




前回に引き続いて、今回も「Haswell」の詳細を解説する。まずは追加された「AVX2」命令から説明しよう。
HaswellでのAVXの強化
1サイクルで256bitの演算が可能に
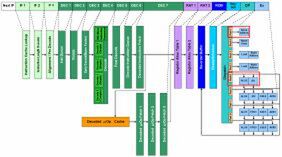
図1 Haswellの内部構造図。赤枠内がSandy Bridgeからの主な変更部分
AVX2命令は、Sandy Bridge世代で投入された「AVX」命令の機能と性能を拡張するものである。大きなポイントは以下の3点だ。
- 性能が2倍
- 浮動小数点のFMA(Fused Multiply-Add)演算をサポート
- いくつかの新命令を搭載
まず性能が2倍の根拠はなにか。Sandy Bridge世代でのAVX演算は、既存のSSE用演算器を流用して実装されていた。SSEはご存知のとおり、1サイクルあたり最大128bitの演算を行なう(関連記事)。そのためAVX演算の場合は、128bitずつ2回に分けて演算を行なうことになっていた。
これに対してHaswellでは、SSE演算器がすべて拡張され、AVXにあわせて1サイクルあたり256bitの演算が可能になっている。そのため、従来だと2サイクルを要していた演算が全部1サイクルで可能となり、これだけ見れば性能が倍になった形だ(Photo01)。ただし、残念ながら「それならSSEを使えば、1サイクルあたり2つのSSE命令が実行できる」とはいかない。あくまでもAVX命令を使った場合のみ有効である。

1サイクルあたりのSSE/AVX/AVXの演算可能な数。Single Precision(SP、単精度浮動小数点演算)なら1サイクルあたり最大32個。Double Precision(DP、倍精度浮動小数点演算)でも1サイクルあたり16個が演算可能になっている
次のFMA(Fused Multiply-Add)とは、乗算と加算が混じった形の演算である。
- A=A×B+C
この演算を1回で行なうというものだ。実はこの形の演算は、自然科学の分野では非常に広範囲で使われており、シミュレーションを初め多くの分野で利用されている。AVX命令もこのFMAをサポートしているのだが、Sandy Bridgeの世代では整数演算でしか利用できなかった。Haswellではこれを、浮動小数点演算に拡張した点が大きな差となっている。
この連載の記事
-
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 - この連載の一覧へ











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")













