




A64FXは13コア×4の52コア構成
NVIDIAを上回る性能/消費電力比を記録
チップ全体としては52コアの構成である。13コア×4の4つのグループが、お互いにNoCで接続され、その外側に32GBのHBM2と3次元トーラスのTofu Interconnect、さらに周辺回路接続用のPCIe x16が用意される。
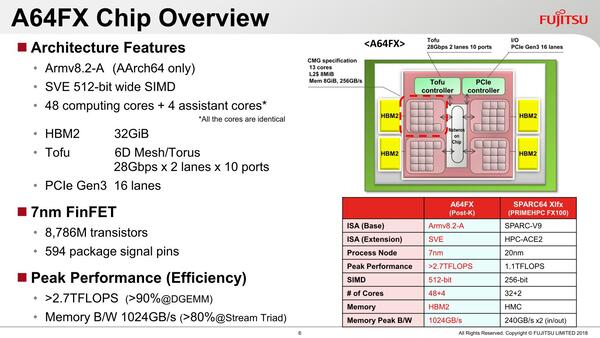
48コアで32GBのメモリーということは1コアあたり1GBもメモリーがないので、このあたりがボトルネックになりそうな予感はある。もっとも、では外部にDDR4を大量につなぐか? というと、パッケージが相当大型化するうえ(ピン数が相応に必要)、プログラミングもより難易度があがる。このあたりは熟慮の結果であろうとは思う
13コアのうち1コアは外部の通信や制御用に割り当てられ、計算処理は48コアで行なうことになる。動作周波数は1.8GHzか2GHzになっており、仮に1.8GHzなら理論性能は以下のようになる。
- FP64 : 8×2×2×48×1.8GHz=2764.8GFlops
- FP32 : 16×2×2×48×1.8GHz=5529.6GFlops
- FP16 : 32×2×2×48×1.8GHz=11059.2GFlops
- INT8 : 64×2×2×48×1.8GHz=22118.4Gops
この計算は“SVEで1サイクルに扱える演算数”דSVEユニットの数”ד1回の演算における計算量(FMA/Dot Productsでは2演算相当になる)”×コア数×動作周波数というものだが、富士通もほぼこれに準じた数値を示している。
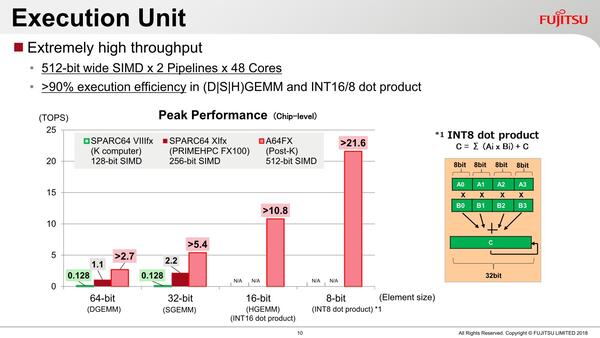
あくまでこれはピーク性能で、実効性能はまた別の話である。ちなみに富士通の試算は2.0GHz駆動だが、効率が90%とした場合の数字である(結果としては1.8GHz駆動で効率100%と変わりがないが)。
富岳の場合、以下のような形をとる。
- 定格動作周波数を2GHz、ブースト動作周波数を2.2GHzに設定。
- 1ノード=1CPU。CMU(2ノード搭載のブレード)8枚を、1つのBoB(Bunch of Blades)に搭載する。
- BoB3つを、1つのShelfとして搭載、これを8つ、1本のラックに実装する。

1台のラックに384ノードが搭載される格好。もう少し積んでも良さそうな気もするが、冷却効率を考えるとこのあたりが妥当なところかもしれない
画像の出典は、理化学研究所の“Post-K(Fugaku)Information”

CMUの拡大写真。DLCというのは“Direct Liquid Cooling”の略だそうだ
画像の出典は、Arm TechCon 2018における松岡教授の“Post-K:The Next Generation Arm-based Japanese Flagship Supercomputer”という講演スライド。
実際には、フル構成(384ノード)のラックが396本、ハーフ(192ノード)のラックが36本で、合計15万8976ノードでの稼働となる。おのおののノードが2.7TFlopsだとすれば430PFlops(FP64)という計算で、Exaにはやや遠いものの、現時点では圧倒的性能であることがわかる。
もちろん上には上がいるわけで、今年5月に発表されたNVIDIAのAmpereはFP64で9.7TFlopsなので、4倍とは言わないまでも3倍以上高速である。
これは実装されている演算器の数が全然違うからという話であるが、2018年に発表されたA0シリコンの実性能での数字を見る限り、NVIDIAのTesla V100を上回る(=Ampereをもおそらく上回る)性能/消費電力比であり、逆に言えば同じ電力であればNVIDIAのA100以上の公算が高い。その最大の理由はTSMCの7nmの採用、ということだとは思う。
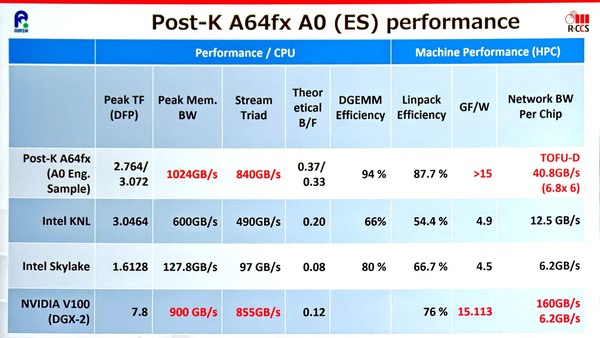
A0シリコンの実性能。GF/W(消費電力あたりのGFlops)が15「以上」、というあたりが実に悩ましい
画像の出典は、Arm TechCon 2018における松岡教授の“Post-K:The Next Generation Arm-based Japanese Flagship Supercomputer”という講演スライド。
今年のTOP500の富岳の結果を見ると、729万9072コアとあるので、上にかいたハーフノードは利用せずにフルノードだけでの稼働結果と思われる。
理論性能が51万3855TFlop/sではノードあたり3.37TFlopsとなり、これは2.2GHzのブースト時性能になる。実際は41万5530TFlopsで効率は80.9%ほど。システム全体の消費電力は2万8334.5KWとされるので、14.67TFlops/Wとなる計算で、汎用向けとしてはかなり優秀なほうだろう。
2位に入ったSummitがPower9+Nvidia V100の構成で理論効率20万795TFlops/実測14万8600TFlopsで効率は74%ほど、消費電力効率は14.72TFlops/Wで、性能はともかく消費電力効率は悪くないが、2018年から稼働してもう最適化がある程度進んでいるはずのSummitでもLINPACKの性能は74%どまり(2018年6月に初めてTOP500に登録されたときは、12万2300TFlops/18万7659.3TFlopsで効率は65.2%でしかなかった)ことを考えると、富岳がかなり早いタイミングで最適化がうまく行っていることを示している。
4命令デコード/7命令発行のスーパースカラー/アウト・オブ・オーダープロセッサーなので、決して普通のプログラムが遅いということもないとは思うが、昨今のIPCを追求したプロセッサーが搭載するL0 Cache(μOp Cache)やDual Branch Unit、あるいはPerceptronベースの分岐予測といった機能はA64FXには含まれていない。
どれだけ大量のデータを効率的に処理するかを追求することがA64FXの目的であり、そのためにSVEの使い勝手をいかに良くするかに専念している感がある。すでに、GitHubにMicroArchitecture Manualが公開されているというあたりも、利用者に早いタイミングで最適化のための情報を提供するという姿勢の1つと思われる。こうした部分も含めて、富岳のA64FXは「ARMらしくない」ARMプロセッサーと言える。
この連載の記事
-
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 - この連載の一覧へ











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")













