




ほぼ同じ構造でステージ数が
20段と31段で異なる理由とは?
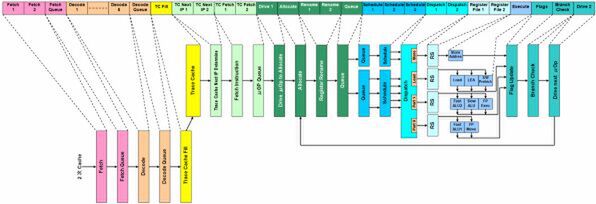
図1 Prescottのパイプライン構造図
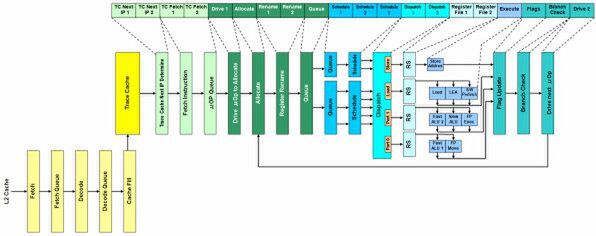
図2 Willametteのパイプライン構造図
Willamette世代の内部構造図(左)と、Prescottの内部構造図(右)を見比べても、違いは以下の4点程度だ。

こちらはWillametteの構造図。「Intel Technology Journal Q1, 2001」より引用

こちらがPrescottの構造図。構造そのものにはまったく違いがない。「Intel Technology Journal Volume 08, Issue 01」より引用
- Trace Cacheの「BTB」(Branch Target Buffer、分岐予測バッファ)のサイズが4倍になった
- 1次データキャッシュのサイズが2倍になった
- 2次キャッシュのサイズが4倍になった
- Bus Interface Unitの速度が4倍になった
CPU黒歴史のPrescott編でも書いたが、PrescottとWillametteにパイプライン構造の差はほとんどない。図1はPrescottの想定パイプラインステージだが、前回掲載の図2と比べて最大の差は、パイプラインの段数にTrace Cacheを入れるか否かである。
要するに、Willametteでも「2次キャッシュからのFetch」から数えると25~26段のステージ(実際には28段くらい?)があったところ、Prescottではそれが若干増えて、トータルで31段になったわけだ。なぜインテルは、Willametteでは20段と言っていたのに、Prescottでは31段と言うようになったのか? それは当時のマーケティング戦略を考えるとわかりやすい。
NetBurst ArchitectureはIPCこそ低いものの、動作周波数を引き上げることで性能を確保するコンセプトの設計で、そのために長大なパイプラインを備えていた。WillametteはTrace Cache以降だけで20段ものステージがあり、インテルは「それが高速動作を可能にしている」と説明していた。続くPrescottは「5GHzを狙う」と発表されていたが、Trace Cache以降のステージ数だけを見ると「20段から増えていないのに、どうして5GHzが狙えるの?」と思われかねない。そこで方針を変えて、Fetchからの段数も合わせた数字を示すようにしたのではないか、と筆者は想像している。
WillametteとPrescottのパイプライン構造の違いを見てみよう。まず大きく異なるのはデコーダー部である。Willametteでは従来型の、「Hard-Codedデコーダー」(対応する命令を固定してハードウェアで作りこんだデコーダー)に、一部の複雑な命令のみマイクロコードROMを併用するという構造だった。Willametteに限らずほとんどのCPUがこの構造をとっており、P6アーキテクチャーも例外ではない。
ところがPrescottでは、このHard-Codedデコーダーをほぼ撤廃したようで、ほとんどの命令をマイクロコードROMでデコードしている。あるいは、フロントエンドがマイクロコード、バックエンドがHard-Codedという形なのかもしれないが、とにかくほぼすべての命令を、いったんマイクロコードの形で処理できるような仕組みにしている。
この連載の記事
-
第770回
PC
キーボードとマウスをつなぐDINおよびPS/2コネクター 消え去ったI/F史 -
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ - この連載の一覧へ












が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")












