スキルゼロのエンジニアが1年で運用デスマを解消した話 第4回
いよいよ導入間近!障害検出を超えるNPMの価値を知る
単なる障害検知じゃ意味ない!現場のエンジニアがNPMをつっこむ
2015年11月06日 07時00分更新

ソーラーウインズのネットワーク管理ツール「ネットワーク・パフォーマンス・モニター(以下、NPM)」の導入を実現すべく、データセンターの妖精ウインズちゃんとともに現場のエンジニアにデモを披露する西牧。果たして障害対応は楽になるのか?現場のエンジニアが激しくつっこむ。
トップ10リストとアラート抑制の仕組みが便利
前半のデモでNPMの導入を披露し、ネットワークマップまで作成した西牧。休憩後は障害対応を披露することになった。休憩中に、ウインズと紹介する機能について最終チェックする西牧。デモ環境の最終チェックを兼ねて、下の検証ルームで打ち合わせだ。
ウインズ:とりあえず導入が簡単なことは理解できてもらったようね。ネットワークマップもなかなかきれいにできたじゃない。御社のおんぼろルーターが各地で火を噴く様が見られるかと思うと、まったく見物ね。
西牧:そんなおんぼろばかりじゃないですよー。でも、結局ネットワーク機器って、入れ換えるのに迷いが生じるんですよね。帯域を増やすだけでいいのか、スタックしてキャパシティ増やすのか、機種自体をアップグレードするのか。いろいろ選択肢があっても、原因がわからないから決められない。かと言って、買い換える理由になるデータもない……と。

デモの間の休憩時間で、西牧とウインズの作戦会議。トップ10リストとアラート抑制が便利!
ウインズ:そんな即決力のにぶったエンジニアのためにNPMの「トップ10リスト」があるんじゃない。NPMだったら、ノードごとのパケットの損失率、CPUやメモリの使用率、トラフィック別のインターフェイス、ポートのオペレーションなどがまとまって見られるのよ。あれ見て、なんにも感じないエンジニアだったら、さっさと転職すべきね。
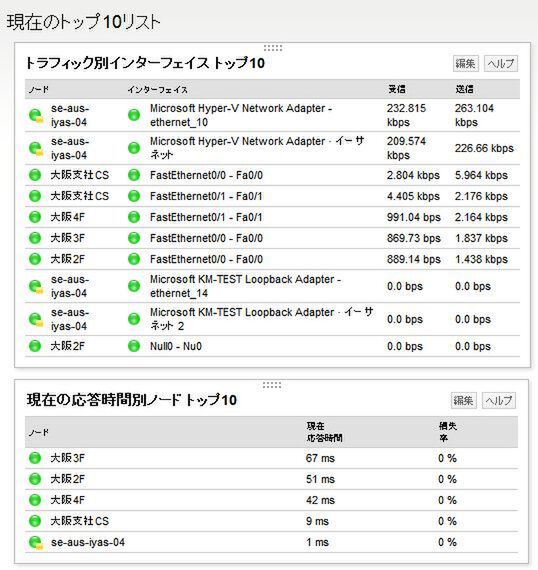
インターフェイスごとのトラフィックをトップ10リストで表示
西牧:トップ10リスト便利ですよね。昔のツールはあんなのなかったです。あと、アラート抑制のための依存関係グループがなにげに便利です。NPMでネットワーク機器の接続構成を理解させ、監視対象が疎通しているかわかるんです。
ウインズ:西牧、マニアックねえ。そこまで使い込んでるとは思わなかったわ。
西牧:うちの業務ネットワークでは、東京から大阪の拠点を監視しているんですが、結局大阪のエッジルーターがダウンしちゃうと、その先の機器まで監視できなくなるんです。当然、監視が疎通できないと、嵐のようにエラーメッセージが出てきちゃうんです。
ウインズ:でも、依存関係を設定すると、大阪のエッジルーターが落ちても、その先の機器は「疎通しない」って扱うのよね。アラートはエッジルーターだけなので、管理者も切りわけが簡単ってわけよね。
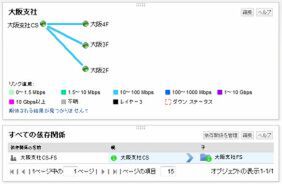
エッジルーターがダウンしてしまうと本来は監視できないはずだが……
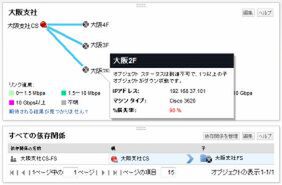
障害を起こっても、その先はあくまで「疎通していない」と通知する
西牧:そうなんです。こういうところもきっちり説明しないとな。
ウインズ:おっ、西牧。タイムアップだわ!プレゼンルームに戻るわよ。
サービス断がユーザー経由なら死活監視の意味はない?
NPMの伝道師でもあるデータセンターの妖精ウインズの協力もあり、製品概要や機能についての説明もつつがなくこなしてきたが、現場のエンジニアたちのツッコミは厳しい。Q&Aでは、現場の障害対応での課題が赤裸々に披露された。
西牧:前半のデモで見たように、ソーラーウインズのNPMは導入や設定も容易で、SNMP対応のネットワーク機器に対応しているので、幅広く死活監視できます。対象のデバイスやインターフェイスを絞り込む機能もあるため、効率的な監視が可能になります。
エンジニアA:ちょっといいですか? 正直、無料ツールでも死活監視はできるし、アラートも上がってきます。ただ、問題なのはアラート上がってくる前に、ユーザーから連絡が来てしまうことなんです。しかも1人じゃなく、同時にいっぱい。スイッチに故障が発生すると、別にSNMPのトラップが来なくても、気がついたユーザーから電話やメールが届くんです。だから、単純に障害を知らせてくれるツールであれば、現場ではそれほど役立ちません。むしろどこに問題があるか、次にこける部分はどこかわかるほうが重要です。

SNMPのトラップの前より、エンドユーザーからの「つながらないんですけど!」の電話の方が早い
エンジニアB:現場で難しいのは、実は障害か、仕様かで迷う点です。たとえば、「ネットワークインターフェイスが過負荷」というアラートは重要ですが、通信している限り、障害とは言い切れません。そういうデザインだからです。その場合、LAGで帯域を増強すれば、対処できるかもしれない。でも、CPUもメモリも過負荷だった場合、やはり機器自体のアップグレードが必要です。こういう判断をするための情報を私たちは求めていたりします。
西牧:なるほど。NPMを使っていて僕が感じているのは、単純な「ポートが壊れた」という情報だけでなく、まさにそういう判断のための情報が得られるということです。たとえば、監視対象のインターフェイスの利用状況トップ10を見れば、負荷の原因がどこにあるか突き詰められるので、スイッチをスタックすればよいのか、バックプレーン自体を増強した方がよいのかわかるんです。障害対策だけではなく、障害の可能性や改善施策の情報が得られるんです。
エンジニアA:使っていないので、なんとも言えないですが、それであれば導入を検討する価値はありますね。
西牧:SNMP対応のネットワーク管理ツールは昔からありますが、収集した情報をエンジニアにわかりやすく、整理して提供するという点では、NPMはやはり新世代のツールです。ぜひ試してみませんか。

障害検知だけじゃなくて、ネットワークエンジニアが必要な情報をわかりやすく提供するNPMいいわー。
エンジニアA・B:わかりました。とりあえずは体験版を使ってみて、次の議論を始めましょう。
西牧:ありがとうございます!
ということで、いよいよ導入に大きく舵を切ることになった西牧の会社。使い始めると、そのノウハウ吸収はすさまじく、「うちの会社ではこう使えるのではないか」「こんな監視を試してみた!」といった社内ブログが相次いで投稿された。八尋部長もこうしたブログを見せながら、上司や他の部長たちを説得。結果、めでたくNPMの一斉導入が進んだという。さて、次回はアプリケーション部隊からインフラ部隊への無茶ぶりがテーマだ。
(提供:ソーラーウインズ)
この連載の記事
-
最終回
デジタル
ソーラーウインズの統合監視システムで運用は本当に変わったのか? -
第6回
デジタル
西牧とウインズ、アプリ開発部隊“19階”からの要求に応えられるのか? -
第5回
デジタル
隣のシステムはオールグリーン?サーバーだって監視したい -
第3回
デジタル
エンジニアだらけの社内デモ!ネットワーク監視は簡単に始められる -
第2回
デジタル
ネットワーク管理ツールなんて10年早いは本当か? -
第1回
デジタル
現場は戦場だった!インフラ運用に配属された僕の悲劇 - この連載の一覧へ
")











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")












