




GeForce RTXシリーズの
アーキテクチャーを大予想
さて、ここまでは前座でいよいよ本命のGeForce RTXシリーズである。実のところ、こちらもまだ詳細はわかっていない。意識してのことだとは思われるが、NVIDIAはまだTuringアーキテクチャーに関するホワイトペーパーなどを公開しておらず、なのでRT Coreの実装や、SM(Streaming Multiprocessor)がどういう構造になっているのかはさっぱりわからない。
あるいはNVIDIAが新しく公開したRTX-OPSという指標も、なにをどうやるとこの78T RTX-OPSが算出されるのか不明なままである。

RTX-OPSという指標。GeForce RTX 20シリーズにおけるRTXのレンダリング処理を細かくステージ化し、それがどの部分で処理されるかを示したものだ
このあたりは今後製品が出荷されるころまでに明らかにされることを期待しつつ、とりあえずイッペイ氏の記事に示されたスペックを基にロードマップを描き直したのが下図である。

2016年~2018年のNVIDIA GPUロードマップ
CUDAコア数こそ明らかになっているが、その他の話は今のところ未公開なので、これらは全部推定(なので数字には“?”がついている)である。この推定の根拠を説明しよう。
下の画像はNVIDIA提供の、TU102コアのダイ写真である。ちなみにTU102、というコード名も公式にはまだ明らかにされていない。今までだとGTになりそうだが、あいにくGTシリーズはすでに使われている。あるいはRTXシリーズでR、TuringでTということでRT102、なんて話も出ていたが、TU102というのが一番確度は高いらしい。

TU102コアのダイ写真。元画像が小さいので画像が荒いのはご容赦いただきたい

上の画像をベースに色々書き足してみた。周囲のPadは、GDDR6へのI/Fと思われる
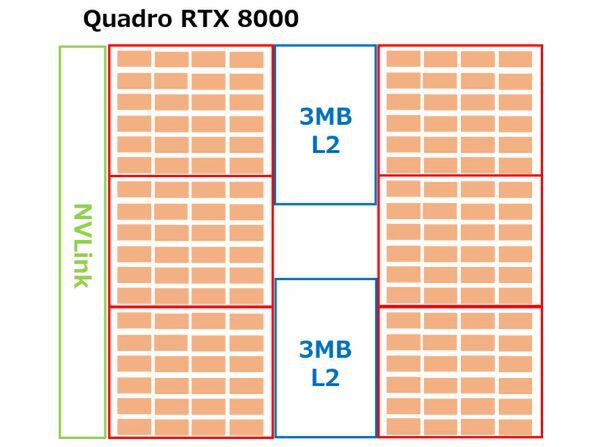
それはともかくこのTU102の内部ブロックを見ると、大きく6つのブロックがあり、それぞれの中に6行4列の演算ユニットがある。これを6行4列とみるか12行4列とみるかは難しいが、後述の理由により6行4列の方が辻褄が合いやすいので、6行4列案を取る。
TU102コア(Quadro RTX 8000)は6つのクラスターがあり、それぞれのクラスターが24個のSMを持ち、各々のSMが32演算(Intの場合)を同時に処理すると考えると、CUDAコア総数は6×24×32=4608となり、Quadro RTX 8000の4608 CUDAコアというスペックに合致することになる。
問題はGeForce RTXである。GeForce RTX 2080 Tiの場合、コアそのものは間違いなくTU102のままであると思われる。ただしCUDAコアが4352という、謎な数字になっているが、これを6クラスター/32演算で割ると、1クラスターあたり22.6667……SMになる。ただこれも実際には簡単で、1クラスターあたり23SMコアにしつつ、うち2クラスターのみ22SMにすれば、6クラスター合計で136SM、4352CUDAコアになる。
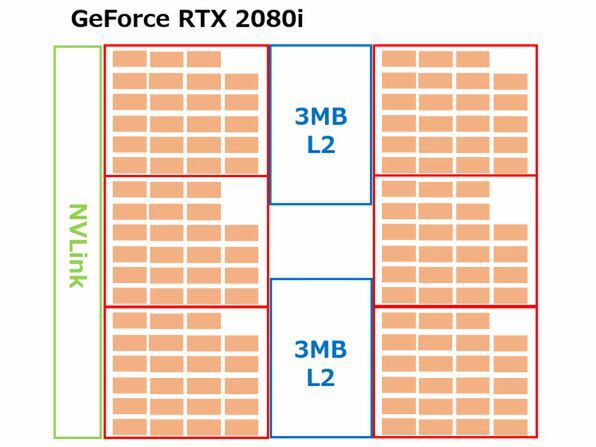
ちなみにテクスチャーユニットはPascal世代の製品構成を睨みつつ、一応クラスターあたり48ユニットと仮定してみた。一方ROPについては、メモリーコントローラ(32bit)あたり10ユニットと仮定している。
この結果、GeForce RTX 2080Tiは6クラスターなのでテクスチャーユニットは288ユニット、一方ROPユニットは352bit Bus(32bit×11ch)でメモリーチャネルが11個なので、110ユニットとしている。
この連載の記事
-
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 - この連載の一覧へ











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")













