SQLとLLM+MCPで業務データのギャップを埋める方法


本記事はCDataが提供する「CData Software Blog」に掲載された「ユニバーサル言語・SQL とLLM+MCP で 業務データのギャップを埋める方法 ~なぜ『CData MCP Servers』がエンタープライズAI を次のレベルへ引き上げるのか?~」を再編集したものです。
こんにちは。CData Software Japanマーケティングマネージャーの杉本です。
最近は生成AIやMCPに関するトピックをSNSなどのネット上で見かけない日は無いなーと感じる日々ですが、皆さんは業務で生成AI・LLMをうまく活用できていますか?
普段プログラミングなどを通じてソフトウェア開発を行っている方々には相当浸透してきている感じがありますが、非エンジニアサイドではまだまだ浸透しきれていないのではないかな? と感じています。
その原因は私達が普段関わっている業務データとのコラボレーション、そして『MCP』という新しいアプローチに鍵があると考えています。

実はCDataでは本日新しいプロダクトとして『CData MCP Servers』の無償ベータ版リリースを発表しました! CDataのSalesforceやGoogle Sheets・kintoneなどSaaSやファイル、DWHなど400種類以上の多様なサービスに接続可能なコネクタをMCP Serverとして実装し、LLMに対して『SQL』ベースでコミュニケーションが可能なツールを提供しています。これによりLLMが業務データのイントロスペクション、SQLの記述と実行、さらには書き込み操作まで、すべてをユーザーの代理で実行できるようにする、汎用的なインターフェースとして成立させています。
https://www.cdata.com/jp/news/20250508-mcperver/
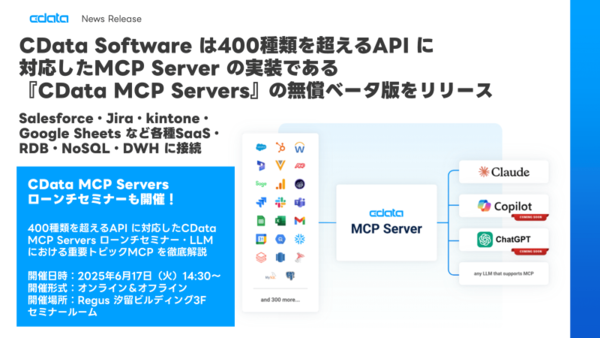
とはいえ、これがどのように私達の業務におけるエンタープライズAIの接続の課題を解決してくれるのか、キーワードだけ眺めてもなかなかイメージが沸かない部分が多いかなと思います。
そこで、今回の記事では企業におけるAI接続の課題と、CDataコネクタがLLMと業務データのギャップをどのように埋め、実用的なエンタープライズAIを実現できるのかを解説していきたいと思います!
イントロダクション:エンタープライズAIにおける接続性の課題
それでは改めてこのエンタープライズAIにおける接続性の課題を掘り下げていきましょう。
生成AIは、私たちの情報との関わり方を変革し、自然言語を使用して「計算」することを可能にしました。大規模言語モデル(LLM)は、知識を統合し、メッセージを通じて推論し、驚くほど流暢に多様なソリューションを生み出すことができます。しかし、その可能性は私達の普段の仕事の場において、前述の通りいまだ十分に活用されていないと考えています。
こんなにも魅力的なソリューションであるにも関わらず、これはなぜでしょうか?
それは、私たちが業務で投げかける質問は、普段私達が利用している数多くのサービス、SalesforceやSAPなどのCRM、ERP、SharePointやBoxといったドキュメントリポジトリ、Jiraなどのコラボレーションツールといった業務システム・SaaSへのアクセスを必要とするからです。

これらのシステムには、Salesforceの「商談」やJiraの「課題」のような、構造化されたビジネス上重要なデータオブジェクトが格納されています。もしLLMがこれらのデータにリアルタイムで確実にアクセスし、対話できるようになれば、企業は会話型で動的、かつAIネイティブな存在になれるのではないでしょうか?
しかし、この接続性・コネクティビティが欠けている限り、AIは強力ではあっても分断されたツールにとどまり、最も差し迫ったビジネスニーズに対応することはできません。
ミッシングリンク:LLMによる構造化データとのコミュニケーション
この可能性を最大限に活かすためには、構造化された業務データと自然言語インターフェースを橋渡しする手段が必要です。そこでポイントになるのが『Model Context Protocol (MCP)』というアプローチです。
https://modelcontextprotocol.io/introduction

MCPは、LLMの機能を専用ツールによって拡張する新たな可能性を切り開きました。しかしながら、現在の実装のほとんどは、API固有の実装に依存し、特定のアクションに焦点を絞ったものがほとんどです。
私達はここで「本当に求められているものとはなにか?」を考えた時、LLMがあらゆるエンタープライズシステム・業務データにシームレスにアクセスできる、『ユニバーサル言語』にあると考えました。それが実は数多くの業務システムの裏側やソフトウェア・データベースで採用されているユニバーサル言語である『SQL(Structured Query Language)』です!
https://ja.wikipedia.org/wiki/SQL
SQLは、「どのようなデータが欲しいか」を明示する宣言型の性質、広範なエコシステム、そして強力でありながら扱いやすい構文により、データアクセスにおいて比類のない言語です。その構造化された形式により、WHERE・GROUP BY、JOINなどのフィルタリング、集計、結合、および分析関数を通じて高度なデータ操作が可能です。
そして、このSQLに関連して、重要なファクターが「ビジネスエンティティに関するメタデータ ―それが何であり、何を含み、どのように関連しているか ―」です。
LLMがプログラミングなどのソフトウェア開発と親和性が良いのは、各プログラミング言語に関する仕様、メタデータがウェブ上に数多く存在していることと大きな関連性があります。私の名前である「杉本」が文字単体では何を示しているかがわからないように、そこに「姓」に関するデータですよ、ないし「会社名」ですよ、という情報・メタデータが無ければ、LLMは適切にそのデータを扱うことができません。
このメタデータが備わっていれば、LLMはコンテキストを咀嚼し、SQLを記述して、必要な企業情報に正確にアクセスし、変換できます。つまり、LLMは文字通り「データと会話する」ことができるのです。
コネクティビティ:エンタープライズAPI の課題とは?
しかしながら、残念なことにほとんどのエンタープライズシステムは「SQL」を話しません。代わりに、断片的で一貫性のないAPI(それはRESTと呼ぶのも難しいような)を公開しています。特定のフィールドに対してはフィルタリングをサポートしていても、他のフィールドではサポートしていなかったり、ページネーションの方法がシステムごとに異なったりし、結合をサポートしているものはほとんどありません。
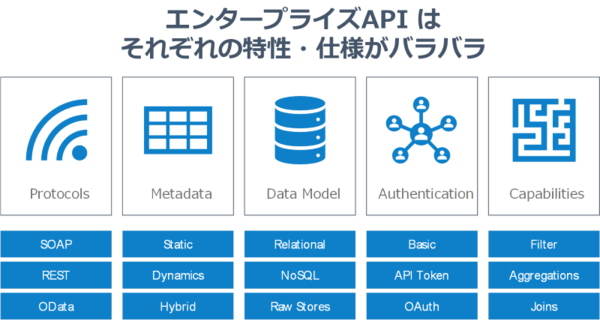
私自身今まで300種類以上のAPIを見て、触ってきましたが、その仕様のバラバラさは目が眩むほどです。
https://www.cdata.com/jp/blog/horizontalsaasapi
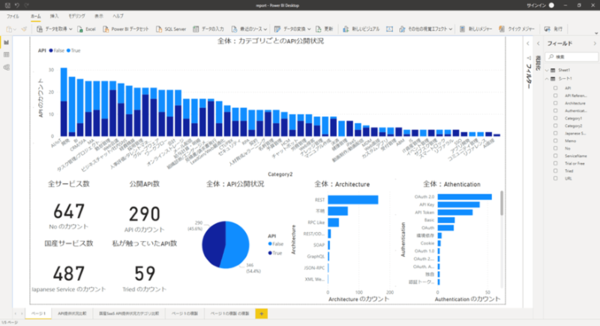
こうした不整合により、LLM(あるいは開発者)がエンタープライズシステムと信頼性高く、安全に対話することは困難になります。
そういった課題に対して現在、多くのチームや開発者はこの課題を次のいずれかの方法で解決しようとしています。
・LLMを使用してAPIアクセス用のコードを生成:でも、これはエラーが発生しやすく、保守も困難です。
・データをウェアハウスに移動:アクセスを一元化できますが、ガバナンスが複雑になり、レイテンシも発生します。
どちらのアプローチも一長一短がありますが、不十分です。コード生成は、テストされていない不透明なロジックを生み出しますし、データウェアハウスはソースシステムからデータをコピーするため、多くの場合管理者レベルのアクセス権を必要とし、セキュリティリスクやコンプライアンス上の課題を引き起こします。また、データを元のシステム側に反映させることも困難になります。
欠けているのは、LLMと業務データの間のリアルタイムでガバナンスが効いた、ユーザー固有の橋渡しなのです。
CData Connector:エージェント型AIに必要な、欠けていたインフラ
CDataは10年以上にわたり、ユーザーが利用しているPower BIやTableauといった様々なツールへのデータへのアクセス方法を標準化するコネクタの構築に取り組んできました。
CDataコネクタは、一方で標準SQLを話し、もう一方でそれをAPI コールに変換するという、とてもシンプルなコンセプトで作られています。現在、SalesforceやSAPなどのCRMやERPプラットフォーム、会計システム、クラウドアプリ、データベースなど、400を超えるデータソースに対応しています。
そのようなCDataのコネクタですが、リアルタイムで動作する通訳のような存在だと考えるとイメージしやすいのではないかなと思います。
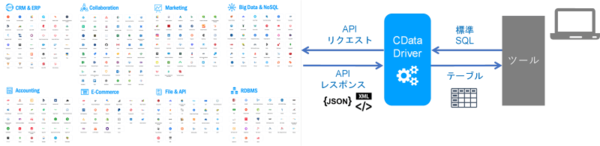
しかし、それは単なる翻訳ではありません。私たちは各SaaSアプリケーションのデータを、エンティティのセマンティクス、関係、制約を記述する深いメタデータを含むリッチビジネスオブジェクトとして細心の注意を払ってモデル化しています。このモデリングこそが、LLMがエンタープライズデータを高いレベルで理解し、操作することを可能にしています。
https://cdn.cdata.com/help/UXK/jp/jdbc/pg_table-customers.htm
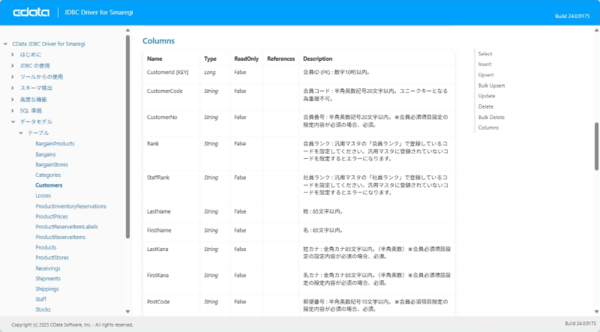
さらに、パフォーマンスにもこだわっています。あるAPIがSQLクエリのセマンティクスを部分的にしかサポートしていない場合でも、コネクタは可能な処理をソースシステムに適切に委譲し、残りをローカルで処理します。これにより常にクライアント側の処理を最小限に抑える設計がされています。
ここで今、LLMがこのモデルに完全かつ動的にアクセスできるようにすることを想像してみてください —脆弱なツールではなく、MCPとCDataのコラボレーションを活用して。
エンタープライズグレードのセキュリティを標準搭載
企業がエージェントAIを導入する際、セキュリティとアクセスガバナンスは決して妥協できない要素ではないでしょうか? CDataのアプローチの大きな利点のひとつは、データの重複や権限の過剰付与といったリスクを回避できる点にあります。
従来のようにデータをデータウェアハウスに移動したり、脆弱な統合コードを生成したりする方法とは異なり、CData Connectorは、ユーザーの認証済みIDを使用し、安全かつガバナンスの効いたAPIを介して、ライブデータにその場でアクセスします。
このアプローチには、以下のような重要な利点があります。
・IDベースのアクセス制御:各クエリは特定のユーザー資格情報の下で実行されるため、ソースシステムにおける権限とロールベースのアクセス制御(RBAC)が常に尊重されます。
・データのコピーなし:データは記録システムの外部に複製されたり一時保存されたりすることはありません。つまり、攻撃対象領域の縮小、コンプライアンスの簡素化、情報セキュリティチームの負担軽減につながります。
・監査可能性とガバナンス: すべてのクエリ、読み取り、書き込み操作はログに記録・追跡可能であり、エンタープライズグレードの透明性とトレーサビリティを実現します。
AIエージェントがユーザーに代わって行動する世界において、セキュリティとコンプライアンスは極めて重要です。CDataはこの現実を前提に設計されています。
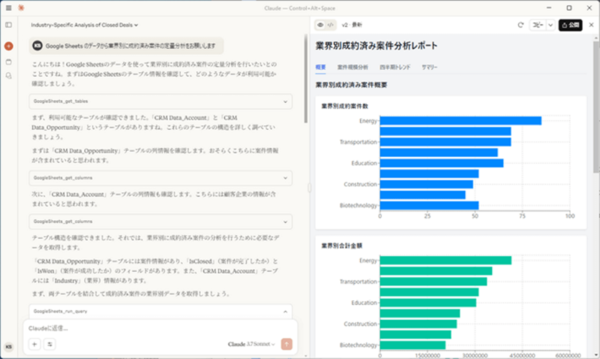
実際にどんな感じで動くの? Claude+CData MCP Serversのデモ
今回の「CData MCP Servers」のリリースでは、このテクノロジーの力を示す技術プレビュー・誰でも利用可能な無償ベータ版を提供しています! 私たちはMCP ServerをAnthropicのClaudeと統合し、期待を上回る結果を得ることができました。
私自身ももともとCDataのテクノロジースタックには大きな可能性を感じて、7年前にJOINしました。その時にもこのコアコンセプト・SQLとメタデータの価値はかなり理解していたつもりです。でも、正直なところ数ヶ月前まではここまでCDataのコアコンセプトとLLM+MCPが大きな親和性を果たすとは思っていませんでした。
以下の動画を見てもらえると、その強力なユニバーサル言語・SQL の親和性とメタデータの価値を感じてもらえると思います!
でも、これはまだ始まりに過ぎないと思っています。まもなく、これらの機能はCDataの各種製品に統合されていきますし、パートナー企業の製品にも組み込まれていく予定です。
ちなみに今回のリリースと合わせて、オンライン・オフラインのハイブリッドイベントとなるローンチセミナー「400種類を超えるAPI に対応したCData MCP Servers ローンチセミナー・LLMにおける重要トピックMCPを徹底解説」も開催しました。
https://www.cdata.com/jp/resources/cdatamcpservers-20250617/

改めて、なぜこれが重要なのか?
エージェントAIは、単に自然言語で会話するだけのものではありません。それ以上に重要なファクターは「アクションをおこす」ことです。ユーザーの代理として、現実世界で意味のあるステップ・アクションを踏むことです。そのためには、コンテキスト、セキュリティ、そしてリアルタイムのエンタープライズデータへのアクセスが必要です。
CData Connectorは、これを可能にするために欠けていたインフラを提供します。
もしあなたが次世代のエンタープライズAIを構築しているなら、私たちがすでに完成させたこのインフラとのコラボレーションを、ぜひ検討ください。ビジネスにおけるAIの未来は、単なる会話ではなく、「エージェント」だからです。
それはシンプルなアイデアから始まります。
「あなたのデータにSQLを話させ、AIを通じてそれらと対話しよう」
本記事はアフィリエイトプログラムによる収益を得ている場合があります