
FAX→記事作成までをマルチエージェント化した内製アプリケーションの裏側
地方テレビ局が生成AIで記事作成を爆速に でもその裏で“10倍増えた”業務とは?
2026年02月20日 11時00分更新

地方テレビ局の北海道文化放送(UHB)は、報道の現場に生成AIをいち早く取り入れた。AIが記事のベースを作る仕組みを内製し、人員削減下でもWeb記事数が約2割増えるなど、一定の成果を上げた。しかし、その裏では“10倍”に膨れ上がった業務があるという。
AWSのユーザー会JAWS-UGが2025年12月に開催したイベント「AI Builders Day」では、ビルダー(開発者)たちによるAIエージェント開発に関する知見や実践例が集まった。北海道文化放送 DX推進センターの杉本歩基さんのセッションでは、報道の業務フローに生成AIを組み込んだ経緯や自身で内製した仕組み、運用上の課題などが共有された。

北海道文化放送 DX推進センター 杉本歩基さん
Web記事を“早く・大量に”作るべく、アナログな現場に生成AIを適用
杉本さんがDXを推進するきっかけとなったのは、放送のタイムテーブルを決める“編成局”への異動だった。そこで、視聴率や番組内容、SNSの情報を可視化するツールを「Amazon QuickSight」で自主的に作り出し、AWSでの開発をスタートしている。
その後も、ナレーション音声や縦型動画を自動生成するWebアプリケーションなどを開発。そして、生成AI登場時にもその技術をいち早く取り入れるべく挑戦を始めた。
杉本さんが業務改善で目指しているのが、「とにかく早く、質の高い記事を大量に作りたい」という要求に応えることだ。テレビ番組は尺が限られるため、放送できなかった取材の出しどころはWebしかない。そうしたWeb記事を他局よりも早く世に出すことを目標としていたが、現場のアナログな業務がハードルになっていたという。
例えば、記事の“タネ”になるリリースは、官公庁や企業からいまだにFAXで届く。その数は月1500件に上り、記者はひとつひとつ確認しながら記事にするか追加取材するかを判断していく。さらに、取材後の文字起こしも、記者にとって負担の大きい作業だ。
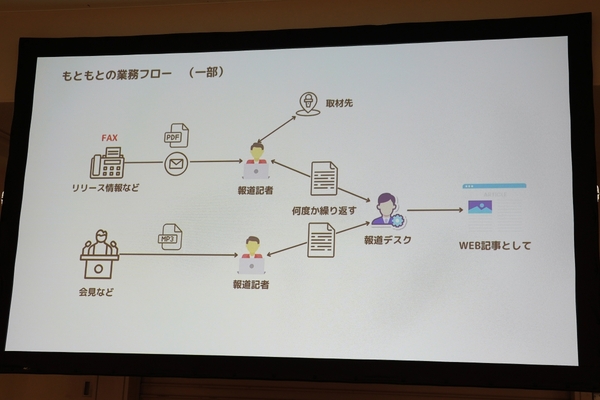
もともとのWeb記事作成の業務フロー
こうしたアナログな業務フローを改善すべく、杉本さんは、インプット側とアウトプット側に生成AIを組み込んだ。
インプット側での実装は2つである。
まず、FAXでリリースが届くと生成AIに自動解析させ、タイトルや要約、ジャンルなどを加えた状態でデータ化する仕組みだ。これにより、届いたリリースを検索できるようになり、要約から記事にする価値があるかを素早く判断できるなった。
技術的にはシンプルで、FAXをメール配信サービスの「Amazon SES」で受けとり、「Vision API(Google Cloud)」のOCR機能でテキスト化しつつ、生成AI基盤「Amazon Bedrock(以下Bedrock)」のLLMで要約などを生成、それを「Amazon DynamoDB」に格納するという流れだ。
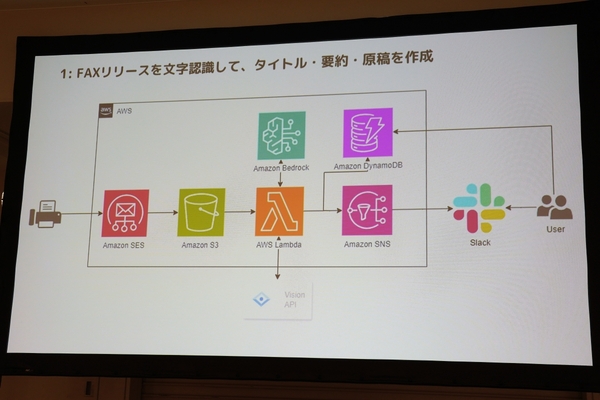
リリースを文字認識識して、タイトルや要約を加えてデータ化
もうひとつのインプット側の処理は、アップロードした任意のファイルを解析する仕組みだ。画像やドキュメントはLLMで処理して、音声・動画は音声認識の「Amazon Transcribe」で“字幕”形式のSRTデータとして出力。動画の場合は、STRデータと共に動画特化のAIモデル「Pegasus」に投げ、タイムライン別の要約やハイライトシーンの抽出、文字起こしをさせる。
「最初はPegasusだけで動画を分析しようとしたが精度が悪く、Transcribeを通してSRTを補助的に与えている。そもそも、動画にSRTファイルがつくだけでも現場は喜んだ」(杉本さん)
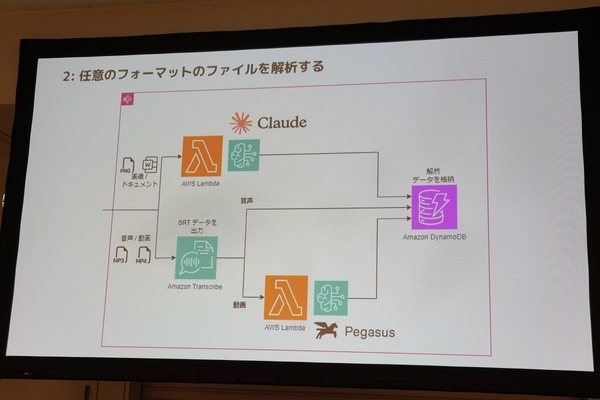
任意ファイルをフォーマットごとに解析
一方のアウトプット側では、インプットで解析した情報をベースに、追加取材した内容や特記事項があれば入力、あとはボタンを押すだけで原稿が生成させる仕組みを構築した。ヒグマの出没や交通機関の速報といった特殊な原稿の場合は、専用のプロンプトを選択できる仕様になっている。

アウトプット側の原稿生成画面
そして、生成AIが出力するのは、LLM(Claude Opus 4.5)が素のままで生成した原稿と、AIエージェントが北海道文化放送らしさを加えた原稿の2種類である。エージェントは、過去記事の検索や文体解析で原稿を最適化しつつ、さらには校正までしてくれる。
このエージェントは当初、Bedrockのマネージドなエージェント基盤「Bedrock Agents」で構築していたが、現在は、マルチエージェントの保守のしやすさからエージェントの実行基盤「Bedrock AgentCore」へと移行している。
本記事はアフィリエイトプログラムによる収益を得ている場合があります






















