




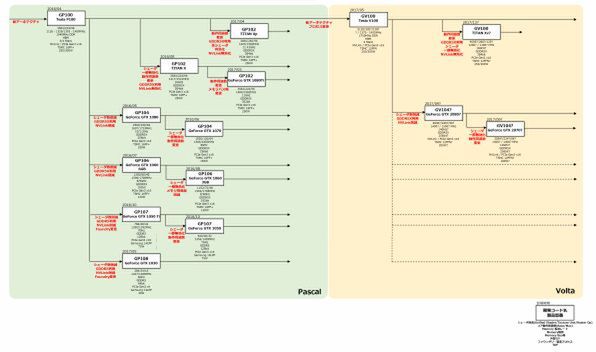
2016年~2017年のNVIDIA GPUロードマップ
Volta世代のGV100コア製品を発表
Volta世代最初の製品がTesla向け、というのは予定通りであり、今年5月のGTCでTesla V100としてGV100コア製品が発表された。
とりあえずTesla V100は連載373回で解説したように、Power9と組み合わせる形でオークリッジ国立研究所のSummitとローレンス・リバモア国立研究所のSierraに納入が予定されている。まずはこれ向けの量産が最優先となる。
Summitの場合では、トータル4600ほどのノード1つあたり2つのPower 9と6つのVoltaが搭載されるので、まずは2万8000枚弱のVoltaカードをNVIDIAは量産せねばならない。Sierra向けも合わせると4万枚弱といったあたりで、これが一段落するまで少なくともGV100コアに関しては派生型などを考えるのは難しいだろう。
Tesla V100の12nm FFNプロセスは
16FF+に6トラックのスタンダードセルを適用
このGV100でもう1つ問題になるのはプロセスである。GTCの基調講演では“TSMC 12nm FFN”とあったが、実はこれはNVIDIA専用のカスタムプロセスである。まずこの話を改めてしておこう。

NVLink版のTesla V100。新しいVoltaアーキテクチャーのGPUで、ディープラーニング用のTensor Coreを搭載する
TSMCは16nm世代で大きく3種類のプロセスを用意した。16FF、16FF+、16FFCである。最初のものが16FFでFinFETの第1世代である。ただこれは量産前の試行とでもいうべきもので、量産製品のほとんどは16FF+という16FFの改良版を利用している。NVIDIAのPascal世代が全部これである。
この16FF+のコストを下げたコンパクト版が16FFCとなる。なぜか最新のTSMCの16nmのページでは説明が省かれているのだが、Googleのキャッシュに残された以前の説明によれば“TSMC also introduced a more cost-effective 16nm FinFET Compact Technology (16FFC). This process maximizes die cost scaling by simultaneously incorporating optical shrink and process simplification”と説明がなされている。
プロセス構成をやや簡単化するとともに、Optical Shrinkをかけて若干エリアサイズを小型化した、低コスト版の16nm FinFETプロセスである。
さてこれに続き、今年3月にTSMCがアナウンスしたのが12FFCである。これは、プロセスの物理的なパラメーターそのものは16FFCそのままである。もともと16FF+→16FFCの際にOptical Shrinkを実施しているが、これはたかだか数%という比率でしかないらしい。
つまりトランジスタのサイズそのものは、ほとんど16FF+と違いがない。例えば縦横1%縮小しても面積比では2%の縮小、寸法を5%縮められれば面積で1割削減になるため効果的ではあるのだが、一方でFinFETの世代では寸法をいじると急激に物理特性が変わってしまうので、いじるといっても影響のない範囲にとどめる場合、そんなに大きく変更はできないことになる。
しかも16FF+→16FFNで一度Optical Shrinkを行なっているので、さらなる縮小はかなり厳しい。実際には少しだけ余分にShrinkの度合いが増えているらしいが、ほとんど違わないそうだ。
ところが12FFCでは、16FFCと比較して9~12%の面積削減と15%の消費電力削減が可能、というのがTSMCの説明である。これは、スタンダードセルを6トラックにしたことで実現した。
スタンダードセルのサイズを縮小して小型化と省電力化、というのはかつてAMDがCarrizoでやった方法である。Carrizoの場合は12トラックのセルを9/7.5トラックで再設計しなおすことで面積を30%削り、消費電力を下げることにも成功したが、その代わり性能が上がらなくなっている。
この「性能が上がらない」は12FFCにも言えることで、したがって12FFCはメインストリーム向けのモバイルSoC向け、という位置づけになっていた。
ということで話を12FFNに戻す。こちらは端的に言えば16FF+に6トラックのスタンダードセルを適用した構造になっている。一応こちらにもOptical Shrinkをかけてはいるが、性能を犠牲にしないために、あまり大きく寸法をいじれなかったようで、結果トランジスタの寸法は16FFCよりも大きいらしい。つまり、サイズ縮小の効果は主にスタンダードセルに6トラックのものを利用したことに起因する。
その効果はあったのか?といわれれば、おそらくあったのだろう、という答えになる。Tesla V100のホワイトペーパーによれば、以下のようになっている。
| 各コアのスペック | ||||||
|---|---|---|---|---|---|---|
| コア名 | GP100 | GV100 | ||||
| アーキテクチャー | Pascal | Volta | ||||
| ダイサイズ(mm2) | 610 | 815 | ||||
| トランジスタ数 | 153億 | 211億 | ||||
| SM数 | 60 | 80 | ||||
ここから以下のように算出できる。
| ダイサイズの算出 | ||||||
|---|---|---|---|---|---|---|
| コア名 | GP100 | GV100 | ||||
| SMあたりのダイサイズ | 10.17mm2 | 10.19mm2 | ||||
| 1億トランジスタ当たりのダイサイズ | 3.986mm2 | 3.863mm2 | ||||
1億トランジスタあたりのダイサイズは微減、というあたりだがSMあたりのダイサイズは微増である。ただ実際にはVolta世代ではSMの中にTensor Coreと呼ばれるテンソル演算用のユニットが追加されている。
さらに共有メモリーサイズも若干増やされており、この増分を吸収してほぼPascalと同等のエリアサイズを実現するには、12FFNの採用が必須だった、ということだと思われる。逆に言えば、12FFNを使ってもそう大きくエリアが削減できるわけではない、ということでもある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












