




非ノイマン型プロセッサーへの挑戦と挫折
新しいプロセッサーの用途が見え始めると、必ず湧いて出るいくつかのアーキテクチャーがある。例えば超ワイドなVLIW(Very Long Instruction Word:超長命令語)や、超ヘテロジニアス・プロセッサー、メモリー・セル・プロセッサー(マトリックス・プロセッサー)などの類だ。
VLIWは確かに実装が楽だからといって、10を超える命令を同時にサポートするのはやはりやり過ぎだと思うし、1つのSoCの中に異なる命令セットを持つコアを複数種類(それも2つとかならともかく4つも5つも)実装し、それらの命令セットをつなげてVLIW化するのは無茶を通り超えて無謀の域に達する。
メモリー・セル・プロセッサーというのは、消費電力を考える演算そのものよりメモリーと演算器の間のデータ移動の方が消費電力が大きいので、メモリー・セルと演算器を一体化したというアイディアである。
これはみんなが思いつくにも関わらず、まともなプロセッサーが存在しないというのは、やはりそれなりに難しさが存在するからで、これにチャレンジして散っていったベンチャー企業は筆者が知っているだけで3つある。
同じように湧いて出るアイディアにデータフロー・プロセッサーがある。日本語ではデータ駆動型コンピューターとするのが一般的かと思うが、実は日本だと1987年に電総研で開発されたSigma-1や1990年のEM-4などを始め、いくつか完成したマシンが存在する。
ただこれは巨大なシステムであって、とてもワンチップに収まるものではない。それでも2000年台に入ると、例えばARMをクロックレスで動作させた疑似データフロータイプのプロセッサーなど、いくつかチャレンジした例はあるのだが、やはり商用的に成功した例はない。
昨今で言うとデンソー子会社のNSI-TEXEが今年1月にDR1000Cと呼ばれるデータフロー・プロセッサーを発表したが、まだ商業的に成功したか否かを判断できる段階ではないのでここではおいておくとして、基本的にデータフロー・プロセッサーは茨の道である。
しかし「非ノイマン型プロセッサー」という言葉にはなにかしらの魅力があるようで、これにチャレンジする企業は後を絶たない。
データフロー・プロセッサーの代表作
Wave ComputingのDFP
ということで本題。2017年のHot Chips 29において、アメリカのWave Computingというベンチャー企業がAI向けにDFP(Data Flow Processor)を発表した。同社はTailwood Capitalの支援を受け、2010年に創業後はステルスモードで活動しており、このHot Chipsにおける発表が会社と製品の初公開の場となった。
さてそのDFP。例えばCPUとGPUを組み合わせて機械学習をやる場合、しばしばGPUがCPUを待つことが多く、非効率であるというのがそもそもの動機である。
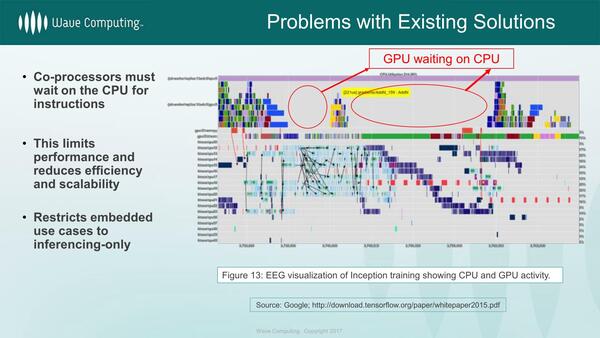
これはGoogleがTensorFlowをCPUとGPUで実施した際のプロファイル。GPUがCPUを待つことが多い
この非効率には以下の2つが挙げられる。
- 処理をCPUとGPUで分散させており、なのでGPU側に待ちが発生する
- 待ち時間の間にも電力消費がある
ではすべての処理をGPUでできるように変更すれば解決するかというと、そういう問題でもなく、GPUの負荷が掛かっている時でも、常にすべてのユニットが動いているわけではない。
加えて言えば、GPUは細かな制御を行なうのに向いてない(それを入れたらGPUの良さがスポイルされる)し、全部GPUにしても待機する処理ユニットが電力を消費する問題の解決にはならない。これを解決するのにデータフロー方式が役に立つ、というのが同社の主張だ。

内部的には左上のネットワークを、ソフトウェア処理(右上)経由でグラフ(右下)に展開し、それをDFPの内部のユニット(左下)に割り当てて動作させる形になる
データフローというのは「データが来たら処理を行ない、終わったらそれを次のユニットに送り出して終了」というもので、通常のCPUの「クロック信号に同期して内部の処理ユニットを順次動かす、いわばクロック同期式」とまったく異なる制御方式で動作する。
現実問題としては、個々のユニットの中は従来の同期式のメカニズムで実装される場合もある(ここを完全クロックレスにすると、難易度が急増する)が、上位レベルではクロックとは非同期で、あくまでデータの到来に合わせて非同期で動作する。
これをディープラーニングに応用すると、DFPの演算ユニットに個々のニューロンを割り当てることで、「データが来た時だけ動く」という、もともとの人間の神経細胞に近い動きをナチュラルに実現できる。
加えて言えば、例えば従来の方式では処理結果が0の場合でも、次のユニットにその0が伝搬されるが、データフローの場合は、あるユニットの計算結果が0だと、次のユニットがそもそも動かないから無駄に消費電力を費やすこともない。この結果として極めて効率的に動作できるという主張だ。
どうやってこれでBack Propagation(逆伝搬:学習データからパラメーターを調整する作業)を実施するのかがいまいち明確ではないのだが、それはともかくとしてこのデータフロータイプのプロセッサーとして作り上げられたのが同社のDFPである。
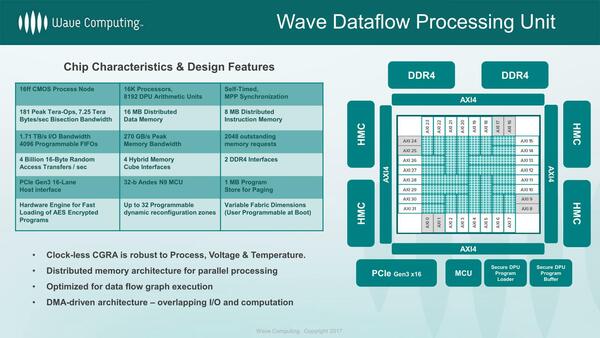
ちなみにTSMCの16FFプロセス(おそらく16FF+であろう)を使うとあるが、ダイサイズは不明。相当大きいはずだ
特徴は以下のとおり。
- 非同期動作するプロセッサー1万6384個とDPU算術ユニット8192個を集積。処理性能はピークで181Tops。
- データメモリー16MBと命令メモリー8MBをコア内部に集積。このコア内部のメモリー帯域は7.25TB/秒に達する。
- I/O帯域は1.71TB/秒で、I/O用に4096個のFIFOが用意される。外部メモリーには4つのHMCと、オプションで2chのDDR4が用意され、トータルで270GB/秒の帯域が確保される。
- ホストとのI/FはPCIe Gen3 x16。また内部の管理用にAndesのAndesCore N9 MCUが搭載される。
ここでHBM/HBM2ではなく、Intel/Micron連合の開発したHMC(Hybrid Memory Cube)を選んだのは少しばかり痛恨のミスだったような気もしなくはないが、AMDがHBMを初採用したのは2015年のことで、確か当時AMDはSK HynixとUMC、それとASEの共同開発(チップをSK Hynix、インターポーザーをUMC、パッケージがASE)でやっと実現したという代物で、ステルスモードのベンチャー企業が実現するのは難しかっただろう。
その後TSMCがCoWoSでHBMを普通に扱えるようになったのは、2016年に入って投入された第2世代のCoWoS-XLからで、やはりベンチャー企業には間に合わなかったと考えられる。また、1:1接続ではないのも理由に挙げられよう。
この連載の記事
-
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 - この連載の一覧へ











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")













