ニューラルネット構造を解析してGPUの限られたメモリーで高速演算
ディープラーニングのニューラルネット規模を約2倍にするGPUメモリー効率化技術
2016年09月23日 20時11分更新

メモリ効率化技術
富士通研究所は9月21日、ニューラルネットの学習の高精度化に向けたGPUメモリー利用効率化技術を開発したと発表した。
ディープラーニングの学習処理では大量の演算処理を必要とするため、最近ではGPU(グラフィックプロセッサー)を用いられている。GPUの高速演算性能の利用には、データをGPUの内部メモリーに格納する必要があるが、容量によってニューラルネットの規模が制限されるという問題があった。
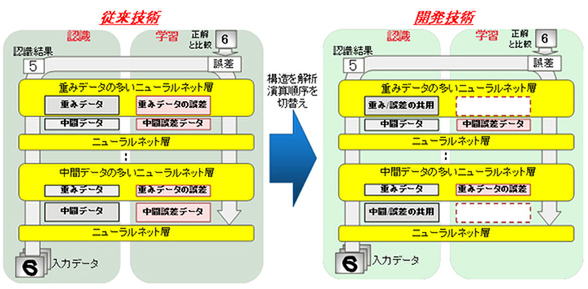
富士通研究所では、ニューラルネットの各層の学習処理において、重みデータから中間誤差データを求める演算と、中間データから重みデータの誤差を求める演算が独立して計算できることに着目。学習開始時にニューラルネット各層の構造を解析、より大きなデータを配置しているメモリー領域を再利用できるように演算の処理順序を切り替え、メモリー使用量を削減する手法を開発した。
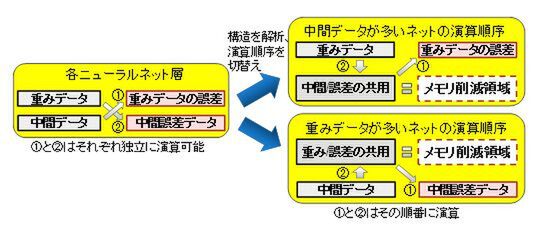
ニューラルネットの各層を解析して独立した演算を行なう
これにより、40%以上のメモリー使用量を削減し、GPU1台あたり約2倍の規模のニューラルネットを学習することが可能となった。富士通研究所では、今回開発した技術を富士通のAI技術「Human Centric AI Zinrai(ジンライ)」のひとつとして、2016年度末までの実用化を目指すとしている。









