



ロードマップでわかる!当世プロセッサー事情 第764回
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ
2024年03月25日 12時00分更新

消え去ったI/F史は中断し、今回と次回は、3月18日からサンノゼで開催されたGTC 2024におけるNVIDIAの発表、特にBlackwellについて解説したい。
B100のダイサイズは850平方mm前後?
2023年10月に行なわれた投資家向けカンファレンスで示されたのが下の画像にあるロードマップである。今回GTC 2024で発表されたのはB100、つまりH200の後継となる新サーバー向けチップとこれを利用した派生型である。
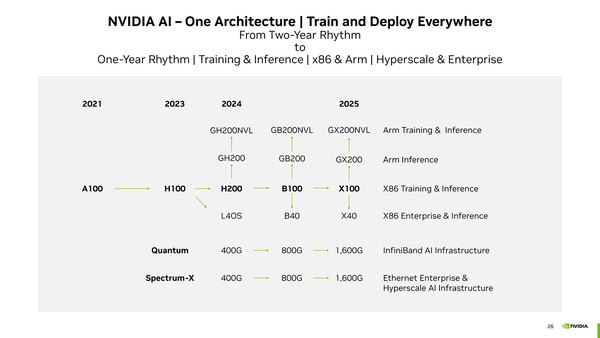
昨年発表されたNVIDIAのロードマップ。H100とH200は同じ2023年に発表はされているが、発売は2024年ということでこのロードマップになっている。B100も今年中に発売される予定で、X100は2025年になる
最初にお断りしておくと、本稿ではB100とひとくくりに説明しているが、これは上の画像で"B100"と記されているのでこれを使っているだけで、実際にはB100/B200という2種類の製品名が混在、しかもB200には2種類のSKUがある「らしい」。
まだ正式に商品名とスペックが公開されていないので、ここではBlackwellアーキテクチャーを搭載したチップの総称として"B100"と説明することにする。
まずB100の元になるBlackwellチップであるが、製造はTSMC 4NPである。4N"P"がなにを意味しているのか公式には明らかにされていない。ただH100/H200世代は、TSMCのN4をベースにしたNVIDIAカスタム版であるTSMC 4Nプロセスを採用していた。
同じようにBlackwellでは、TSMCのN4P(N4の高性能版)をベースにNVIDIAカスタム版プロセスを利用しており、それがTSMC 4NPではないか? という気がする。トランジスタ数は1040億個で、H100が800億個と説明されていたので、3割程トランジスタ数は増えたことになる。

Blackwellの左側は外部へのI/F、上下端がHBM3e I/F、右がインターコネクトといった感じ。微妙に上下対称になっていない(右下ブロックの上端の構造が他と違う)のがおもしろい
ちなみにダイサイズは後で推定するが、そもそもH100の時点でダイサイズは814mm2と発表されているため、単純に1.3倍にすると1058.2mm2となり、Reticle Limitをはるかに超えてしまう。トランジスタ数とダイサイズは単純に比例しない(構成によって変わる)から、実際にはReticle Limitの限界(26mm×33mmの858mm2)に限りなく近い程度に収まっていると思われる。
これは逆に言えば、SRAM(L1/L2/L3キャッシュ)の容量はH100からそれほど増えておらず、演算器のみ増やした、あるいは演算器の複雑さが増したことを示唆していると考えられるが、このあたりはホワイトペーパーが出てもう少し正確な情報が手に入らないとはっきりしたことは言えない。ただ"The Largest Chip Physically Possible"とまで言ってるので、限界にチャレンジしたのは間違いなさそうだ。
ちなみに純粋に技術的に言えば、Reticle Limitを超えるサイズのダイを作ることは不可能ではない。例えばチップの上半分と下半分に分けて、それぞれ別のマスクで露光をすることで、Reticle Limitを超えるダイを露光することは可能だ。
ただしその場合、2回の露光のずれが1nm未満のオーダーで一致していないと、使い物にならないチップもどきが完成する。しかもこれをトランジスタ層(ここだけで10回を超える露光がある)だけでなく配線層まで全部実行するので、露光の回数は下手をすると3桁に行きかねない。
このどこか1回だけでもずれたらパーなわけで、歩留まりは猛烈に低いと予測できる。したがって、さすがにそこまでの冒険はNVIDIAもやらないだろうし、そう考えるとダイサイズはReticle Limitにかなり近い数字、850mm2前後になるだろう。
Blackwellのダイはかなり大きいが、B100はこのBlackwellのダイを2つ組み合わせた格好となる。要するにAMDのInstinct MI250Xと同じ構成である。2つのダイの間は独自のインターコネクトで接続される格好だ。

Blackwellのダイを2つ組み合わせたのがB100。Full-cache coherencyというのも冷静に考えると不思議な表現ではあるのだが、意味はわかる
Full-cache coherencyの意味は、2つのダイのおそらく2次キャッシュ同士をダイの外で接続しているものと思われる。もともとHopperの世代では、2次キャッシュは物理的に2つに分割され、これがダイの内部でつながっている構造だった。

白っぽい部分がSMで、その間の黒っぽい部分が2次キャッシュと考えられる
B100では、1つのダイには2次キャッシュが1つのブロックとして構築されているが、2つのダイの2次キャッシュが外部のインターコネクト経由で相互接続されているのだろう。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















