



Stable Diffusion入門 from Thailand 第7回
秒100枚の画像生成ができるという「Stream Diffusion」を動かそうとしたらたいへんだったお話
2024年01月03日 10時00分更新


美少女画像を生成しようと思い立ち7月にゲーミングPCを購入してからはや半年、当初の目標であった画像生成にはなんとか成功したものの、とにかくこのジャンルは進化が早い。苦労して新しい技術を使えるようになったと思ったらすぐに次のとんでもない技術が登場し、以前のものは古くなっていく。なんとか振り落とされないようについていくのがやっとだが、それでも猛烈におもしろく刺激的な半年間だった。
「Stream Diffusion」爆誕
StreamDiffusion、ほぼ100fpsで画像生成出来るようになりました!!
— あき先生 / Aki (@cumulo_autumn) December 6, 2023
sd-turbo, 512x512, batch size 1, txt2imgだと10msで1枚画像が生成出来ます!
多分これが一番速いと思います pic.twitter.com/4qleR2isW1
さて、前回はStable Diffusionを爆速化するLCM系ツールについて解説したのだが、実はその執筆中となる12月6日に上記のツイートが投下された。
内容は気になったものの、この時点ではまだソースも公開されていなかったため連載には取り上げなかった。
大変お待たせしました!本日arXivにて公開された私達の論文「StreamDiffusion」について
— あき先生 / Aki (@cumulo_autumn) December 21, 2023
GitHubリポジトリの方も公開しました!100fps以上出すことも可能です!
詳しくは論文、リポジトリのREADMEをご確認ください!#StreamDiffusion
論文:https://t.co/4zQKFyPKgj
GitHub:https://t.co/U1ufvRR9cqhttps://t.co/5hO1UXT4Ya
だが、それからわずか2週間後、12月21日にはStable Diffusionがオープンソースで全公開された。さっそく速報記事を執筆、試してみようとしたのだが環境構築がちょっと大変そうだなと数日グズグズしていたら……。
なんと開発者のひとり「あき先生」による懇切丁寧なインストールガイドが12月23日深夜に生配信されたのだ。これにガッツリ参加してアドバイスもいただきつつそれでもかなり苦労したがようやくなんとか動かすことができた。さっそく見ていこう。なお、筆者の環境はグラフィックボードがNVIDIA GeForce RTX4070(12GB)、CPUがCore i7-13700、内蔵メモリーは48GBだ。
まずはGit clone
ここからしばらく環境構築およびインストールの話しが続くので、興味のない方は2ページ目の実行編へ。

まずはGitHubのStream Diffusionレポジトリにアクセス。
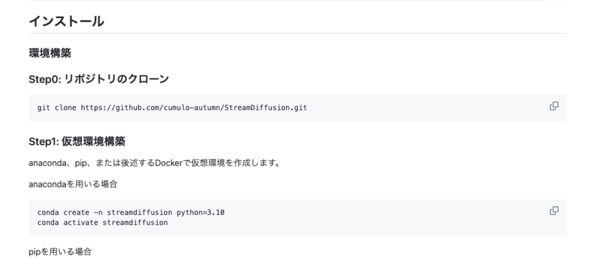
日本語で書かれた詳細なREADMEが用意されているのでインストールも敷居が低そうだ(と、最初は思った)。
まずは、下記コマンドでローカルに環境をクローンする。
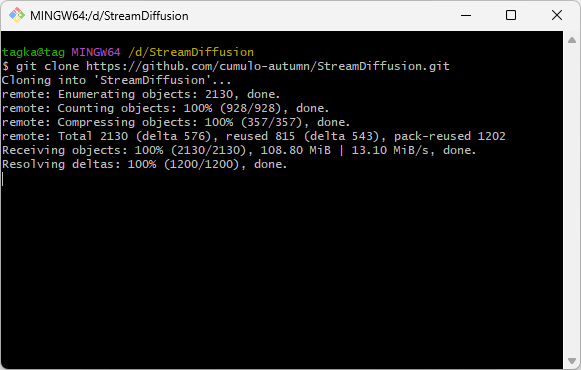
Dドライブのルートにレポジトリをクローンしているところ。
仮想環境の構築
次にAnaconda、pip、Dockerのいずれかで仮想環境を構築する。
筆者はAnacondaを利用しているので上記コマンドで仮想環境を作成。

作成したら忘れずにアクティベートも。

VSCode
なお、あき先生の配信にならい、ターミナルでの作業はすべてVSCodeを使用している。
PyTorchのインストール
次はメタが開発した機械学習ライブラリー「PyTorch」のインストールだが、ここで問題が発生。StreamDiffusionではPyTorchをGPUで動作させるために、あらかじめNVIDIAの「CUDA」プラットフォームおよび「cuDNN」ライブラリーのインストールが必要なのだ。

CUDAはGPUの種類によって11.8系と12.1系が存在する。ここではCUDA Toolkit Archiveから12.1.1をインストールした。
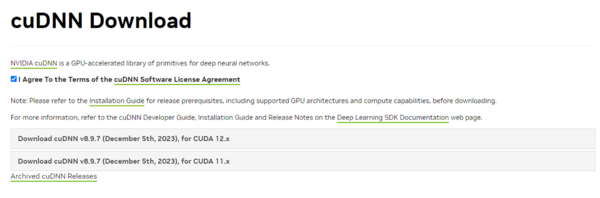
続けてcuDNNをダウンロード。CUDAのバージョンによってファイルが異なるので注意が必要だ。
準備ができたらPytorchのインストールだ。こちらもCUDAのバージョンによってインストールコマンドが異なる。
CUDA 12.1系のインストールコマンドは上記。

無事PyTorchのインストールが完了した。あと少しだ!!
StreamDiffusionのインストール
最後にStream Diffusion本体をインストール。
pip install pywin32
続けてTensorRT拡張およびpywin32モジュールをインストール。これで準備はすべて完了だ。
以上、比較的スムーズに進んでいるように読めただろうが、実はめちゃくちゃ苦労している。特にCUDA、cuDNNまわりは情報収集をサボっていたため理解するのが難しく、主にChatGPTでいろいろ質問しながらなんとか準備を完了した。4時間くらいはかかっただろうか。
もちろんこれはひとえに筆者の乏しい知識のせいだ。プログラムに慣れている人ならものの30分で上記工程をスムーズに終えることができるだろう。とはいえ初心者にとって環境設定は本当にハードルが高い。ChatGPTがなければたぶん投げ出していただろう。
この連載の記事
-
第13回
AI
Macで始める画像生成AI 「Stable Diffusion」ComfyUIの使い方 -
第12回
AI
これは便利!「Stable Diffusion」が超簡単に始められる「Stability Matrix」 -
第11回
AI
画像生成AI「Stable Diffusion」使うなら「ComfyUI」のワークフローが便利です -
第10回
AI
画像生成AI「Stable Diffusion」使い倒すならコレ! 「ComfyUI」基本の使い方 -
第9回
AI
画像生成AI「Stable Diffusion」を使い倒す! モジュラーシンセみたいな「ComfyUI」をインストール -
第8回
AI
Stable Diffusionで画像からプロンプト(呪文)を生成・抽出する方法。Fooocusの新機能「Describe」が便利でした -
第6回
AI
画像生成AI「Stable Diffusion」を爆速化。秒単位で美少女を生成できるLCM系ツールを使い比べた -
第5回
AI
画像生成AI「Stable Diffusion XL」が簡単に使える「Fooocus」。画像から画像が作れる「Image Prompt」が便利です -
第4回
AI
画像生成AI「Stable Diffusion XL」が簡単に使える「Fooocus」。便利な新機能が大量に出たのでまとめて紹介します -
第3回
AI
画像生成AI「Stable Diffusion XL(SDXL)」の使い方 初めてなら「Fooocus」がオススメです - この連載の一覧へ
















が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")





