CData SyncのCDCでクラウドDWHの真の実力を開花させる
「データは昨日のまま」で大丈夫? クラウドDWHのデータパイプラインを刷新して、意思決定の「速さ」を手に入れる
提供: CData Software Japan

DXやデータドリブン経営、そしてAIの進化で、データ分析の中心的な存在であるクラウドDWH(Data Ware House)の導入が加速している。しかし、クラウドDWHに移行したものの、経営や現場部門から求められているリアルタイムな分析ができずに困っている現場は多い。果たして、どこに問題があるのか? クラウドDWHの真価を引き出すデータパイプラインのあるべき姿とそれを実現するCData Syncについて、CData Software Japanの宮本航太氏、杉本和也氏に話を聞いた。

CData Software Japan 宮本航太氏
成長著しいクラウドDWH でも、そのメリットを企業は得られているのか?
AIデータクラウドの時代が到来し、クラウドDWHの利用は加速している。DWHとは、データベースの構造化データやアプリケーション非構造データなどを時系列で集約した専用データベース。従来はオンプレミス型で運用することが多かったが、昨今は拡張性や可用性に優れたクラウド型サービスが増え、企業のデータ分析の中心的な存在となっている。
Grand View Researchの市場調査で見ても、クラウドDWHの成長率は年平均23.5%と極めて高い。Google BigQuery、Amazon Redshift、Azure Synapse Analyticsなど3大クラウドのサービスはもとより、SnowflakeやDatabricks、Treasure Dataなどサードパーティ製品もあわせて成長し、市場を拡大しているのが注目ポイント。現在、8000億円規模の市場だが、2030年には4.5兆円規模に膨らんでいくという。
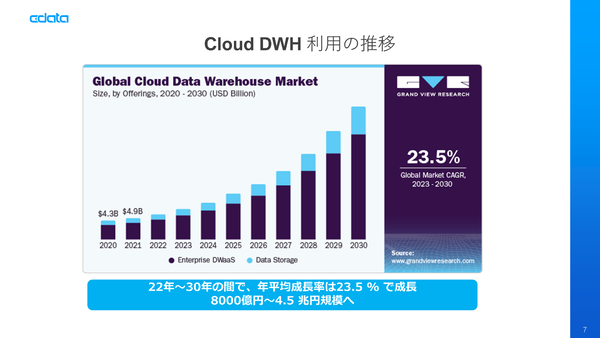
グローバルで加速するクラウドDWHの成長
なぜ多くの企業が既存のオンプレミスDWHをクラウドDWHに移行したのか? まずはバッチ処理を前提とした既存のDWHの限界だ。データ量に比例して処理時間は増え、クエリをかけると、本番システムに負荷も集中してしまう。データ分析を行なうビジネス部門からはリアルタイムな分析や意思決定が求められ、IT部門からは本番システムの安定した運用のために負荷の軽減が求められる。そして経営陣からはコスト対効果の高い経営判断基盤が要求される。こうした課題に対して、クラウドDWHは最適……なはずだ。
これに対して、「多くの企業でDWHは宝の持ち腐れになっているのではないか?」と指摘するのは、CData SyncやCData API Serverなどのプロダクトマネージャーを務める宮本航太氏だ。
宮本氏は、長らくサポートを担当してきた。「クラウドDWHにデータを集約したいという声は年々増えています。2024年は全体の問い合わせの4割がクラウドDWH関連だったのですが、2025年は6割にまで拡大しています」と語る。ここで聞くのは、クラウドDWHにまつわるさまざまなユーザーの悩みだ。
「せっかくDWHを刷新したのに、見ているデータは以前と変わらず、しかも昨日のデータまでしか見られない」
「連携に時間がかかるため、ジョブの頻度が上げられない」
「新規連携シナリオを追加したいのに、既存の連携プロセスがスパゲッティ状態でメンテナンス性や拡張性が改善しない」
「データソース側で削除したレコードが同期先に反映されない」
これが前述した「宝の持ち腐れ」という状態だ。杉本氏は、「テラバイト級のデータが0.7秒で処理できても、見ているデータが1週間前だったら、分析の意味はありません。パフォーマンスがよいサービスを使っているはずなのに、それを活かすためのデータが用意できないということを理解してもらいたい」と語る。
本当にやってきた「ビッグデータの時代」 課題はデータパイプライン
本来、クラウドDWHやAIが実現するのは、ビッグデータからビジネス上の価値(インサイト)を得ることだ。ビッグデータという概念は1990年代からあり、本格的に使われるようになったのは、今から15年ほど前だ。DXやデータドリブン経営などの隆盛を経て、現在はまさにそのビッグデータの時代が到来したと言える。
ビッグデータは単なる「量(Volume)」だけではなく「多様性(Variety)」「速度・頻度(Velocity)」「正確さ(Veracity)」の4つを備えている必要がある。多くの企業でクラウドDWHが宝の持ち腐れになっているのは、この4つの要件を満たすためのデータパイプラインが構築されていないからだ。
クラウドDWHだけを最新のサービスに入れ替えても、データパイプラインが古いままでは要をなさない。「せっかく倉庫が最新でも、配送ラインが詰まれば出荷は遅いはずです。だから、われわれがやらなければならないのは、データパイプラインのモダナイゼーションなんです」と宮本氏は指摘する。
大量のデータを高速に処理し、多種多様なシナリオで、鮮度の高いデータをニアリアルタイムに分析する。これを実現するためのデータパイプラインのモダナイゼーションに最適なのがデータベース上の変更を自動検知・転送するCData Syncだ。
データソースに負荷をかけないCData SyncのCDC
クラウドDWHにおけるビッグデータの課題で、特に重要になるのは量と速度。そのため、データパイプラインのモダナイゼーションにおいては、データの取得とクラウドDWHへの流し込みを改善する必要があるという。
これを実現するためのポイントは、ETL中心からELT+CDCへのアーキテクチャの刷新だ。従来の変換プロセスは、基幹システムのデータを取り込み、データ連携ツールで変換・加工・クレンジングなどのETL処理を行ない、クラウドDWHに流し込むというアプローチだ。実はこのETL処理のフローが複雑で重いがために、量や速度の要件を満たすことができないという事例が多い。
一方で、CData Syncが提唱するELT+CDCの方式は、生データや前処理済みデータをクラウドDWHに転送し、クラウドDWH上でSQLによる変換処理を行なうという方法だ。加えてデータソース側の変更を検知し、ニアリアルタイムに転送するCDC(Change Data Capture:変更データキャプチャ)で遅延を最低限に抑える(関連ページ:。「大量のデータを全件SQLで取得するのはもはや無理があります。差分だけを取得し、残りをトランザクションログから取得する方法に変えていく必要があります」と宮本氏は指摘する。
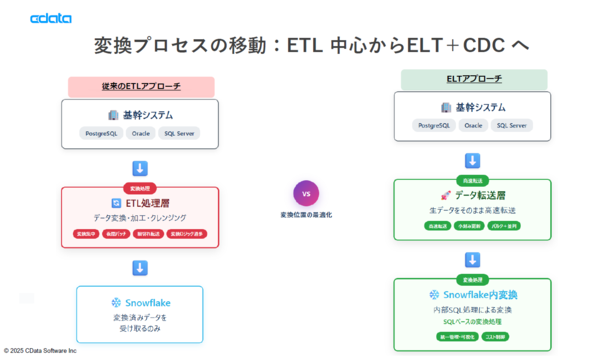
ETLからELT+CDCへ
CDC自体は汎用のアプローチではあるが、更新日時でクエリを実行するクエリベース、変更時に専用テーブル(履歴テーブル)に変更履歴を記録するトリガーベース、そしてトランザクションログから変更情報を読み取るログベースの3つがある。どれも一長一短があるが、従来の連携ツールは実装の容易なクエリベース。ただ、この方法だとデータソース側に負荷がかかり、削除が検知できないという課題がある。トリガーベースは履歴を記録した履歴テーブルが別途で必要になるため、データソースのスキーマ変更の際に設定のし直しが必要になる。
このうちCData Syncが採用するのは、ログベースのCDCだ。この方式はトランザクションログを常時読み続けるので、実装の難易度が高い。しかも一定間隔のスケジュールで読みに行く方法だと、取得するタイミングによっては大量の変更レコードの抽出に時間がかかってしまう。しかし、CData Syncではログを常時トレースするため、変更データを漏れなく抽出でき、リアルタイム性を確保することができる。
宮本氏は、「大規模で高い可用性が必要なシステムの場合、本番データに手を入れないログベースのアプローチが現実的だと思います。トランザクションログには削除されたデータも残っているので、これらを検知して、同期先にリアルタイムに近い形で実現できます」と指摘する。
この記事の編集者は以下の記事もオススメしています
-
sponsored
目指せマネーボール さくらインターネットの現場が始めたデータドリブン革命 -
sponsored
サーバー知らなくてもAPIでデジタル開発 戸田建設にDXの理想像を見た -
sponsored
NetSuiteやShopifyのデータ統合までCData Syncで実現したジョンマスターオーガニック