




Predicationで半自動ベクトル化も可能
さらに独自の4オペランドFMAを実装
Predicationは、Load/Storeの際にも利用できる。Load/Store命令の際に、データを並べ替えながらのロードが可能(インデックスレジスターで指定)だが、これにPredicationを加えて「そもそもLoad/Storeをする/しない」の制御も可能になっている。このPredication付きロードは複数のモードがサポートされている。

ややわかりにくいが、これはZ0.Dというレジスターに、X0というアドレスから始まるメモリーの値をロードする処理で、ただし並び順をZ1.Dというインデックスでして、さらにP0/zのPredicationでロードする/しないを設定している

Predication付きロードは複数のモードをサポートする。どの場合でも、Predicationによる制御が有効になっている
こうしたPredicationの指定そのものは珍しくないというか、SIMD演算では似たものはいくつかあるが、通常は個々の命令に対する拡張として実装されているのに対し、A64FXではベクトルレジスターに対する操作の一般的な手法としてPredicationが用意されているのが大きな違いである。
もっともこれは(プロセッサー内部の処理からすると)面倒な作業になるわけで、専用処理ユニットとパイプラインが追加されたのも無理ないところである。
実際、ここまでの細かな操作がサポートされていないSPARC64 XIfxには、Predicationユニットが搭載されていない。
そしてPredicationと先のFirst-fault loadを組み合わせると、とてもベクトル化できそうにないコードですら、SVEでぶん回せることになる。

これはわかりにくいが、下の4命令で16要素まとめて判別している。また左のスカラーコードは、A[N]が十分大きければいずれはページフォルトを起こすはずで、その振る舞いはFirst-fault loadで再現できることになる
A[N]はintなので32bitとすれば16倍、もしこれをINT8で実装したら64倍の速度でwhileループを回せるわけだ。さらには、Predicationを使っての半自動ベクトル化も可能としている。

データ依存がある場合、ベクトル化への展開がしにくい。そこでPredicate Registerを使い、データ依存をSVCに教えてやることで、ベクトル化できるという仕組み
SVEに絡んだ独自の実装が、4オペランドFMAである。D=A×B+Cという一般的なFMA(Fused Multiply-Add)処理の場合、A/B/C/Dの4つのオペランドが必要になる。ただARM v8ではこの4オペランド命令をサポートしていない。
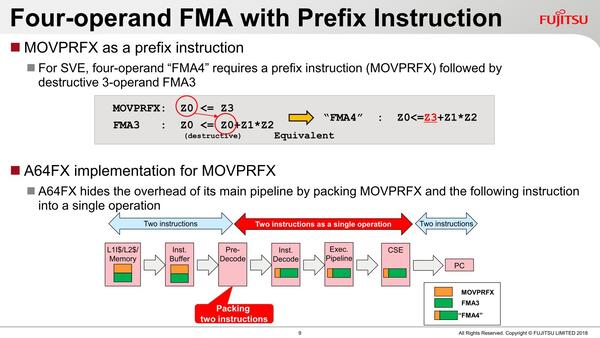
そこで、通常は上のソースにあるように2命令での処理になるわけだが、A64FXではこれを内部的に処理して、1つのFMA4命令としてハンドリングすることになる。これにより、フロントエンドでは2命令として認識されるものの、バックエンドでは1命令で処理されることになり、実質的な性能向上につながるわけだ。
消費電力を下げるために
デコードと実行ユニットを制限できる
性能向上の一方で、省電力の仕組みもやや独特である。チップ単位のEnergy monitorと、コア単位のEnergy analyzerを併用し、細かく消費電力を監視しながら電圧/動作周波数を制御するというあたりまでは一般的であるが、Power knobの実装はあまり見かけたことがない。
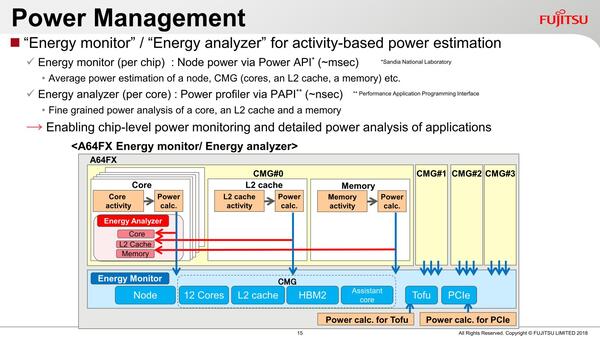
消費電力により電圧/動作周波数を制御する。チップ単位のPower APIはSNLが開発したものに準拠、というのがおもしろい
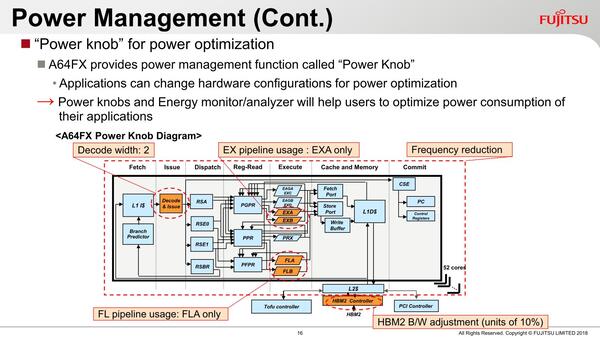
Power knobを実装。「使っていないユニットを休止」はClock Gating/Power Gatingでおなじみだが、そもそも使う使わないをAPIから設定できるのがなかなか斬新である
要するに、デコードを絞るとともに、利用する実行ユニットも制限することで消費電力を下げるという仕組みである。最小に絞ると、デコードは2命令/サイクルになるし、EXB/FLBのユニットは休止になるため、実質5命令のスーパースカラー/アウト・オブ・オーダー構成になる。
ついでにHBM2のバンド幅も10%単位で絞ることが可能になる(もちろん動作周波数も下げられる)仕組みだ。
この連載の記事
-
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 - この連載の一覧へ











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")













