




同時4命令実行に合わせてデコード段も強化
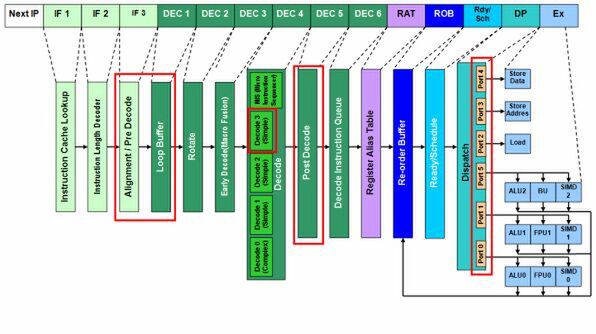
図1 Meromの内部構造図。赤枠内がYonahからの主な変更部分
また、Yonahまではフェッチの3段階目(IF3)が「Alignment」、つまりIF2で確認した「命令の区切り」位置にあわせてx86命令を抜き出して揃えるだけだったが、Meromではこの段階で、Macro Fusionに対応した「Pre Decode」の処理が追加されている。具体的に言えば、Macro Fusionの対象になりえる命令にここでフラグを立てることで、Macro Fusionをやりやすくする作業が入っているようだ。
続くデコード段には、Yonahになかった「Loop Buffer」が追加されている。これは64byte幅のバッファで、最大18個のx86命令が格納できる。なんのためにこれがあるのかというと、18命令の範囲でループがあってループの繰り返しが発生した場合は、フェッチ段を動かさずにLoop Bufferから読み出すことで、高速化と省電力化が可能というものである。
Loop Bufferからの単独読み出しであれば、フェッチの2倍に当たる32byte/サイクルで命令を読み出して「DEC2」に送り出すことが可能である。しかもその間は、クロックゲーティング技術を使ってIF1~IF3を待機状態にできるというものだった。ただし結果から言えば、18命令程度ではそれほど効果がなかったようだ。そのためNehalem世代では、この配置を変更したうえでサイズも拡大した、「Loop Stream Detector」を実装している。
DEC 1にLoop Bufferが入ったので、「Rotate」以降のステージは1段ずつ後ろにずれて、いろいろ手が入った。まずRotate(DEC 2)と「Early Decode」(DEC 3)では、最大6命令のx86命令を処理可能になった。Loop Bufferから最大32byte/サイクルで命令が来るのに合わせて、Yonahまでの最大3命令対応を倍増させたわけだ。
Rotateは処理がしやすいように命令の並び替えるもので、Early DecodeではMacro Fusionを処理する。このEarly Decodeからは、4命令/サイクルでx86命令(およびMacro Fusion命令)が出力される。メインとなるデコード(DEC4)は、「Simple Decode」がひとつ追加されて、都合4つのデコードエンジンが搭載された。各々のデコードエンジンは、Complex Decodeが最大4μOps/サイクルで、Simple Decodeが1μOps/サイクルの合計7μOps/サイクルになる。ちなみにYonahでは最大6μOps/サイクルであった。
続くDEC 5は「Post Decode」と記載しているが、実際にはDEC 4とDEC 5の2ステージに跨って、4つのデコードエンジンが動作していると考えればいい。これは、Micro Ops Fusionの対象となる命令が増えたために、従来よりも各デコードエンジンの処理が増えたことに起因する。
4つのデコードエンジンからのμOpは、いったんDEC 6の「Decode Instruction Queue」に格納される。このキューのサイズも、Yonahまでは6μOps分だったのが、Meromでは7μOps以上に強化されている(正確な数は不明)。
この連載の記事
-
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")














