




32Bytes幅のDual Ringを採用
実質的な帯域はIce Lakeの2倍以上
次いでDual Ringの話。下図はPhelp氏の説明をもとにおこしたものだが、UncoreからCPUとGPUで別々のRingにするのではなく、UncoreとCPUコア、およびGPUコアをすべてまたがる形でRingが構成されているが、ただしそれが二重になっているというものだ。なので、それぞれのCPUコアやGPU、Uncore部はすべて2つのRing Stopを持つ形になる。
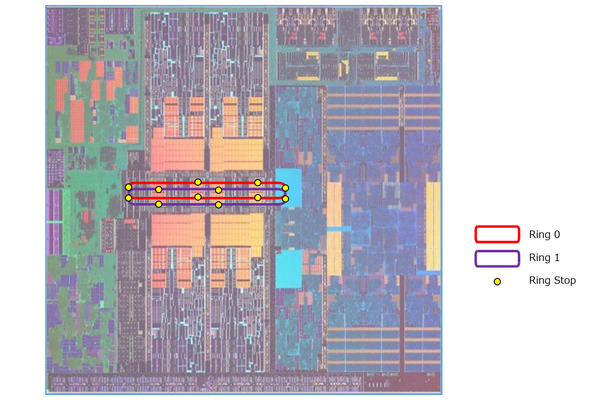
UncoreとCPUコア、およびGPUコアをすべてまたがる形で、32Bytes幅のRingが構成されている
ちなみにRingそのものは従来と同じ32Bytes(256bit)幅である。この2つのRingを、それぞれのCPUコアなりGPUなりは自由に利用できる。つまり、ピークでは64Bytes(512bit)幅のデータアクセスができることになる。AVX512のLoad/Storeなどが1サイクルで行える形だ。
「だったらいっそ64Bytes幅のRing1つでも良かったのでは?」と尋ねたところ「それではRing Stopまでが遠くなりすぎる」との返事。
256bit幅のRingと512bit幅のRingでは配線の難易度が変わってくるのは明白で、実装を考えると256bit×2の方が楽だったのだと思う。
ただ、すでにSandy Bridgeあたりの世代からキャッシュラインは64Bytesになっているので、CPUからのアクセスという意味では64Bytes幅の方が実装は楽だとは思う。
実効性能という意味では、Ice Lakeでは内部のRingの速度は最大3GHzとなっており、一方Tiger Lakeではこれを超える速度で動いているそうで、実質的な帯域は2倍を超えることになる。
もっともTiger Lakeの世代ではその分、GPUからメモリーコントローラーに最大64GB/秒の帯域保障を提供する(一種のQoS)機能なども実装されており、これをフルに使った場合は片方のRingの帯域の半分以上(多分2/3近く)が占有されてしまうことになるため、Dual Ring化は必須だったとも言える。
そのDual Ringに絡んでもう1つおもしろい機能がIO Cachingだ。これは「I/OデバイスがLLCに直接アクセスできるもの」だという。
通常I/Oはメモリーに対してDMA(Direct Memory Access)を利用してデータの転送を行なう。例えばSSDから読み込んだファイルの内容は、SSDの内容をSSDコントローラー→PCI Express経由でまずメモリーに格納され、次いでそのメモリーの内容をCPUが読み込むという順で行なわれる。
DMAはその名の通り、直接I/OデバイスがCPUを介さずにメモリーを読み書きできる機能で、これにより無駄にCPUを使わずにデータ転送が完了するのだが、いちいちメモリーに書き込んで、また読み出すのは時間がかかる。
IO CachingはDMAの対象をメモリーではなくLLCに行なえるというものだ。これにより、CPUはメモリーアクセスなしで直接LLCからデータを読み込めるようになる。
もっともこの仕組み、ドライバー側でこれにきちんと対応しないといけない。またIO Cachingに利用されるLLCは排他(通常のキャッシュ領域とは分けて考える)にしないといけない。
データがやってきてからおもむろにキャッシュを確保していたら、そのレイテンシーの方がメモリーアクセスより遅くなりかねないためだ。となるとOS側の対応も必要になりそう(少なくともプラットフォームのCPU用ドライバーに手を入れる必要はある)である。
加えて言えば、上の例でこのIO Cachingを有効にすると、ファイルアクセスの場合はメモリーではなくLLCを参照するようにしないといけないわけで、これはOSそのものにも関係しそうな気がする(ファイルシステム周りのデバイスドライバーの改修だけで済めばいいのだが)。
以上のことから、これが実際に利用できるようになるのにはやや時間がかかるだろう。とりあえずTiger Lake搭載ノートが市場に出たとして、その時点でのWindows 10はおそらくIO Cachingには対応できないだろう。このあたりの対応スケジュールはインテルというよりもOSベンダーに確認する必要があるだろう。
そういえばGNA(Gaussian and Neural Accelerator) 2.0であるが、2.0になっても新機能や機能拡張といったことは一切なく、純粋に性能と性能/消費電力比を改善した「だけ」とのこと。

アクセラレーターであるGNA 2.0は、性能と性能/消費電力比を改善しただけとのこと。なおArchitecture Dayでは、mWの消費電力でテラOpsの処理性能を持っているとの説明があった
もっとも性能は最大30GOP/秒に達しており、消費電力の改善やCPU負荷率の低減などと相まって、より使いやすくなったそうだ。
実際Tiger Lakeでの発表会においても、ノイズキャンセリング機能への実装(テレビ会議をしている人の後ろで掃除機がかけられていても、話者の声が明瞭に相手に届く)という形でそれがデモされていた。
この連載の記事
-
第772回
PC
スーパーコンピューターの系譜 本格稼働で大きく性能を伸ばしたAuroraだが世界一には届かなかった -
第771回
PC
277もの特許を使用して標準化した高速シリアルバスIEEE 1394 消え去ったI/F史 -
第770回
PC
キーボードとマウスをつなぐDINおよびPS/2コネクター 消え去ったI/F史 -
第769回
PC
HDDのコントローラーとI/Fを一体化して爆発的に普及したIDE 消え去ったI/F史 -
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 - この連載の一覧へ
























