

本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「Azure Data Factory の主要な構成要素を整理してみた」を再編集したものです。
はじめに
データ利活用の重要性の高まりに伴って、複数のデータソースを参照して、データの統合や分析・可視化を行うデータパイプラインの構築が重要視されています。
これを実現するためのソリューションとして、Azure Data Factory が挙げられます。
本記事では、Azure Data Factory の基本的な概念と構成要素について整理し、Azure Data Factory の理解を深めることを目的とします。
この記事で得られること
・Azure Data Factoryの基本概念や構成要素の理解
Azure Data Factory とは
Azure Data Factory (ADF) は、Microsoft Azure が提供するクラウドベースのマネージドなデータ統合サービスです。
Azure Data Factory はこの Orchestration を担当し、複数のデータソースからデータを取得し、必要に応じて外部のコンピューティングサービスを使用してデータを変換・加工した上で、目的のデータストアに格納する ETL/ELT パイプラインを構築できます。
これを図示すると下記のようになります。
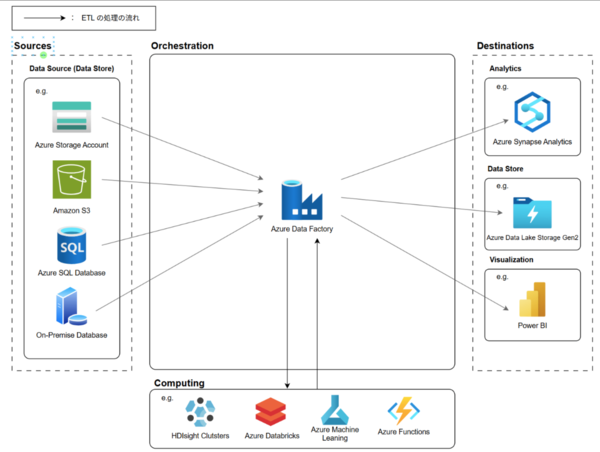
主な特徴
・コードレス開発:GUI ベースでパイプラインを設計可能
・豊富なコネクタ:90種類以上のデータストアに対応し、複数のコンピューティング環境への接続が可能
・スケーラビリティ:Azure のマネージドサービスとして自動スケール
・モニタリング・監視:Azure Data Factory の視覚的な監視により、パイプラインの実行状況を可視化
ETL と ELT
データパイプラインの構築手法として、ETL と ELT という2つのアプローチがあります。
E、T、Lはそれぞれ、Extract、Transform、Load の頭文字を表しており、下記のような意味を持ちます。
・Extract:データソースからデータを抽出 (読み込み)
・Transform:データの変換・加工・クレンジング
・Load:変換後のデータをデータストアに格納 (書き込み)
これらの処理を組み合わせた処理の流れは、以下のようになります。
・ETL とは、データを抽出(Extract)し、変換・加工(Transform)してから、目的のデータストアに格納(Load)する手法です。
・ELT とは、データを抽出(Extract)し、そのまま目的のデータストアに格納(Load)してから、変換・加工(Transform)する手法です。
ETL/ELT の詳細については「抽出、変換、読み込み (ETL) | Azure Architecture Center」をご参照ください。
Azure Data Factory の構成要素
Azure Data Factory は、いくつかの主要なコンポーネントで構成されています。
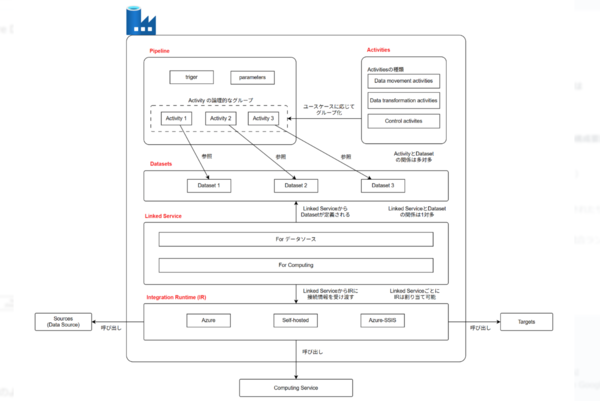
上図のように、Azure Data Factory はこれらを組み合わせることで柔軟なデータパイプラインを構築できます。
※ Pipeline から Data transformation activities のデータフローを呼び出す場合は、別途 IR を必要としますが、簡略化のため図示していません。
以降では、各コンポーネントについて詳しく解説していきます。
Pipeline(パイプライン)
パイプラインは、データ処理タスクを論理的にグループ化した単位です。
1つ以上のアクティビティで構成され、ETL/ELT の一連の処理フローを定義します。
例えば、ETL の「データを取得 → 変換 → 格納」という一連の処理を1つのパイプラインとして定義できます。
図中では、「Pipeline」と表記されています。
Trigger(トリガー)
トリガーは、パイプラインの実行タイミングを制御します。
図中では、Pipeline 内の「Trigger」として表現されており、以下の種類のトリガーが提供されています。
・スケジュール トリガー:指定した時刻で一度きりまたは定期的に実行
・タンブリング ウィンドウ トリガー:固定時間間隔で依存関係のある連続実行 (直前の実行結果によって以降の定期実行を制御することが可能)
・イベントベース トリガー:Blob の作成や削除などのイベント発生時に実行
詳細は「Azure Data Factory と Azure Synapse Analytics でのパイプラインの実行とトリガー」をご参照ください。
Parameters(パラメータ)
パラメータは、読み取り専用のキーと値のペアとして定義され、パイプラインに動的な値を渡すための仕組みです。
同じパイプラインを異なる設定値で実行できるため、再利用性が向上します。
図中では、「Parameters」と表記されており、この値はアクティビティから参照することが可能です。
例えば、以下のようなユースケースがあります。
・処理対象のファイルパスを動的に指定
・処理対象の日付範囲を実行時に変更
・環境(開発・本番)ごとに異なる接続先を指定
Activity(アクティビティ)
アクティビティは、パイプライン内で実行される個々の処理単位です。
図の「Activity 1」「Activity 2」「Activity 3」のように、パイプライン内に複数配置できます。
Azure Data Factory では、以下の3種類のアクティビティが提供されています。
・Data movement activities(データ移動アクティビティ):Copy Activity など、データソース間でのデータコピー
・Data transformation activities(データ変換アクティビティ):Data Flow、Databricks、HDInsight などを使用したデータ変換
・Control activities(制御アクティビティ):条件分岐、ループ、待機などのパイプライン制御
詳細は「Azure Data Factory と Azure Synapse Analytics のパイプラインとアクティビティ」をご参照ください。
Dataset(データセット)
データセットは、パイプライン内で入力または出力として使用するデータの構造を定義します。
図の「Dataset 1」「Dataset 2」「Dataset 3」のように、各アクティビティから参照されます。
データの場所、形式、スキーマなどの情報を含み、例えば以下のようなものをデータセットとして定義できます。
・CSV ファイル
・Azure SQL Database のテーブル
・Blob Storage 内の JSON ファイル
Linked Service(リンクサービス)
リンクサービスは、外部リソースへの接続情報を定義します。
接続情報はデータソースやコンピューティングリソースへの接続文字列、認証情報などを表し、例えば、Azure Storage Account への接続情報や、Azure Databricks への接続情報が挙げられます。
リンクサービスの要素は以下の2種類に分類できます。
・データストアへのリンクサービス:データストアに接続するために使用
・コンピューティングサービスへのリンクサービス:コンピューティングサービスに接続するために使用
図では、「For Data Store」と「For Computing」として表記されています。
Integration Runtime(統合ランタイム)
Integration Runtime(IR)は、Azure Data Factory がデータ統合機能を提供するためのコンピューティングインフラストラクチャです。
図の下部に示されているように、以下の3種類が提供されています。
・Azure IR:Azure 内のデータストア間でのデータ移動や、Azure コンピューティングサービスへのディスパッチに使用
・Self-hosted IR(セルフホステッド IR):オンプレミスやプライベートネットワーク内のデータソースへのアクセスに使用
・Azure-SSIS IR:SSIS パッケージをクラウドで実行するために使用
詳細は「Azure Data Factory の統合ランタイム」をご参照ください。
補足として、Azure IR ではマネージド仮想ネットワークを有効化することで、Azure のサービスに対するプライベートリンクサービスを使用した接続が可能になります。
まとめ
Azure Data Factory の概要と主要な構成要素を整理してみました。今までデータエンジニアリングの分野に触れていない場合はなじみのない単語が見られますが、これらを理解して、ビジネス価値を創出するようなデータパイプラインの構築に励みたいと思います。
参考
・Azure Data Factory とは
・Design for Azure Data Factory
・Key Components of Azure Data Factory
中島悠太/FIXER
2023年度新卒で入社。エンジニア1年生。
社内での担当はまだ未定。
社外では42Tokyoという場所でエンジニアとしてのスキルを研鑽しています。
この連載の記事
-
TECH
私の推しは「Azure Storage Account」、All in Oneなクラウドストレージサービス! -
TECH
Windows Admin Centerとは? ― 2020年代の新しい運用管理のカタチ -
TECH
PlaywrightをAzure Functionsにデプロイして動かす方法 -
TECH
Azure FunctionsとAzureのサービスを連携させる方法 -
TECH
環境ごとに異なるTerraformのバックエンド設定を効率化、override.tfの使い方 -
TECH
法人向け「Microsoft Entra ID P2ライセンス」を個人で購入する方法 -
TECH
通常2万円が無料! 「Microsoft Fabric」のMCP資格(DP-600)を受験しよう【2024年末まで!】 -
TECH
データ分析を楽しみながら学ぼう! Microsoft Fabricコミュニティとは -
TECH
私の推しは「Azure Bicep」、Microsoft公式のIaCツールを使っていこう! -
TECH
私の推しは「Azure DNS」、クラウド入門にオススメです! -
TECH
Azureの管理コスト削減! リソースのタグ付けを自動化しよう - この連載の一覧へ

