「見える」からわかる!システム障害の原因をあぶり出すテク 第7回
異なる視点から「見える」2つのツールを組み合わせ、迅速な解決を目指す
「QoEダッシュボード」と「AppStack」でトラブル解決してみる
2016年03月08日 09時00分更新

先ほどのノード名をクリックすると、このノード単体の詳細情報ページにドリルダウンする。ここにはレスポンス遅延の履歴だけではなく、サーバーのOS情報やCPU負荷、メモリ使用率、ディスクボリュームの使用率、さらにそれらの消費予測といった幅広い情報が入手できる。

「lab-dem-spapp01.demo.lab」ノードの詳細情報画面にドリルダウンした
詳しく見ていくと、このノードについて次のようなことがわかった。
●このノードは仮想サーバー(ゲストマシン)である
●仮想化ホストは「lab-dem-esx.demo.lab」というホスト名
●ゲストOSはWindows Server 2012 R2で、SharePointとIISが稼働中
●平均CPU負荷は低く、余裕がある
●平均メモリ使用率は90%近くなっており、非常に高い
ここでは高いメモリ使用率が気になるところだ。仮想サーバーへの割り当てメモリ容量は4GBとなっているが、これでは足りていないのかもしれない。
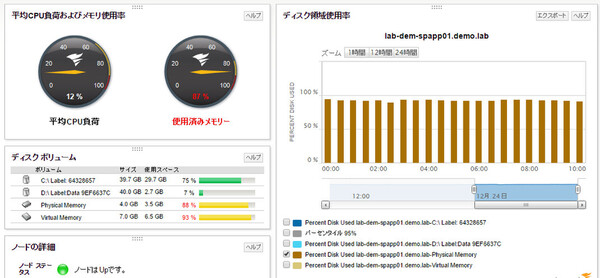
「使用済みメモリ」(左上)が90%近い。「ディスク領域使用率」でメモリ使用量の推移グラフだけを表示させたが(右上)、ずっと高いままのようだ
さらにこのページを下にスクロールしていくと、AppStackのウィジェットが見つかった。ここでは、このノードが影響を受ける、または影響を与えるコンポーネントだけが表示されている。
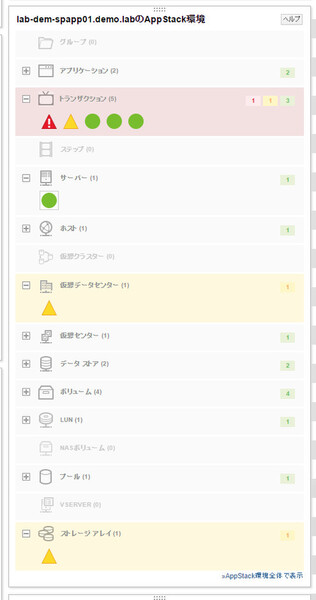
ノードの詳細情報ページ内にもAppStackウィジェットがある。このノードに関係するコンポーネントだけが表示されるのでわかりやすい
アイコンの色を見ると、このサーバー自身は緑色(正常)だが、このサーバーが影響を与える「トランザクション」に赤色(ダウン)や黄色(警告)のアイコンが並んでいる。クリックしてみると、いずれもSharePointのトランザクションであり、提供先オフィスによってはダウンしている時間帯すらあることがわかった。

警告の出ているトランザクションをドリルダウンし、可用性の推移をチェック。ダウンしている時間帯もある
再びAppStackウィジェットに戻り、このサーバーが影響を受けるコンポーネントの状態をチェックすると、「仮想データセンター」と「ストレージ アレイ」の項目が黄色のアイコンになっている。ちなみに「仮想データセンター」は仮想化ホストをデータセンターごとに、「仮想センター」はVMware vCenterごとにまとめた項目である。
仮想データセンターをドリルダウンすると、「Austin(オースティン)」データセンターにある仮想化ホスト(物理マシン)の一覧が確認できる。ここでは前述の「lab-dem-esx.demo.lab」ホストだけが、メモリ使用率が90%を超えている深刻な状態であることがわかった。
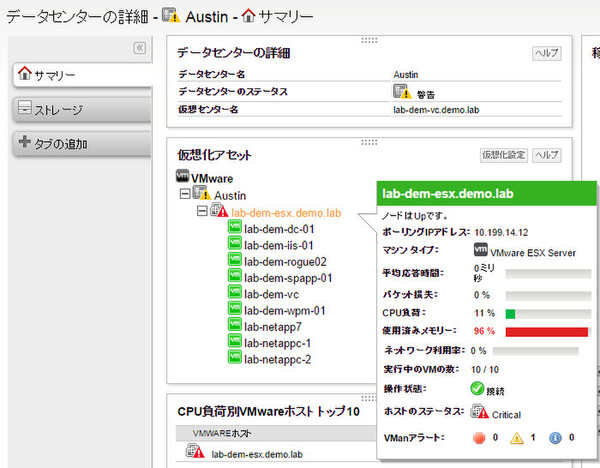
仮想化ホスト「lab-dem-esx.demo.lab」の状況をチェック。メモリ使用率が非常に高く警告が出ている
この仮想化ホストをドリルダウンして調査すると、32GBの物理メモリを搭載しているものの、合計10のゲストマシンが稼働しており、メモリ不足の状態に陥っている。これが原因と判断してよいだろう。
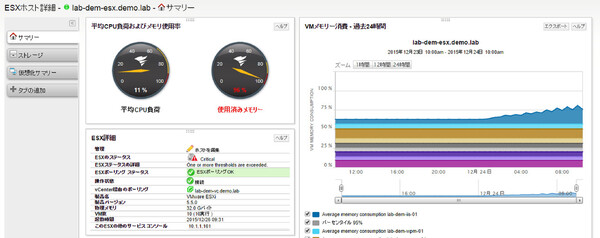
仮想化ホスト「lab-dem-esx.demo.lab」の詳細情報ページにドリルダウン。やはりメモリ使用率が高くなっている
* * *
以上の調査によって、今回のSharePointサーバーのレスポンス遅延の原因は、SharePointの仮想サーバーをホストしている物理マシンの搭載メモリが不足していることだとわかった。あとはサーバー/仮想化の担当者に引き継いでより詳しい調査を依頼し、搭載メモリの増強、あるいは稼働している仮想サーバーを減らす(仮想サーバーの別ホストへのマイグレーション)といった対応を取ってもらうことになるだろう。
このように、QoEダッシュボードとAppStackを使うことで、障害原因の切り分けをスムーズかつ明解に行うことができる。ネットワーク担当者やストレージ担当者など、関係のない担当者の手をわずらわせることもなく、そのコスト効果はかなり大きいはずだ。
※注:本記事中で使用している画面はデモ環境のものであり、実際の通信環境とは異なります。
(提供:ソーラーウインズ)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第6回
デジタル
アプリ障害の原因はインフラのどこに?「AppStack」が簡単解決 -
第5回
デジタル
適切なNW増強計画のために「NTA」でトラフィック量を可視化 -
第4回
デジタル
「UDT」で持ち込みデバイスのネットワーク接続を監視する -
第3回
デジタル
何十台ものネットワーク機器設定、その悩みを「NCM」が解消する -
第2回
デジタル
ネットワーク?サーバー?QoEダッシュボードで障害原因が見える -
第1回
デジタル
なぜ、いま運用管理の“バージョンアップ”が必要なのか - この連載の一覧へ
")













で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")
























