




SNSの分析や営業やマーケティングの仮説検証ツールというイメージが先行するビッグデータを、「イノベーションの道具」として使おうというのが、富士通のキュレーター部隊だ。データ分析の専門家であるキュレーターが実施するサービスを担当している高梨益樹氏に話を聞いた。
仮説検証型のBIとはアプローチが異なる
2012年、富士通は、従来BI/BA(Business Intelligence/Business Analytics)を手がける研究者やコンサルタント、プロダクト開発者、SEなどを集め、インテリジェントコンピューティング室を立ち上げた。その中核となるキュレーターは、分析をメインに手がける「データサイエンティスト」よりも、ユーザー企業の持つデータや商品やサービスに、より深く関わっていく専門家と定義づけられている。今回お話を聞いた富士通の高梨氏は、このキュレーターを率い、ユーザー企業で眠っているデータから新たな価値を創出しようとしている。

富士通 コンバージェンスサービス本部 インテリジェントコンピューティング室 シニアマネージャー 高梨益樹氏
高梨氏の捉えるビッグデータに関しては、8月に開催されたビッグデータ説明会のレポートをご一読願いたい。私が感銘を受けたのは、SNSや天候などのデータはあくまでヒントで、本来、業務由来のデータこそが新たな価値を創出できるという点。そして、営業・マーケティングといった1つの業務での仮説検証ではなく、新製品や新サービスの開発にビッグデータが利用できる可能性があるという点だ。この2点は、AmazonのリコメンデーションエンジンやTwitterによる顧客動向分析をメインとした既存のWebプレイヤーのビッグデータ活用と一線を画しているといえる。
インタビューの冒頭で高梨氏が強調したのも、業務由来のデータでイノベーション を実現するというインテリジェントコンピューティング室の存在意義だ。「仮説検証型で分析を行なうとか、バッチ処理の高速化に並列分散処理を利用するという要件であれば、富士通の中では今までの事業部のビジネスです。私たちは、ビッグデータを使って、今までなかったサービスやアプリケーションを生みだす部隊として組織されています」(高梨氏)とのことで、既存の価値を高めるのではなく、新たな価値を創出するためにビッグデータを使うわけだ。
最善手を編み出すアプローチの違い
高梨氏が、ビッグデータが生み出したイノベーションの例として挙げたのが、以前TV局にも取材を受けたという「糖尿病発症リスクの予測」だ。これは毎日の体重や歩数、血圧の変化、健康診断データなどの行動履歴から来年、糖尿病になるリスクを割り出すというもの。まずはコンピューターを使って3万人3年分のデータを解析し、糖尿病になる人、ならない人を機械学習によりルール化する。このルールに対して、個人の行動履歴データを当てはめると、現状の糖尿病リスクがある程度判断できるという。

糖尿病リスク判定システムで用いたデータ
「サンプル数とヒントになるデータを増やすことで、精度を上げることが可能になりますが、判定ルールは複雑になります。人間にはとても作りきれない複雑な判定ルールを作る手法として、機械学習があります。機械学習にもさまざまなアルゴリズムがあり、データの種類や目的に合わせて、最適な方法を利用するための方法論を蓄積しています」(高梨氏)
もう1つ、新しい分析の象徴的な例として高梨氏は将棋ソフトを紹介した。「将棋の強い人が、何に着目して次の一手を選択したのかという次の一手をフローチャート化して、プログラミングするのが従来の将棋ソフトの作り方です。この作り方で作られた最強のソフトは、次の一手を判断する際のパラメータ数が500種類程度でした。このパラメータ数というのが、人が教えられるコツの限界だと思います」(高梨氏)。とはいえ、この方法だとプロが意識しているノウハウは抽出できるものの、無意識で行なっている最善手への思考プロセスを掘り越すことができない。
これに対して、最新の将棋ソフトは、最善手しかないプロの棋譜5万局分を学習させることで、9000万種類のパラメータを導き出し、プロ棋士並みの実力を備えることができたという。高梨氏は、「業務知識で仮説を作っていくという今までのBIと、データオリエンテッドにさまざまなモノを見ていこうというアプローチの決定的な違いが、この500種類と9000万種類の差なんです。この可能性があるからこそ、私達のようなデータ分析を行なう人間が、業務支援ではなく、製品開発のようなお客様のビジネスの本流に参加できるんだと思います」と既存のデータ分析との違いを強調する。
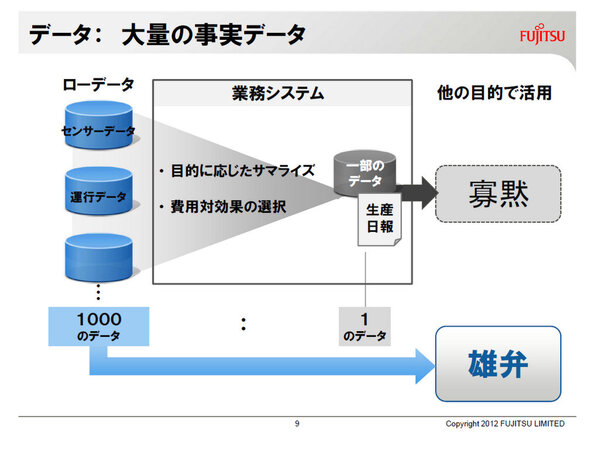
大量の事実データが雄弁に語る
予測モデルの構築に業務知識は必要か?
こうした「業務の中に入っていく」データオリエンテッドなものづくりを実現するため、富士通がキュレーションで用いているのは、全方位型のデータビューイングという手法だ。これは業務のプロが仮説が正しいかどうかを検証するのではなく、データを多面的に捉え、徹底的にデータに語らせるという方法をとる。
この全方位的なデータビューイングを実行するには、業務知識を徹底的にそぎ落とし、数理モデルに寄った見方が必要になるという。「設計部門の人がサポート情報を元にデータ分析するような場合は、みなさん図面が読めるので部品の配置とか、部品同士の干渉具合などがわかります。こうした業務知識を前提にエラーをつぶそうとすると、あるところでエラー発生率を下げられなくなります」(高梨氏)。この結果、自身の持っているデータの有効性を証明する意味も込めて、同社のキュレーションサービスにたどり着く例も多いという。
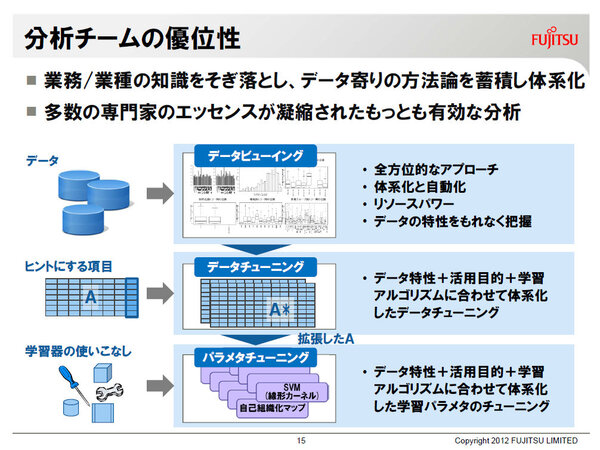
業務データをそぎ落とすことで見えるもの
これを実現するための方法論について、高梨氏は「たとえば、工作機械や検査機器の故障時期を予測する例ですが、保守の時期や故障の場所などをヒントとして与えるとしても、カラム数で言って数100~1000程度が限界、予測には足りないんです。そこで、これらのヒントとなるデータを増やしたい。取得頻度を短くするなどして増やせればよいのですが、物理的に増やせない場合には、データをどのように拡大・強調したら、なにが得られるかという捉え方が必要になります」と語る。そして、業務知識に寄らないデータと目的と分析手法の使いこなしの方法論を体系化し、進化させていくことが、キュレーターとしての財産、他社との差別化につながるという。
もちろん、業務知識を軽視しているわけではない。「たとえば病気のリスク判定の結果、病気を防ぐために運動を増やすとか、オンラインサービス会員の退会率を下げるためにコンテンツを調達したり、キャンペーンを打つといったオペレーションの検討や実行は、業務知識を持ったプロフェッショナルの領域です。キュレーターはデータを使って、プロフェッショナルの仕事をサポートする立場だと思っています」(高梨氏)とのことで、データ分析と現場の担当者が分担して、PDCAを回すことが最強の組み合わせだと説明する。
高梨氏は、ビッグデータの存在意義として「今までは業務が先にあって、どうすれば利益に結びつくかを考えて、商品やサービスが存在していました。しかし、この方法で開拓できる領域が出尽くすと、商品もサービスも業務もあるエリアから出られなくなります。こういう閉塞感を打破し、データオリエンテッドにアクションアイテムを作り出していくのが、ビッグデータ活用の1つの意味ではないかと思います」と語る。
この連載の記事
-
第14回
ビジネス
“シリコンバレーの技術者集団”ではトレジャーデータを見誤る -
第13回
デジタル
セクシーなデータサイエンティストになるまで5年かけていい -
第12回
ビジネス
ビッグデータに一番近いダイレクトマーケターが考える価値 -
第11回
ソフトウェア・仮想化
「データ」をビジネスにしないとIT業界では生き残れない -
第10回
ソフトウェア・仮想化
富士通のキュレーターが挑む「ビッグデータからものづくり」 -
第9回
ビジネス
ビッグデータを使うWeb事業者が外食産業に進出したら? -
第7回
ソフトウェア・仮想化
“データが語る時代の端緒”統計のプロが考えるビッグデータ -
第6回
ソフトウェア・仮想化
“ビジネスでの価値は事例が語る”IBMが考えるビッグデータ -
第5回
ソフトウェア・仮想化
“非構造化データは宝の山”オートノミーが考えるビッグデータ -
第4回
ソフトウェア・仮想化
“常識を覆す迅速な仮説検証へ”JR東WBが考えるビッグデータ - この連載の一覧へ









が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")









