「見える」からわかる!システム障害の原因をあぶり出すテク 第7回
異なる視点から「見える」2つのツールを組み合わせ、迅速な解決を目指す
「QoEダッシュボード」と「AppStack」でトラブル解決してみる
2016年03月08日 09時00分更新

QoEダッシュボードとAppStackは補完的な役割を持っている
●今月のトラブル発生!
最近、社内の文書共有に利用しているSharePointサーバーへのアクセスが遅い。社内からもたびたびクレームが上がっており、早く対処しなければならない。
しかし、当社の情シスはサーバー/仮想化担当、ネットワーク担当、ストレージ担当、アプリケーション担当と、担当者が分かれている。それぞれにほかの業務も抱えており、全員で原因調査に取りかかるのは時間の浪費だ。あらかじめ原因を絞り込めたら効率的なのだが……。
本連載ではこれまで、アプリケーションへのレスポンス遅延の原因を追究するためのツールとして「QoEダッシュボード」(第2回)や「AppStack」(第6回)を紹介してきた。これらはそれぞれ異なる視点(取得データ)からシステム状態を可視化してくれるツールであり、組み合わせて使うことで補完的に機能する。
今回は、QoEダッシュボードとAppStackで何が「見える」のか、それぞれの違いをおさらいするとともに、これらを組み合わせて迅速な原因切り分けを行う実例を見てみたい。
監視の“視点”が異なるQoEとAppStack
QoEダッシュボードは、ネットワークの視点から“ユーザー体感品質(Quality of Experience)”の変化を可視化するツールだ。「Network Performance Monitor(NPM)」や「Server & Application Monitor(SAM)」のライセンスがあれば利用できる。
QoEの大きな特徴が、「ネットワーク側の問題」なのか「アプリケーション側の問題」なのかを簡単に判断できる機能だ。具体的には、アプリケーションとのデータ通信シーケンスを「TCP 3wayハンドシェイクにおけるレスポンス」と「アプリケーションデータの返信までにかかるレスポンス」の2つに分けて計測/分析し、可視化してくれる。前者のレスポンスタイムが大きい場合は「ネットワーク側の問題」、後者が大きい場合は「アプリケーション側の問題」と判断できるわけだ。
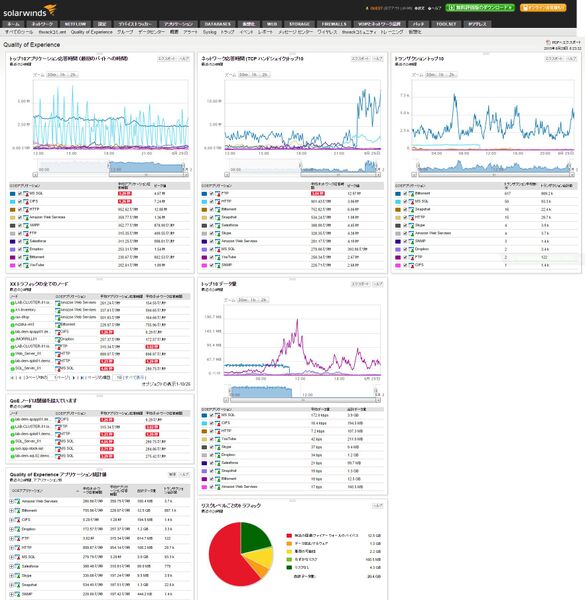
QoEダッシュボードの画面。問題の原因がネットワーク側/アプリケーション側のどちらかを容易に判断できる
他方、AppStackは、アプリケーション側の視点から見るツールである。アプリケーションの動作は多数のコンポーネント(物理サーバー、仮想サーバー、OS、ストレージ、アプリケーションと幅広い)により支えられている。そのため、障害やレスポンス遅延の原因がどのコンポーネントにあるのかを正しく判断しなければ、迅速な問題解決にはつながらない。そこでAppStackでは、各コンポーネントの稼働状態をシンプルなアイコンの一覧で可視化する。
前回も紹介したとおり、AppStackが便利なのは「このアプリケーションを構成している(=動作に影響を与える)コンポーネントはどれか」を簡単に調べられる点だ。その逆に、構成するコンポーネント側から、障害によって影響を与えうるすべてのアプリケーションを調べることもできる。
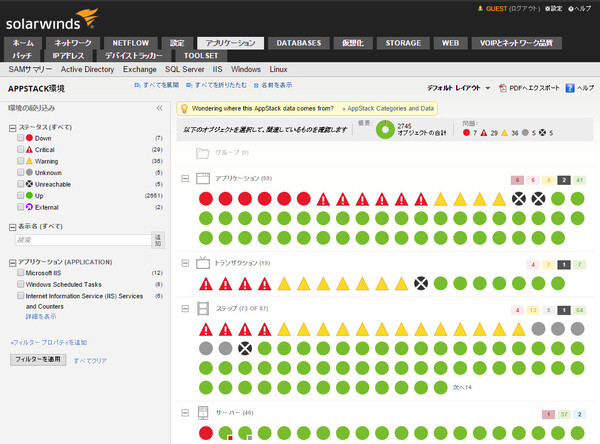
AppStackの画面。アプリケーションの稼働を支えるインフラコンポーネントの構成を簡単に調べられる
ただし、AppStackが可視化するコンポーネントに「ネットワーク」は含まれていない。したがって、QoEとAppStackを組み合わせてトラブルシューティングを行う場合は、次の順番で実行することを原則とすればよいだろう(下図参照)。

QoEダッシュボードとAppStackを組み合わせてトラブルシューティングを行う場合の順序
この連載の記事
-
第6回
デジタル
アプリ障害の原因はインフラのどこに?「AppStack」が簡単解決 -
第5回
デジタル
適切なNW増強計画のために「NTA」でトラフィック量を可視化 -
第4回
デジタル
「UDT」で持ち込みデバイスのネットワーク接続を監視する -
第3回
デジタル
何十台ものネットワーク機器設定、その悩みを「NCM」が解消する -
第2回
デジタル
ネットワーク?サーバー?QoEダッシュボードで障害原因が見える -
第1回
デジタル
なぜ、いま運用管理の“バージョンアップ”が必要なのか - この連載の一覧へ
")











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")











