
AWSとGCPの使い分けや運用を見据えた構築ノウハウを披露
Retty林田さんが語る「分析基盤におけるAWS活用術」
2017年12月19日 07時00分更新

10月20日に開催された「X-Tech JAWS」では、各業種でのAWS活用事例が披露された。FoodTech代表の登壇としたのは、実名制グルメサービスを展開するRettyの林田千瑛さん。AWSと一部GCPを用いることで、2ヶ月という超短期間でデータ分析基盤を構築した事例を披露した。

Rettyの林田千瑛さん
2ヶ月でデータ分析基盤の構築? まあ、やるか
月間利用者数が3000万人を突破した実名制のグルメサービス「Retty」が扱う情報は多岐に渡る。お店やユーザー、料理に関するテキストや写真のほか、ユーザーの投稿、アクセスログなど、現時点で数PBを超える容量を抱えている。2017年5月に入社したばかりの林田さんだが、これらのデータの分析基盤を2ヶ月で作るというお題が落ちてきた。「一応、私の肩書きデータサイエンティストなので、正直インフラエンジニアの仕事じゃねと思ったけど、まあやるかということでやりました(笑)」(林田さん)とわりと豪気なコメントだ。

2ヶ月でデータ分析基盤構築!ムチャブリは人を成長させる
さてデータ分析基盤とは、文字通りデータを蓄積・活用するための共通基盤。KPIの分析やアドテクへの活用、ユーザーへのリコメンド、A/Bテストなどさまざまな用途で用いられる。もちろん、Rettyにも以前からデータ分析基盤はあったが、DWHのテーブル設計の問題で不要なログが全体の9割を占めていたり、データ型が適切でなかったり、JSONオブジェクトがテキスト形式でそのまま入っていたり、いろいろ問題点が多かった。「String型でデータが入っていると、パースするのにリソースを使うので、クエリするのに時間がかかっていた。適切に圧縮されていないので、ストレージ容量も逼迫していた」(林田さん)などが課題だった。
また、マスターデータが別のデータベースにあったため、マスターデータと突合する場合は別の場所にデータを移す必要があったほか、ログが増大していたため、パフォーマンスにもボトルネックが生じていた。「もともと3時間かかっていたバッチが1日かかっていた。気軽にアドホック分析できないので、クエリを投げるときは事前にSlackに報告する運用をしていた(笑)」とのことで運用もけっこう大変。ログデータも1日数十GBになり、正規化されていなかったところもあり、今後はサービスの要件変更に対応しなければならない。こうした課題からクラウドのよさを活かした分析基盤が必要になっていた。

従来のデータ分析基盤の課題
この結果、新しい基盤では「SQLもしくはそれに準拠したクエリ言語で使え、分析者に使いやすい」「列変更や複雑なETL処理などに柔軟に対応でき、追加開発・運用がしやすい」「イニシャルランニングコストが現実的である」「成長中のサービスなのでスケーラブルである」などの要件が求められることになった。こうした要件を満たすべく、作ったのがAWSと一部GCPを組み合わせたデータ分析基盤になる。以下、林田さんはいくつかのポイントについて説明した。
目的にあわせた基盤構築のため、コンポーネントを使い分ける
まず重視したのは目的にあわせた基盤の構築。一口に分析基盤と言っても、蓄積するデータレイク、アドホック分析用にデータウェアハウス(DWH)、目的別に加工・集計されたデータマート(DM)などに分けられる。「やりたいことをが違うので必要な要件も違う。前のように1箇所で全部やらない。要件にあったコンポーネントを利用し、処理を分けています」とのこと。
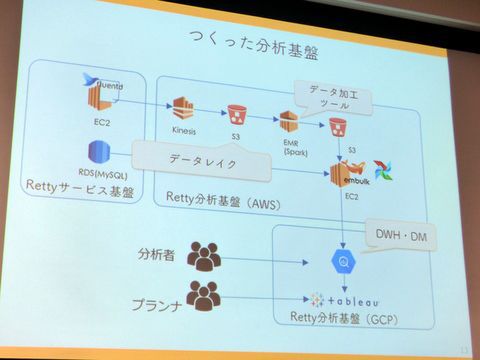
AWSとGCPを用いた新データ分析基盤
具体的にはデータレイクはAmazon S3を採用。「非構造化データをそのまま溜められる」「拡張性や耐久性が担保されている」「同じバケット内でもプレフィックスやタグ付けで柔軟に対応できる」「Kinesis Firehoseを使うことで日時ごとにディレクトリを分けて保存できる」などが大きな理由だ。また、管理のしやすさやネットワーク転送料を考えると、サービスの動いている場所と同じリージョンにデータを保持したいといった背景もあったという。
一方、DWHやDMはGoogle Cloud Platformを利用している。「標準のSQLやスプレッドシートなどが使える」「テーブルの設計変更がしやすい」「安定したレイテンシとスループット」メンテナンスフリー」などが採用の理由。同系統のサービスとしてはAWSにもAmazon Redshiftがあるが、「時間ではなく、クエリ課金がよかった」ということでBigQueryを採用。Amazon S3に対してクエリがかけられるAthenaも当時はバージニアリージョンにしかなかったため、採用を見送った。とはいえ、Amazon S3からGCPへのデータ転送コストがかかるのは悩みどころだという。
増え続けるデータ量に対応する
2つめのポイントはサービス拡大によるデータ量の増大だ。2016年5月に2200万UUだったRettyだが、2017年9月には3000万UUを突破し、今後も増え続けることが予想される。こうしたデータの増加に対しては、ストレージ容量だけではなく、ETLやデータ転送が現実的な時間で終わるか考慮すべきだという。
ETLに関しては、ログが増えてもクラスターを増やせるAWS EMR(Elastic MapReduce)を採用。SQLで処理しづらい非構造化データに対する複雑なETL処理は、Pythonで処理を記述し、Spark上で動作させている(詳細はPyCon2017の発表資料参照)。

EMRのSparkを用いたETL処理
また、ETLの処理順序に関しては、従来のようにデータを整形してDWHにロードするのではなく、いったんDWHにデータをロードしてからDWH上で整形するELTという方式もあった。これに対してRettyでは、不要なログ出力が9割を占めるという理由から、ネットワーク転送する前にフィルタし、SQLで処理できるデータ以外はDWHにはロードされないという。
データ転送はyaml形式で設定ができ、並列での転送やある程度のデータ加工も可能なEmbulkを採用。ただ、「同じスペックでも、インスタンスの種類が違うと、ファイルのディスクリプターのサイズが違うらしく、転送エラーが出たり、出なかったりする」(林田さん)といった課題があった。一連のタスクは50以上に上るため、依存関係の確認やエラー時の解析のためにワークフローエンジン「Airflow」を導入。依存関係が見えやすく、Pythonで処理を書けるAirFlowにより、エラー時のリトライ制御や処理結果のSlackへの通知などを行なっているという。
基盤部分の決定は慎重に とにかく動くモノを作る
さて、構築して以降も戦いは続く。林田さんは、「せっかく分析基盤作ったけど使われない」「運用が超面倒くさい」「随時の要件変更に耐えられない」など分析基盤あるあるを指摘。Rettyでも30人近いエンジニアのうち、インフラを扱えるのは3人くらいしかいないので、1人で抱え込むと大変なことになると指摘した。
また、せっかく早く構築しても長く使われるものにならなければ意味がない。特にDWHの場合は、「作って壊して」が簡単にできないため、要件ヒアリングや製品・技術選定、PoCなど基盤部分の決定は慎重に行ない、環境構築やスクリプト作成などは実質3週間で進めた。さらに、エンジニア以外でも使いやすいよう設定等を工夫する一方、最初の2ヶ月はCIやテスト実装、ドキュメンテーション、コーディングスタイルなどの優先度を下げ、とにかく動くモノを作ったという。

長く使われることを意識し、基盤部分の決定を重視
最後、ヘビーなセッションを終えた林田さんは、AWSからGCPの転送速度やコストなどの質問に答える。Amazon S3とBigQueryを併用する際のコストに関しては「蓄積やクエリに比べると、転送料金は圧倒的に大きい」とのことだが、前述の通りクエリ課金の方が魅力的だったことと、Redshiftだと多少なりともインフラの管理が必要になることから、現状ではBigQueryがよいという判断だ。今回のX-Tech JAWSでもっともテッキーなセッションだったが、普段なかなか聞けない人気サービスのデータ分析インフラの舞台裏を聞けるとあって、質問も飛び交い、会場の関心も高かった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第26回
デジタル
コロナ禍で社会インフラとなった保育園 ルクミーはこうして支えている -
第25回
デジタル
オンライン診療の規制緩和にいち早く対応したMICINの新機能開発 -
第24回
デジタル
「Cariot」のリアルタイム性を強化するKinesis、Lambda、DynamoDBの整え方 -
第23回
デジタル
Timers、POL、PIAZZAなどがビジネスと技術を語る第10回X-Tech JAWS -
第22回
デジタル
メンヘラ彼女向けのサービスを1週間で開発させられた話 -
第21回
デジタル
教育市場を盛り上げる「AWS EdStart」と「AWS Educate」 -
第20回
デジタル
AIで時事クイズと高校野球の戦評記事を作ってみた -
第19回
デジタル
おやつのサブスク「snaq.me」でのLambda活用術 -
第18回
デジタル
X-Tech JAWSで聞いたナビタイム、Resola、千のAWSの使いこなし -
第17回
デジタル
契約書のレビューを支援するLegalForce、CTOと事業開発担当が語る -
第16回
デジタル
「SQL書きたい」のリクエストにukkaのエンジニアはどう応えたのか? - この連載の一覧へ






















