誰でもAIが使える!「Azure Cognitive Services」をみんなで学ぶ 第4回
「カメラ撮影した洋服の洗濯方法を提案するスマホアプリ」を作ってみよう!【中編】
Custom Vision Serviceで「衣類を画像分類するモデル」を作る
2021年07月07日 08時00分更新


皆さんこんにちは! FIXERの新卒1年目、コーディング初心者の池田と廣原です! 今回は「連載:誰でもAIが使える『Azure Cognitive Services』をみんなで学ぶ」の第4回として、「Custom Vision Serviceについて知ろう!」をテーマに記事を書かせていただきます。
前回の前編記事では、Custom Vision Serviceの概要についてお話させていただきました。今回の中編記事では、前回学んだことをもとに、実際にCustom Vision Serviceを使用して「衣類の画像を分類するモデル」を作成していきます。実際にモデルを作成していく中ではわかりにくい部分も出てきますので、その部分を含め、丁寧に説明していきたいと思います。
今回の目次
●モデル作成前の準備作業
●モデルを作成してみよう
-1. モデルの準備をしよう
-2. 画像を登録してみよう
-3. モデルをトレーニングしよう
-4. いざテスト!
●次回はPower Appsアプリと連携します!
モデル作成前の準備作業
前編記事でご説明したとおり、今回の目標は「衣類をカメラで認識し、洗濯方法を提案するアプリ」を開発することです。そこで、Custom Vision Serviceを利用して「衣類の画像を分類するモデル」を作成します。
モデルを作成する前に、まずは以下の2つを準備します。
1. Azureサブスクリプションの作成
2. 学習させる画像の収集
Custom Vision Serviceを利用するにあたり、Azureサブスクリプションが必要になります。まだお持ちでない方は、以下のリンクから無料アカウントが作成できますので、ぜひ作成してみてください。
続いて学習させる画像を集めます。まず、今回のモデルが分類対象とするのは次の5種類の衣服としました。
・Tシャツ
・シャツ
・ニット
・スウェット
・ジャケット
画像分類モデルを作成するには、ある程度の画像データをモデルに学習させる必要がありますので、それぞれの写った画像を収集します。なお、画像収集に際して、いくつかの注意点があります。
・判別したい物1種類につき最低5枚は画像を集めること
・背景の色、明るさなどが異なるさまざまな種類の画像を準備すること
一口に「Tシャツ」といっても、その色や柄、形はさまざまですよね。「Tシャツ」に分類したい幅広いパターンの画像を学習させることで、どんな条件で撮影しても、高い精度で「Tシャツである」と分類できるようになります。また、写っている物(被写体)の背景や周囲の明るさも同様で、幅広いパターンの画像を用意したほうが判別の精度が上がります。
なお、モデルの作成には学習させる画像が最低5枚必要ですが、公式ドキュメントでは「1種類あたり30枚程度」を推奨しています。そのほか、画像形式やサイズなどの詳細については、公式ドキュメントを参照してください。
今回、わたしたちが実際に学習させた画像の一例がこちらになります。できるだけ色や柄の違ったTシャツを用意し、角度や背景を変えながら何枚も撮影を行いました。

今回「Tシャツ」として学習させた画像の例
モデルを作成してみよう
準備ができたところで、いよいよCustom Vision Serviceを使った画像分類モデルの作成に取りかかりましょう! 作成の大まかな流れは以下のとおりです。
1. モデルの設定、準備
2. 画像の登録
3. モデルのトレーニング
4. モデルのテスト
1. モデルの準備をしよう
初めにモデルの設定を行います。個人的には、ここが一番難しかったです……。
まずはCustom Visionポータルにサインインします。
Custom Visionポータル(https://www.customvision.ai/)
サインインしたら「NEW PROJECT」をクリックします。するとこのような画面が表示されます。
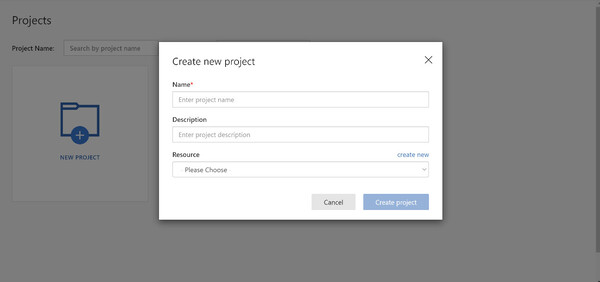
まずは「Name」の入力欄に作成するプロジェクト名(モデル名)を、「Description」にはこのプロジェクトで何を行うかの説明文を入力してください。プロジェクト名は、パッと見て何のモデルなのかがわかる名前が良いでしょう。なお、画面は英語表示ですが、この2項目は日本語で入力してもかまいません。
次の「Resource」は、Custom Vision Serviceがモデル作成に使用するリソースを選択する項目です。初めて利用する場合はプルダウンメニューに何も表示されないので、右上の「create new」をクリックして新規に作成します。
リソースを新規作成する画面(Create New Resource)が表示されるので、リソースの名前を入力し、サブスクリプションは事前に準備したものを選択します。この後にリソース名を使う場面は特にないので、任意のリソース名を指定してください。なお、リソース名に使えるのは英数字と記号のみです(日本語は使えません)。
そして、リソースの用途を指定する「Kind」では「CognitiveServices」を、料金プランを指定するPricing Perは無料の「F0」を選択してください(筆者はKindの指定で違う項目を選んでしまい、後編記事で紹介するPower Appsとの連携ができず、やり直すことになりました……。くれぐれもご注意ください)。
このリソースが属する「Resource Group」は、既存のリソースグループを選択するか「create new」をクリックして新規作成します。リソースグループを新規作成する際も、「Kind」では「CognitiveService」を、「Pricing Per」は無料の「F0」を選択します。
それぞれ「create」ボタンを押してリソースが作成できたら、プロジェクトを作成する画面に戻ります。
ここからがモデルを新規作成する操作となります。作成するモデルが該当する「Project types」「Classification types」「Domains」を選択していきます。
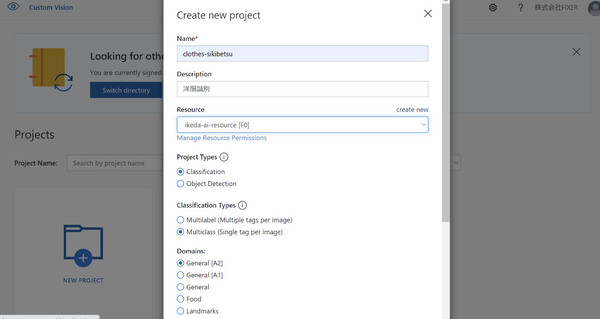
Project Typesでは、このモデルが画像分類(Classification)と物体検出(Object Detection)のどちらを行うものなのかを選択します。今回は画像分類を行うものなので「Classification」を選択します。
Classification Typesは、1つの画像に対して複数のラベルを付与する「Multilabel」と、1つのラベルのみ付与する「Multiclass」が選択できます。今回は「Tシャツ」「ジャケット」など、衣類の種類を表すラベルのみ使いますから「Multiclass」を選択してください。
Domainsでは、分類の精度を高めるために、どのような画像を分類対象とするのかを指定します。今回は「General A2」を選択します。Generalは汎用的な画像分類を行えるものなので、迷ったらこれを選択しましょう。また、Generalにも「A1」「A2」がありますが、短時間でちゃちゃっと分類させたい場合はA2を、時間をかけて高精度な分類を行いたいときはA1を選択してください。「Food」「Landmarks」など、そのほかのドメインについては公式ドキュメントをご覧ください。
選択する項目が多く、初めてモデルの設定を行う際は戸惑ってしまうかと思いますが(筆者もまったくわからず、ここに一番時間がかかりました……)、上記のとおりに行えば、スムーズにモデル作成の設定ができると思います。「Create」ボタンを押したら、モデルの設定は完了です!
2. 画像を登録してみよう
Custom Visionポータルには、新規作成したプロジェクトが表示されます。これをクリックして次の画面に進み、モデルの学習(トレーニング)作業を行います。ただし、手順はたった2つだけです!
①タグの登録
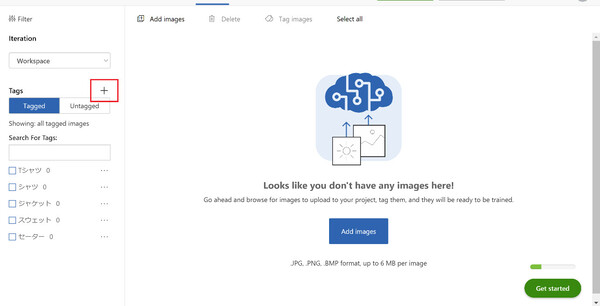
まずは、学習させる画像に付与するためのタグを登録します。タグとは、前回の記事で説明したラベルのことです。「②画像の追加」の後からタグを登録することもできるのですが、先にすべてのタグを用意しておいたほうが作業を進めやすいと思います。
左サイドバーの「Tags」にある「+」ボタン(下の画像の赤枠部分)をクリックして、「Create a new tag」ウィンドウで使用するタグを登録します。今回は「Tシャツ」「シャツ」「ニット」「スウェット」「ジャケット」という5種類のタグを登録しました。
②画像の追加
続いて、モデルに学習させる画像を追加します。
画面上部の「Add images」をクリックし、ファイル選択ウィンドウでアップロードする画像を選択します。このとき、Ctrlキーを押しながらクリックすると複数ファイルをまとめて選択できますので、TシャツならTシャツと、同じ種類の画像はまとめて選択するとよいでしょう。
選択し終えると「Image upload」という画面が表示されます。ここで「My Tags」欄をクリックすると、先ほど登録したタグがプルダウンメニューで表示されます。画像に指定したいタグを選んだうえで「Upload ○ files」をクリックすると、画像がタグ付きでアップロードされます。
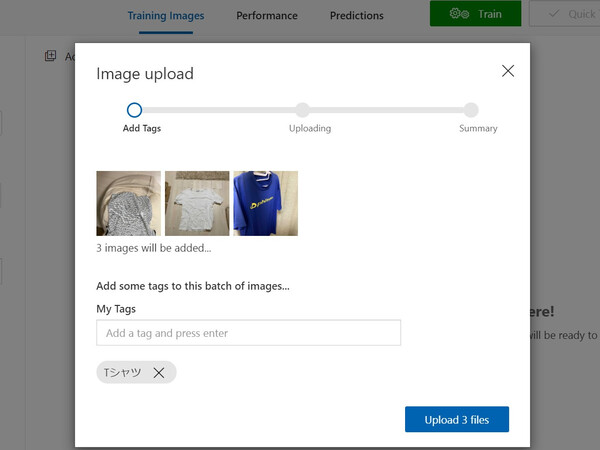
用意した画像をすべてタグ付きでアップロードしたら、画像の登録は完了です!
3. モデルをトレーニングしよう
最後に、登録した画像をモデルに学習させるトレーニングの処理を行います。トレーニング処理は、Custom Visionポータルの画面上部にある「Train」から実行できます。
Trainをクリックすると「Choose Training Type」という画面が表示されます。ここでは「Quick Training」「Advanced Training」を選択できますが、今回は短時間でトレーニングできるQuick Trainingを選択して「Train」をクリックします。なお、Advanced Trainingを選択すると、少し時間はかかりますが、より精度の高いモデルを作成できます。
作業はこれだけで、あとは3~5分待つとモデルのトレーニングが完了します。これで画像分類モデルが完成しました!
4. いざテスト!
トレーニングが完了したら、作成したモデルの分類精度などを評価する画面が表示されます。実際に、このモデルでうまく分類できるのかどうかを確認してみましょう。
ポータル画面右上の「Quick Test」から、モデルのテストが実行できます。クリックすると、テストを実行する「Quick Test」画面に移ります。「Browse local files」をクリックして、テスト用の画像(学習に使っていない画像)を選択すると、テストが実行されます。画面右下の「Predictions(予測)」欄に、画像の分類結果がパーセント表示されます。
学習させる画像の枚数で分類精度がどのように変わるのかを検証するため、今回は、画像を各種5枚ずつ学習させたモデルと、各種30枚ずつ学習させたモデルを用意して、それぞれのテスト結果を比較してみました。
まず、各種5枚ずつ学習させたときの結果がこちらです。
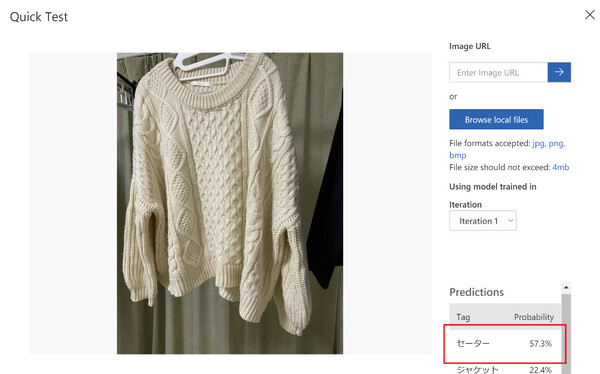

一応「セーター」には分類できていますが、セーターである確率(確実さ)が「57.3%」と、精度はあまり高くありません。
続いて、各種30枚ずつ学習させたときの結果がこちらです。

セーターである確率が「99.6%」と、一気にアップしましたね! これならば精度の高い画像分類ができそうです。やはり、学習させる画像の枚数を増やすと、ほぼ確実な画像分類ができるモデルになるようです。
もしもこのテストで期待した精度が得られなかった場合は、さらに別の学習用画像を用意して、2~4で説明したモデルのトレーニングを繰り返してみてください。分類精度が高まるはずです。
次回はPower Appsアプリと連携します!
今回の中編記事では、Custom Vision Serviceでのモデルの作成方法について説明しました。プロジェクトの準備に少し手間がかかりますが、モデルのトレーニングは簡単な操作だけで行えることがおわかりいただけたかと思います。
また、学習させる画像の枚数が多いほうが、作成されるモデルの分類精度が高まることもわかりました。画像の収集も少し手間のかかる作業ですが、それでも30枚程度で済むので、個人でも十分にできると思います。
次回の後編記事では、今回作成したモデルを利用するPower Appsアプリを作成して、いよいよ「衣類をカメラで認識し、洗濯方法を提案するアプリ」を完成させます!
ここまでご覧いただきありがとうございました。ぜひ次回もお付き合いください。
■今回のポイントまとめ!
- Custom Vision Serviceを使うと、画像の登録、トレーニング、モデルのテストをするだけで画像分類モデルが作成できる
- 学習させる画像の枚数はより多いほうが、分類精度は向上する
■筆者プロフィール
・FIXER Inc. 池田英永(いけだ はなえ):入社1年目。新しいことにチャレンジして、たくさんアウトプットしていきます!
・FIXER Inc. 廣原花音(ひろはら かのん):入社1年目。いち早く技術を身につけるため、日々精進中!
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第6回
TECH
「Text Analytics」で業務日報のテキストを感情分析してみよう! -
第5回
TECH
「Custom Vision Service」と「Power Apps」でAIアプリを完成させる -
第3回
TECH
独自の画像識別モデルを作成できる「Custom Vision Service」とは -
第2回
TECH
Azureの質問応答ボットサービス「QnA Maker」を理解する -
第1回
TECH
AIと「Azure Cognitive Services」の基本を理解する - この連載の一覧へ