




前回まで各社の製品ロードマップのアップデートをお届けしたが、ついでに先端プロセスに関してもいろいろ話題が出てきたので、これをファウンダリー別にまとめておこう。今回は台湾セミコンダクター・マニュファクチャリング・カンパニー (TSMC)の話題だ。

世界最大の半導体製造ファウンダリーであるTSMC
画像提供:TSMC
そのTSMC、報道関係者向けにはほとんど情報を開示しないのだが、今年5月に米国でテクノロジー・シンポジウムを開催した。このシンポジウムにCadence社が協賛している関係で、同社のブログにその概要が掲載されている(その1)(その2)。この情報を基に概略を紹介していく。
10FFプロセスの大口顧客はApple
iPhone 8に搭載されるA11チップを全力で製造中
まずロードマップ概観である。下の画像は昨年10月のものだが、ハイパフォーマンス向けを見ると28HP/28HPMを経て、ごく一部の製品を除くと20SoCをスキップして16FF+に移行。そして10FFを経て2017年中には7FFのRisk Production(リスクありの先行生産)にこぎつける、というものだった。
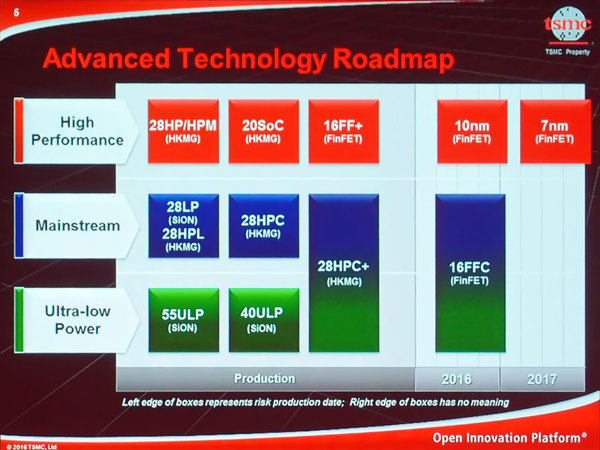
ARM Technical Conference 2016におけるTSMCのセッションより。それぞれの左端がRisk Production開始の時期(右端には意味はなし)だそうである
このうち昨年の段階ですでに28HP/28HPM~16FF+は量産に入っており、10FFのRisk Productionも始まっていたのは事実である。あとは今年中に7FFのRisk Productionに入れるかどうか、というあたりが見所と思われていた。
そこから半年たった今年5月におけるロードマップは、以下のようになる。
| 2017年のTSMCロードマップ | ||||||
|---|---|---|---|---|---|---|
| ハイパフォーマンス | 10FF→7FF→7FF+ | |||||
| メインストリーム | 16FFC→12FFC→7FFC | |||||
| ローパワー/IoT | 55ULP/28HPC+→28ULP→22ULP→12FFC/ULP | |||||
ここでハイパフォーマンス向けとはハイエンドスマートフォン、HPC、Automotive、Gameと定義されており、CPUやGPU向けプロセスということになる。メインストリームは数が一番出るメインストリームスマートフォンや自動車関連向け、ローパワー/IoTはそのものズバリで、組み込み機器向けということになる。
CPUやGPU向けは「公式には」現在の16FF+の次に10FFが来ることになっており、TSMCによればProduction Qualification(量産向けの品質確認)が完了。すでに量産そのものも開始されており、同社のGigaFab 12とGigaFab 15で今年後半に本格量産が開始される予定だ。

Fab 12a

Fab 15
画像提供:TSMC
TSMCの計画では、今年中に10FFで製造するウェハーを40万枚出荷予定としている。その最大の顧客がAppleなのも間違いないと思われ、同社のiPhone 8に搭載されるという噂のA11チップの製造が全力で開始されているはずだ。
ただAppleのA11を除くと、多くの顧客がこの10FFをスキップし、次の7nmに向かおうとしている。比較的早くからこれを表明したのがXilinxとAppliedMicro(現MACOM)であるが、GPUメーカーも同様の判断をしているらしい。
TSMCの公式発表では、10FFは16FF+と比較して消費電力が40%削減され、性能が20%向上、エリアサイズを50%削減できるとしているが、GPUベンダーにとってはこの数字では十分ではない、としている。
もっともこのあたりはターゲットの市場次第であって、例えばARMなどは同社のCPU IPとGPU IPのPOPを10FF向けに提供する予定なようだ。逆に言えばモバイル向けには10FFは悪くない(それ以外は悪い)というのがもっぱらの評判で、ちょうど同社の20SoCと同じような運命を辿りそうである。
それもあってか、TSMC自身が10nmについては“Long-lived node”とは表現していない。要するに長期間使われるプロセスと考えてはいないということだ。同社は後述する12FFCが“Long-lived node”になるだろう、としている。
したがって、16FF+を使ってモバイル向け以外の製品を作るユーザーは、次期製品のプロセスをどうするかについて悩むことになった。インテルが14+や14++、あるいはGlobalFoundriesが14LPP+をリリースする理由がそこである。

画像提供:TSMC
インテルは10nmがやや後ろに押していることもあり、そこまでのつなぎとして14nm世代を改良した14+と、さらに14++もリリースすることを明らかにしている。GlobalFoundriesも同じで、同社は10nmはスキップするので、次は7nmになる。そこまで待てない顧客(主にAMD)向けに、14LPP+を提供する。
ちなみにサムスンは10nmを無事に立ち上げて2016年中から量産を開始しており、すでに10nmで製造されたSoCが搭載されたスマートフォンが市場に出ている状態である。同社は10nmをやはりLong-lived nodeと位置づけており、14LPPの改良版などを手がける予定はない。
ではTSMCは? というと、本来は16FF+の次に10FFが来るわけだが、立ち上がりが予想よりやや遅れた(とはいってもAppleのA11の製造には間に合ったようだが)うえ、多くの顧客が10FFを拒否している。その最右翼がNVIDIAであった。
かくしてNVIDIAは、連載413回で説明した通り、16FF++とでも言うべき独自プロセス(NVIDIAの表現では12FFN)を自社製品に使うことをTSMCに認めさせるに至った。
これはNVIDIAのような大口顧客だからこそ可能な技でもある。NVIDIAは昨今のAIブームのおかげで売上も好調であり、GPGPU向けに数量はともかくウェハー数としてはかなりの量をTSMCから購入している。
とくにVoltaのGV100コアは、800mm2ものダイであり、歩留まりを考えると、今年必要とするウェハーだけで1万枚を超えるかもしれない。もしもGV100に続きGV104やそのローエンドのGV106などまで使うと、NVIDIA一社だけで10万枚くらいのウェハーを購入することになるだろう。
これだけの枚数を購入してくれるのならば、それはカスタムプロセスを作っても採算が合うだろう。逆に言えば現時点でもまだTSMCは12FFNを自社のロードマップに載せておらず、これはあくまでNVIDIA向けの特注ということになる。
この連載の記事
-
第770回
PC
キーボードとマウスをつなぐDINおよびPS/2コネクター 消え去ったI/F史 -
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ - この連載の一覧へ














が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")









