒くさいです。それでもその甲斐があり、20プロセスくらいでほぼ100Gbps出せることを確認しました」(福島さん)
実際のパフォーマンスグラフを見ると、80Gbpsから100Gbpsの間を行き来する様子が見える。これはTCP/IPの仕様により、帯域が足りなくなるとウィンドウを狭くしたり、それにより生まれた帯域の余裕を他のプロセスが利用したりということが起きているのではないかと福島さんは推測する。TCP/IPの帯域制御はプロセスをまたいで統合的にコントロールされている訳ではないので、これ以上の検証はさらに細かい領域に進まざるを得ない。
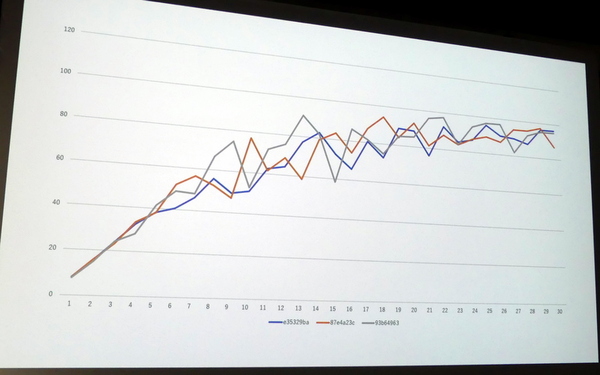
100Gbps出ていることが確認
検証方法の進化にも追随していかなければ最新サービスのパフォーマンスは把握できない
今回の検証では、検証するアプリ自体も同じEC2で動かしており、しかもCPUが70を超えるということで、ボトルネックを探すこと自体がとても困難だった。厳密に計測するならパケットキャプチャを使うべきだが、100Gbpsの通信をキャプチャすると1秒間で10GBのパケットをキャプチャすることになり、それを確認するのは現実的とは言えない。
「今回の検証でわかったのは、実際に80Gbps程度は出せるということ。また、高速な通信を実現したいならクラスタープレイスメントグループに注目すべきかなと思いました」(福島さん)

高速な通信を行なうならクラスタープレイスメントグループがオススメ
クラスタープレイスメントグループを設定することで、近いラックにVMを配置してレイテンシを低く抑えることができる。ただし、これを設定してみても流量は波打つというので、やはりTCP/IPの仕様自体がボトルネックなのかもしれない。
「今回の学びは、高速なネットワークを使用する場合にはマルチプロセス、マルチスレッドを利用して複数のプロセッサに処理を分散する必要があるということと、TCPを複数ストリームで並列に分散する場合は輻輳制御により、必ずしも全開の性能が出るわけではないということです。場合によっては他のプロトコルも検討すべきかもしれません」(福島さん)
搭載プロセッサ数や通信可能帯域が増えた結果、パケットキャプチャのような従来の調査手法が通用しなくなりつつあり、他の指標やツールも学ばなければならないというのが、福島さんの結論だった。しかし簡単そうに語られた検証だけでも80Gbps以上を出せることがわかり、有意義なチャレンジだったと感じた次第だ。
セッションパートが終了したNW JAWS。最後は登壇者が壇上に集まり、200人以上にのぼる会場からの質問に時間を割いた。どれもネットワーククラスターらしい濃い質問で学びがあった。AWSのネットワークもどんどん進化しているので次回も期待したい。

運営メンバーと今回の登壇者でパチリ!おつかれさまでした!
本記事はアフィリエイトプログラムによる収益を得ている場合があります




















")

