




スーパーコンピューターでは
あまり目立った実績を残せなかったFPGA
ということで、やっとスーパーコンピューターに話が戻ってきた。大規模なFPGAを利用すると、従来のプロセッサーでは実現できないようなことが、より高速に可能になる。
例えば数値計算系で言えば、CPUやGPUはよく利用される乗加算に関しては高速だが、割り算をひたすら行なったり、指数対数、三角関数などを多用する演算はそれほど高速とは言えない。こうした場合、FPGAを利用することで高速化が可能だ。
あるいは、ある処理の結果を次の処理の入力にする逐次処理が必要な処理の場合、数十万個の粒子の動きをシミュレーションするなど問題の規模が大きいと、並列化による高速化の効果があるが、問題の規模が小さく、ひたすら繰り返し演算をするようなケースではCPUにしてもGPUにしても性能が上がりにくい。
対してFPGAの場合は、回路が許す限り延々と処理を直列に並べられる。動作周波数そのもので言えばCPUの方が高速だが、FPGAでは処理をパイプライン化することで、相対的にCPUをはるかに上回る速度で処理ができる場合もある。
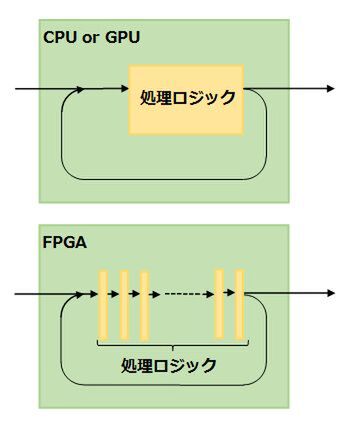
図4 FPGAは回路が許す限り延々と処理を直列に並べられる
また、特定のアルゴリズムを直接ハードウェアに記述できれば、ソフトウェアで行なうよりもずっと処理性能が引き上げられる。
その一方でFPGAには欠点がある。まずはトランジスタ効率が悪いことだ。なにしろLUTベースなので、図1/2の表を実装するために112bit分が必要である。
SRAMを1bit実装するには最小4つ、一般的には6つのトランジスタが使われるので、このLUTを実装するのに必要なトランジスタは最低でも672個となる。
一方、図1の回路をそのまま実装すると、ANDとXORがそれぞれ3つづつである。CMOSの場合の最小構成では、ANDはNOT+NANDで合計6トランジスタ、XORはもう少し増えて10トランジスタで実装できるため、合計48トランジスタで済む計算になる。どちらの効率が良いか、比べるまでもない。
以前Gate Arrayという用語を説明したが、このASIC用のGate Arrayと比較した場合、大雑把に言うとFPGAは10倍ほど効率が悪いと考えておいたほうがいい。つまり専用回路と同じことをやらせたら、明らかに無駄が多い。
またFPGAのプログラミングにはHDL(Hardware Description Language:ハードウェア記述言語)と呼ばれる独自の言語を利用する必要があり、部分的にC言語などと似ている部分もあるが、だからといってCのプログラムをそのまま流し込めるわけではない。というよりも実際にはほとんど違う言語(考え方からして違う)なので、利用者は新たにHDLを習得しなければならない。
このあたりが災いして、これまでFPGAはスーパーコンピューターの市場に何度となく投入されながら、あまり目立った実績を残せなかった、というのが実情である。
正確に書けば、FPGAそのものは広く利用されている。例えば前回のCyclops64で取り上げた下図を見ると“1 Cyclops-64 Chip”のところで、チップにDDR2メモリーのほかFPGAが搭載され、これにIDE HDDが接続されているのがわかる。
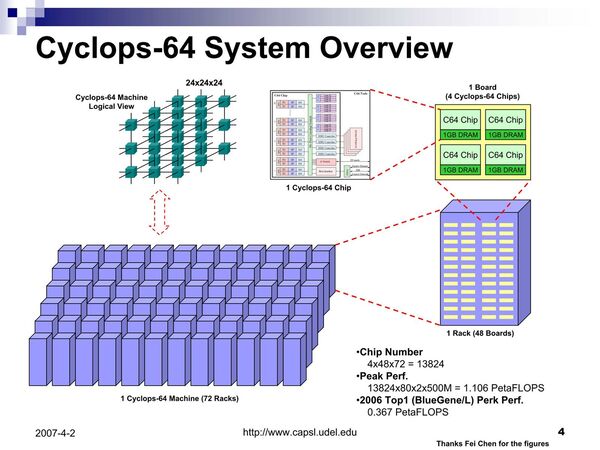
Cyclops64のシステム構成
もともとFPGAは“Glue Logic”、あえて日本語訳すれば“接着剤的回路”として、さまざまな回路同士をつなげるのに使われてきた。
例えばある製品を継続して生産していたら、部品の1つが廃番になってしまい、代替品は微妙に仕様が違うというときに、いちいち全体を再設計していられない。そこで間にFPGAを挟んで差を吸収する使い方が多かった。
これはスーパーコンピューターでも同じで、いろいろなチップ同士をつなぐ際にはチップの間にFPGAがバシバシ使われていた。 最近では、データセンター向けにFPGAが脚光を浴びつつある。
マイクロソフトによるFPGAを使ってのBingの実装もその一例だが、GoogleやFacebookでは、ストレージのコントローラーですら汎用のRAIDではなく、独自の代替アルゴリズムを実装したものを利用しており、こうした場合FPGAを利用するのが一番妥当である。
あるいは米国の証券会社などによる金融取引では、ネットワークの処理をFPGAで実装することで、ミリ秒単位での取引を可能にする話が2014年頃に盛んだった。
FPGAの側でも、Altera(現在はインテルの傘下)は、OpenCLを利用してFPGAを利用できるようにする仕組みを提供しているし、XilinxはCのプログラムをHDLに変換して高速に実行させるSDSoCというソフトを提供したりするなど、よりFPGAを使いやすくするためのツールの充実に余念がない。
またこうしたトレンドのお陰で、少しづつではあるがHDLを書けるエンジニアの数も増えてきた。とはいえ、スーパーコンピューターの市場で一般の研究者がバリバリFPGA向けに自分の研究用プログラムを記述できるようになる、という状況にはまだまだ遠い。当面はFPGAが利用されるマーケットはごくわずかに留まる、と考えるべきであろう。
ということで全63回にもなりましたが、スーパーコンピュータの系譜はこれで一段落とさせていただきます。またなにか出てきたら追加とかを書くかもしれません。次回からは久しぶりに初心に帰って、製品ロードマップをお届けします。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















