




米国時間の8月21日からHot Chips 34がスタートする。今年もいろいろと目玉は多く、AMDがRyzen 6000とInstinct MI200と400G Adaptive SmartNIC SOC、インテルがPonte VecchioとMeteor Lake/Arrow Lake、それにXeon D 1700/2700、NVIDIAがHopper、Glaceに加えNVLink Network Switchの発表を行なう。
他にも、先日紹介したLightmatterが、Passageの説明をするほか、個人的にはBiren TechnologyのBR100 GPGPUやJuniperのExpress 5、ArmのMorello Evaluation Platformなどが気になるところだし、Tesla MotorのDOJOも内容によっては記事で取り上げたいと考えている。
目立たないところで言えば、MediaTekのDimensity 9000もなにげにArmのTotal Compute Solution 2021を代表するSoCの1つであり、これもArmの最近の動向とあわせて紹介してもいいかもしれない。
ということでHot Chipsは業界から注目を集めているイベントであるのだが、その直前の8月17日~19日に、同じIEEEのHot Interconnectsというイベントがあるのは案外に知られていない。参加者数で言えばHot Chipsから一桁落ちるので仕方がないのだが、こちらはインターコネクト関連ならなんでもということで、今年も(筆者的には)非常におもしろいネタがいろいろ出てきている。
CXL 3.0の話や、まだOMIが諦めてない(!)などをはじめ、今年のテーマは“Disaggregation Leading to Reaggregation”(解体と再構築)なのだが、それに沿ってイーサネットのトランシーバーの構成に関する再提案など、なかなか参加していて楽しい話題が多い(こういうのを喜ぶ人があまり多くないのはわかっている)。その中で目を引いたのでご紹介したいのが、HPEによるSlingshotの解説である。

買収に次ぐ買収から生まれた
独自のインターコネクト「Slingshot」
HPE(旧Cray)のSlingshotは、HPCなどの大規模システムの中核をなす独自のインターコネクトである。もともとのCrayはCray-1から始まるベクトルプロセッサーをベースとしたシリーズで、連載275回から連載279回まで説明している。このシリーズを手掛けていたCRIは1996年にSGIに買収される。ただそのSGIも行き詰まり、Cray部門は2000年にTera Computerに売却される。
Tera Computerは独自のMTA-1や後継のMTA-2を開発していたが、Cray部門の買収に合わせて社名をCray Inc.に変更している。この結果として新生Cray Inc.は、SGI時代のMPP(Massive Parallel Processor)とMTAシリーズのSMT+MPP、2種類のスケーラブルなアーキテクチャーに関する一定の知見を蓄積していたと言える。
これが生かされたのが、2002年10月に契約を獲得したASCI RedStormである。このRedStormで、CrayはSeaStar Linkと呼ばれる独自の3次元メッシュのリンクを開発。最終的に1万880個のOpteronをこのSeaStar Linkで接続することで、高い実効性能を叩き出すに至った。
このSeaStar Linkはその後Gemini/Ariesという後継のインターコネクトに進化するが、2012年にCrayはこうした独自インターコネクトのハードウェアとソフトウェアの資産一式、さらにはエンジニアも含めた部門全体をインテルに売却する。
では一体Crayはその後どうしたか? というと、2018年10月末に発表したShastaで、まったく新しいSlingshotインターコネクトを発表する。実はこのShastaを最初に採用したのが、NERSC(国立エネルギー研究科学計算センター)のNERSC-9ことPerlmutterである。
最初のSlingshotであるSlingshot-10は、実はハードウェア的にはイーサネットそのものである。SlingshotのチップはMellanoxのConnectX-5で、2レーンで200Gbpsの帯域を持つ。これと組み合わせるスイッチの方はBroadcomのTomahawk 3というスイッチで、これで64ポート×200Gbpsの容量を持つ。
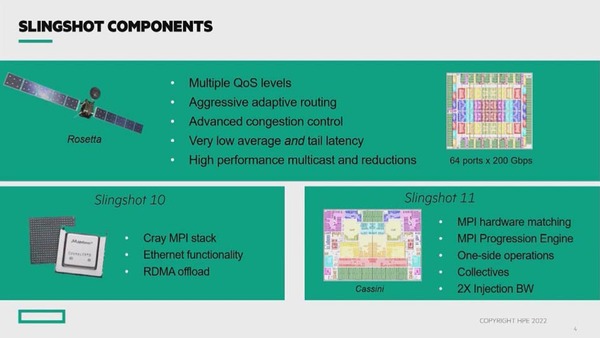
左下のSlingshot 10チップにMellanoxのロゴが入っているのがわかる。Tomahawk 3は、Rosettaという名前になっているが、中身は一緒である
ただし普通のイーサネットとして使うのではなく、HPC向けの独自インターコネクト向けにドライバーおよびその上位のネットワークスタックの最適化を図ったものである。そもそもネットワークトポロジーそのものが独自である。DragonFly Topologyと呼ばれるもので、2008年にJohn Kim博士(現在はKAISTの教授を務めているが、当時の所属は米ノースウェスタン大学だった)らが考案した方式である。Dragonflyの構造を簡単に説明したのが下の画像である。
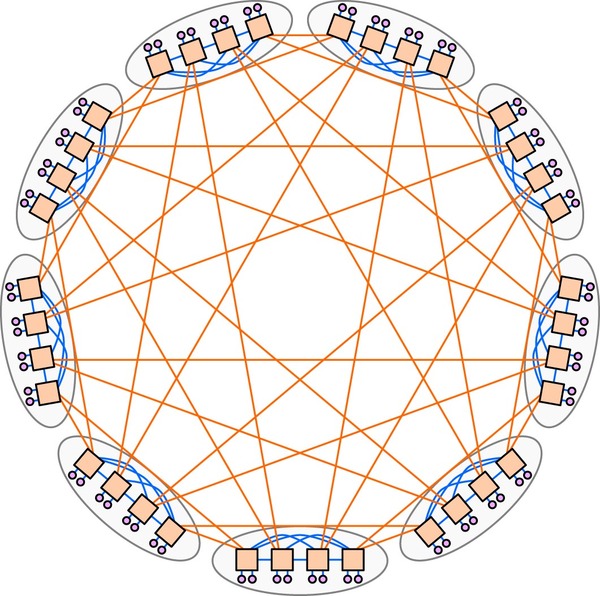
○がノード、□がスイッチというかルーターである。Kim博士の論文の表記に従えば、まず小さなグループ(8ノード/4ルーター)を作るが、ここではすべてのルーターが相互接続されているので、グループ内であれば2ホップでノード同士が通信できることになる。
一方でグループ同士もお互いに相互接続されている。この結果として、グループをまたぐ通信は、最速で2ホップ、最低でも4ホップ、平均で言えば3ホップほどで接続できることになる。
実をいうと、このDragonflyを最初に実装したのは、Ariesの世代である。Ariesの場合、このDragonflyに最適化した特殊なネットワークコントローラーを採用していた。これに対し、Slingshot-10では汎用のイーサネットコントローラーを使っている関係でAriesに比べると多少効率は落ちているが、その代わりにイーサネットとの互換性は高い。Perlmutterでは、このSlingshot-10が利用されたわけだ。
なおNERSCのインターコネクトに、“Each GPU-accelerated compute node in cabinets with Slingshot 10 interconnect fabric is connected to 2 NICs, allowing each node to have 2 injection points into the network. This configuration is sometimes described as dual injection or dual rail. A GPU-accelerated compute node in cabinets with Slingshot 11 fabric is connected to 4 NICs.”とあり、Slingshot-10とSlingshot-11が混在していることがわかる。
またAuroraのプロトタイプ的な位置付けになる、アルゴンヌ国立研究所のPolarisにもSlingshot-10が採用されているが、こちらもSlingshot-11にアップグレード予定とされている。
ということでやっとHot Interconnectsの発表につながる。今回(Crayを買収した)HPEが発表したのは、Slingshot-11である。つまりSlingshot-10の後継となる製品だ。
この連載の記事
-
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 - この連載の一覧へ











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")













