
FiNCはデータレイク、DataSignはブロックチェーンのお話し
身体もWebサイトも健康一番!ヘルスケアとプライバシーのX-Tech
2018年05月30日 07時00分更新

2018年4月、「X-Tech JAWS」が都内で開催された。AWSをコアに面白いビジネスを展開する企業がその取り組みを紹介、共有する同勉強会は今回が3回目。さまざまな業界でチャレンジする登壇者を迎え、創意工夫の知見が共有された。前編では、ヘルスケア×TechのFiNCと、プライバシー×TechのDataSignの講演を紹介する。
FiNC~収集したデータやログを効率的に分析する仕組みを構築~
最初に登壇したのは、会場を提供したFiNCの鈴木健二氏だ。2015年に入社するまではインフラエンジニアを務め、現在はサイトの信頼性やセキュリティ、ブロックチェーンなどを担当する。

FiNC 鈴木健二氏
FiNCは、美容や健康の情報を提供するスマホアプリやWebサイトのほか、スポーツジムの運営、健康グッズの販売、企業向けウェルネスソリューションの提供など、ヘルスケア関連事業を幅広く手がける企業だ。特に食事や睡眠、運動データの入力・管理を専属AIトレーナーがサポートしてくれるスマホアプリは160万ダウンロードを突破するなど、人気サービスの1つとなっている。

FiNC FIT有楽町店からトレーナーが来場。肩甲骨の可動域を高めるストレッチを参加者全員で体験
そのアプリではコンテンツをパーソナライズするため、年齢、性別、住所、ダイエットや生活習慣改善、運動不足解消など各種悩み、運動習慣、好きな食べ物、出勤や帰宅時間といったアプリ登録時のデータのほか、食事投稿データ、体重や睡眠、歩数、アプリ内のユーザー操作ログといったデータを収集。分析可能な状態に成形、分析し、サービスの向上と改善に役立てている。
システム全体はマイクロサービスの構成で、各種データを管理するサーバーはそれぞれ分かれている。そのため、ひとりのユーザーがアプリを使うとログがサーバー別で格納されてしまうため、分析の観点からはなかなか悩ましい構成。これをどうやって効率よくデータを集約、分析しやすい状態にもっていくかが課題だったと鈴木氏は話す。
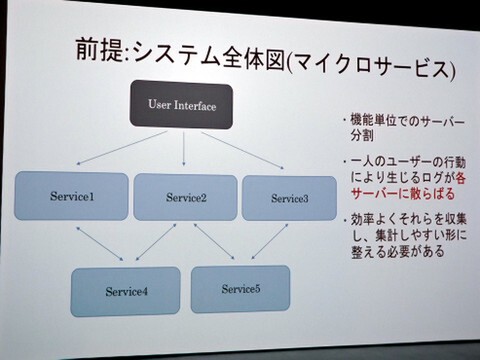
マイクロサービスで構成されるFiNCシステムの課題
まずは、データやログをすべてAmazon Redshift(Redshift)に集約した。集約経路は複数あり、たとえばアプリがサーバーに直接アクセスしたときに発生するユーザーデータは、いったんAmazon Auroraに溜めてから、その後にAWS Database Migration Service(AWS DMS)を使ってRedshiftに送信する。Webサーバーのログについては、fluentdを介してRedshiftに送信。また、ユーザーが何をクリックしたかといったログは、モバイルアプリ内の各種SDKからAmazon Kinesis FirehoseとS3経由でRedshiftに送信するといった具合だ。
「AWS DMSはAmazon Aurora内のbinlogを参照してRedshiftに送るというのをわりと自動でやってくれるので、便利に使っています。といってもよく止まるから、監視は頑張る必要がありますが(笑)」
止まる原因の1つは、binlogの書き込み負荷がかかること。これはデータ同期のタイミングを調整、分散させるなどで対処しているという。
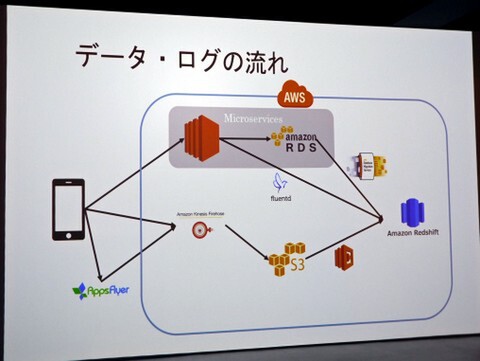
データとログの流れ
収集データの分析は、サマリーテーブル(中間テーブル)で効率化している。たとえばFiNCアプリではユーザーに行動を促すためのプッシュ通知を行なっているが、どのユーザーが通知をいつ受け取り、1時間後、1日後にどんな行動をとったか分析するには、通知サービスのログ、ユーザーの属性情報、ユーザーの活動ログなどを相関付ける必要がある。しかし、これらデータはサービスごとに分かれているため、必要な情報を抽出するには複雑なクエリが必要だ。
そこで作成したのが、バッチ処理を経由して関連データを集約するサマリーテーブル。たとえばプッシュ通知関連のデータであれば、ユーザーがいつどんな通知を受け取り、いつ開封し、1時間後や1日後にどんな行動を起こしたかについて、サマリーテーブルを見れば誰でもある程度理解できるようにした。これにより、SQLを知らないエンジニアでもテーブルを解し、簡単なSQLを叩けるようになったという。
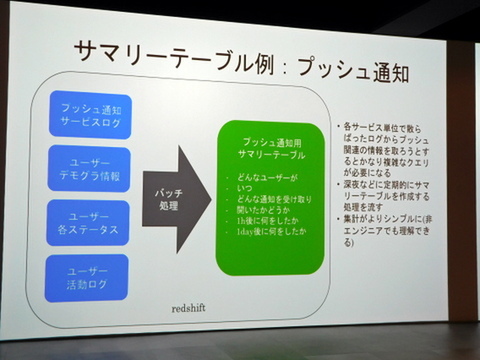
サマリーテーブルで関連データの集計を簡素化
今後は汎用的なデータ活用めざしデータレイク構想も
現在、こうした汎用的なユーザー行動分析から一歩踏み込み、特定目的のデータを収集して分析、アプリ内のコンテンツに反映させる仕掛けを開発中だ。具体的には、アプリ内で表示するコンテンツについて、ユーザーの属性や参照履歴などのデータから、より適したコンテンツをレコメンド表示するというものだ。
最初に考えたのは、RedShiftに蓄積されたデータに対して機械学習によるレコメンドモデルを適用するという流れだ。しかし、ユーザーの行動データ量は非常に膨大で、遅延などの問題が発生する。
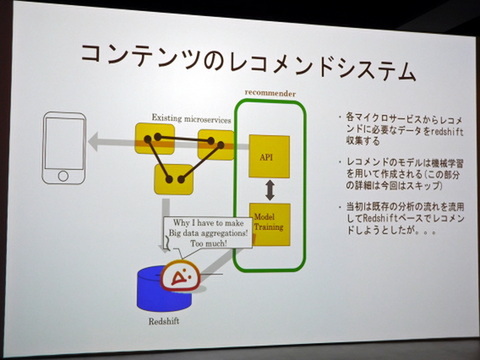
当初考えていたレコメントシステムの流れ
そこで、Redshift内の関連データをCSV形式でS3にエクスポートし、そのデータをベースにAWS Batch上で動いている機械学習モデルが学習、API経由でレコメンドをユーザーに渡すという流れを作った。
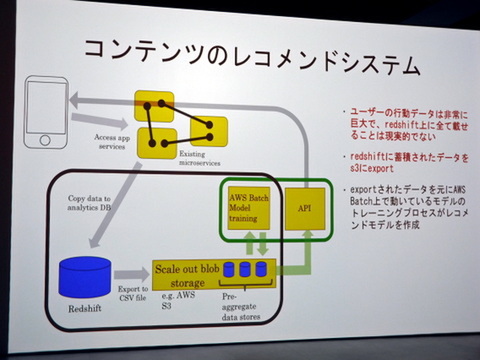
S3をかませた効率的な機械学習+レコメンドのシステムを構築
今後は、汎用的なデータ活用を目指し、データレイク構想を検討中と鈴木氏。
「現行のS3をさらにデータレイクへ発展させて、AWS Glueを組み合わせて汎用データを集約。ユーザーの行動に合った広告を配信するためのデータベース、プッシュ通知用のセグメント管理データベース、AWS LambdaやAWS Athenaを組み合わせた機械学習用データベースなど、目的に応じたデータベースを作成できる仕組みを目指しています」
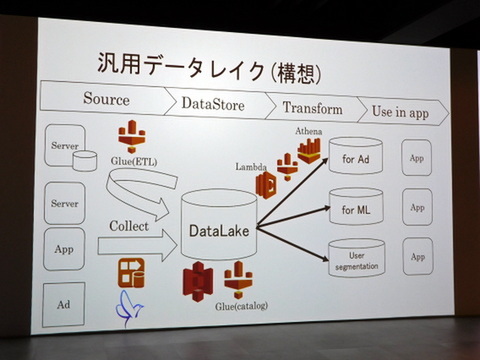
データレイク構想
この連載の記事
-
第26回
デジタル
コロナ禍で社会インフラとなった保育園 ルクミーはこうして支えている -
第25回
デジタル
オンライン診療の規制緩和にいち早く対応したMICINの新機能開発 -
第24回
デジタル
「Cariot」のリアルタイム性を強化するKinesis、Lambda、DynamoDBの整え方 -
第23回
デジタル
Timers、POL、PIAZZAなどがビジネスと技術を語る第10回X-Tech JAWS -
第22回
デジタル
メンヘラ彼女向けのサービスを1週間で開発させられた話 -
第21回
デジタル
教育市場を盛り上げる「AWS EdStart」と「AWS Educate」 -
第20回
デジタル
AIで時事クイズと高校野球の戦評記事を作ってみた -
第19回
デジタル
おやつのサブスク「snaq.me」でのLambda活用術 -
第18回
デジタル
X-Tech JAWSで聞いたナビタイム、Resola、千のAWSの使いこなし -
第17回
デジタル
契約書のレビューを支援するLegalForce、CTOと事業開発担当が語る -
第16回
デジタル
「SQL書きたい」のリクエストにukkaのエンジニアはどう応えたのか? - この連載の一覧へ






















