国内の”知の最前線”から、変革の先の起こり得る未来を伝えるアスキーエキスパート。坪井聡一郎氏による技術とイノベーションについてのコラムをお届けします。
ソフトバンクのAIスピーカー参入
いよいよわが国にも、AIスピーカーの普及が本格化しそうな状況だ。6月4日付の日経新聞によると、ソフトバンクがロボット開発ベンチャーのプレンゴアロボティクスと提携し2017年内に発売するとしている。
petoco
また国内では、NTTドコモがフォーティーズ株式会社と共に、コミュニケーションデバイス「petoco(ペトコ)」を共同開発したと5月末に発表したほか、シャープも同時期に開催された「AWS SUMMIT」の展示ブースにて音声対話ソリューションのデモを行なっている。
LINEは今春バルセロナで開催されたMWC(Mobile World Congress)にて参入表明し、AIプラットホームを韓国の親会社ネイバーと共同して開発。日本語、韓国語で作動するという。また同じ韓国企業であるサムスンは「Galaxy S8 / S8+」へ搭載予定の音声アシスタント「Bixby」の音声機能につきリリースが遅れており、追加テストを行なっていると報じられた。

HomePod
アメリカではAppleの「Siri」、Amazonの「Alexa」、Microsoftの「Cortana」、Googleの「Google Assistant」がしのぎを削っており、日本時間6月5日深夜に開催されたWWDC2017の基調講演でアップルが「HomePod」を発表。この市場では後発であることやハードウェアメーカーであることなどから、「スピーカーの良さ」を強調しているが、早晩AI化を進めていくのは想像に難くない。このようにAIスピーカー市場は風雲急を告げている。
インターフェースの変遷

現在主流になりつつある音声インターフェースに至るプロセスにおいては、実にさまざまな「入力インターフェース」の変遷があった。ここで簡単にUI(User Interface)の概念についておさらいをしたい。
●CUI(Character User Interface)/CLI(Command Line Interface)
コンピューターへのコマンド入力に際し、キーボードを使って文字入力を行なうインターフェース。
●GUI(Graphic User Interface)
グラフィックを使用した視覚的表現で、直感的に操作できるインターフェース。キーボードとともにマウスを使用する(スティーブ・ジョブズらがLisaやMacintoshに採用したエピソードは有名)。
●NUI(Natural User Interface)
「ナチュラル」という言葉が意図するのは、スマホで使われているタッチ操作、ジェスチャーによる操作、音声対話などを包括し、より直感的に扱えるインターフェースを表した概念。CUI、GUIに続く新たなUIとして期待される。
近年のUIは、NUIの進化プロセスをたどっていると言うことができる。2007年のiPhone発売以降タッチ操作は飛躍的に進化し、それまでの抵抗感圧式タッチパネルから静電容量式へ大きく移行。ガラス基板回路の普及、on-cell/in-cell方式の改善もあり、操作レスポンス向上や薄型化が進み一気にタッチ操作が主流となった。
アップルは2006年時点でiPodを音声で作動させる特許を申請しており、2010年4月にSiri社を買収取得している。わが国でも、NTTドコモが2012年に「しゃべってコンシェル」を開始しているが、こちらも2006年頃より進めていたフュートレック社やATRとの共同研究をサービス化したものである。
一方ジェスチャーによる操作は、2009年に当時MITの学生であったプラナフ・ミストリーを避けて語ることはできない。「次なる可能性を秘めたSixthSense」と題されたTEDプレゼンテーションは世界の度肝を抜いた。市販されているデバイスを組み合わせ、ネット空間とリアル空間を行き交うデモンストレーションは、そのジェスチャー操作の新奇性も含めて多くの称賛を集めた。過去のTEDプレゼンテーションの中でも最高の物の1つと呼ばれており、お時間があればぜひご覧になって頂きたい。
2010年に発売されたMicrosoftの「Kinect」では、RGBカメラ、深度センサー、マルチアレイマイクロフォンを搭載し、プレイヤーの位置、動き、声、顔を認識することができる仕様であった。LEAP motionなどが実現した近距離型ジェスチャー操作も注目を集めた。「映画『マイノリティリポート』のように、サイバー空間から自由にかつフィジカルに情報アクセスする未来」が期待されるようになったのはこの頃からである。
「感情を認識する」affective computing
しかしその後、ジェスチャー認識については小休止を迎えている(正確にはARやVRのHMD操作などでさまざまに応用されている)。代わって進展してきたのは、人の感情を認識する技術であった
SNSを通じて多くの写真がアップされるようになりその写真が誰のものであるのかタグ付けが進んだことで、顔認識の教師付きデータが多数得られるようになった。そこに機械学習の進展が加わった。今や画像認識で世界最高精度を誇るのはFacebookとも言われている。この顔認識技術を発展させ、人間の感情や情緒を認識する新たな技術として注目されているのが「affective computing」という領域である。
MITの研究により発展したと言われるこの新たなインターフェースは、パッシブ・センサーのみで「喜び」「悲しみ」「驚き」「悔み」といった人間の感情を読み取る。この技術をもとに創業されたのがaffectiva社である。これがどんな形で応用できるのか? 1つの例としてエンターテイメント事業のケースが考えられる。

affectiva社
たとえばある映画を制作する際に、興行的に成功するか否かはなかなか見通せないものである。有名な映画監督や俳優を配しても必ずしも成功するわけではない。しかし、もし仮にラッシュや試写の段階で観客の反応が分かればどうであろうか。上映中の観客の表情を撮り続けて、感情の変化を分析することができれば、観客の注目シーンがどこであったのか、あるいはつまらないシーンはどこなのかを判断することができる。思っていたほど盛り上がらない、お涙頂戴のシーンであっても観客が泣いていないといった状況が把握できれば、部分的に再編集することも可能である。
また動画広告を放映する場合、A、B、C、Dなどタイプ別に編集されたものを見せ、アンケートにより評価が高かったものを流すことがあるが、こうした際にも視聴者の反応を分析して良いタイプを選別することが可能である。人間には「本音と建て前」があり、アンケートに書いたものが本当に良い反応のものとは限らないからである。ほかにも、TVにセンサーを備えることができれば、視聴率とは別の形で視聴者のリアルな反応を掌握することも可能だろう。昨年、CEOのRana el Kaliouby氏にお話を伺った際には、さらに複雑な状況下での感情認識にもチャレンジしていきたいと抱負を語っていた。
話者識別の課題と分離収音技術
話を音声インターフェースに戻し、その課題についてみていきたい。同じくMITのCynthia Breazeal准教授などによって手掛けられた家庭向けロボット「Jibo」は単なるBOTではなく「話者の感情を認識し」「自分自身も感情表現を行なうことができる」という特徴をもっている。
動画では、「Jibo」が複数話者の中から「誰が何を話しているのか」を識別する。音声を聞き分け、該当する画像(顔や人)と結びつけることができる。あまりに動画が流麗に表現されているので気づきにくいかもしれないが、この「特定の人と画像・音声を結び付けること」は非常に難しい。
例として、複数人が同時発話した状況を考えてみる。話者人数分のマイクを使い指向性を調整すれば、データソースも明確になり識別することは難しくはない。しかし1つのマイクを使用してそれを行なおうとする場合には、音声データは塊として収音されるため個別の人に分ける特徴量の識別が困難になる。
私のような素人は「声紋分析を応用できるのでは?」と考えてしまうが、リアルタイム処理を要求されるインターフェースとして利用するには、まだ克服しなければならない課題が多いようだ。そのほかにも画像は画像認識、音声は音声認識として別々に開発されたことなどの事情もあり、画像と音声を紐づけるのは多くの企業が難儀している。「Jibo」はその分類と結び付けが可能であり、個人ごとに発言や嗜好、興味関心、といったものをAIによって学習していく。
このように複数の人が同時に話しても1人ひとりの音声を聞き分けられる話者識別は、個人の行動をとらえるデータに直結するため、それを実現する「分離集音技術」への期待が大きく研究も進んでいる。
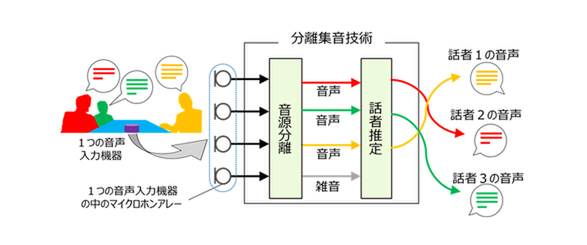
東芝の分離集音技術
昨年東芝が国立情報学研究所と共同開発した技術は、事前学習無しの状態で6人の同時発言を識別する。三菱電機は5月に「ディープクラスタリング」で1つのマイクから拾った複数人の音声を、従来法を大きく上回る精度で解析し再現するデモンストレーションを披露した。これは「ディープラーニング」と「クラスタリング」を組み合わせた同社独自のAI技術である。近年のこうした研究成果からも分かるように、音声インターフェースは「1つのスピーカーから取得した複数人の会話を、AI化活用して分析し、話者を特定していく」方向へ進んでいる。
今後のインターフェースの方向性
改めて今回のテーマは「AIスピーカーの先のインターフェース」であり、今後の進化の方向性についていくつか私見をまとめたい。
1.室内の常時センシングによる行動把握
アメリカではすでにBOTが普及しており利便性を感じている人も多く、今後「1部屋に1台」設置することも十分に予想される。AIスピーカーの正常進化として画像の撮影機能が追加され、affective computingが示すように音声と映像の一体的な紐づけが行なわれるようになるだろう。その上で個人をより正確に掌握するためのデータ取得が進むと考えられる。
就寝時の呼吸状態や非接触血圧などのバイタルデータ、あるいは、食卓に並ぶ食事からカロリー推定や栄養バランスをみることも可能になるかもしれない。また今のモデルの多くはテーブルに置けるようなデザインがされているが、部屋全体をセンシングしやすい天井照明のような位置に設置されることも考えられるだろう。
2.より使いやすいインターフェースの探求
今回のWWDC2017では、82歳になる日本人女性が開発者として呼ばれたことが話題になった。ご高齢であることも話題となった一因だろうが、注目すべきは「手先の敏感な動きが要求されるスワイプ操作は、シニア世代にとっては難しい操作」と語られたように、彼女の持つ開発視点である。企業で開発する際の労働者の世代は20代から60代が中心になる。それ以上の世代のユーザビリティー(たとえば80代以上向けのインターフェース)は的確に掌握できていない部分も出てくるだろう。
これまでのインターフェースは、画一化され全世代が利用するユニバーサルな設計が推奨されることも多かった。ユニバーサルデザインとしての良さも理解した上で、正確な個人の「使い勝手の良さ」が把握できるようになれば、ユーザーに応じたインターフェースの変更を行なうことも考えられるだろう。
3.円滑なコミュニティーの形成
Facebookが先に開催したF8の中で「教会を中心としたコミュニティー」においてメッセンジャーを使ったお祈りの配信が行なわれているということが語られていた。数多く信者を抱える場合、従前では管理者の負荷が大きく手間のかかった1人ひとりに適したメッセージを送ることも容易にできるようになる。学校やサークル、そのほかさまざまなコミュニティーを活性化させるためのインターフェース開発も進むことだろう。
先述したジェスチャーUIは、HMDなどを装着したユーザーの腕の動きを読み取り、VR/ARの動きとして取り入れられたりしている。ヴァーチャル空間のコミュニティー形成に、フィジカルなジェスチャーUIがリアリティーを持たせる要因につながっているとも考えられる。
また、富士通が2015年に発表した「FUJITSU Software LiveTalk」は、聴覚障がい者参加型コミュニケーションツールで、複数人の同時発言も話者を特定した形で時系列にテキスト表示できる。さらに近年は多言語対応も行なっており、クロスモーダルかつボーダレスなインターフェースとして、企業のようにダイバーシティーを促進しコミュニティーを活性化する重要なツールとなるであろう。
4.感情を伴ったフィードバック
ピクサー・アニメーション・スタジオの製作する映画には、感情表現豊かな擬人化されたおもちゃやロボットなどが躍動する。「ロボットのような反応」という表現があるが、それは過去のものとなる可能性がある。
たとえば「Jibo」は対象者へのフィードバックも単なるオウム返しではなく、感情表現を加えてコミュニケーションができる。相手が「怒っている」あるいは「悲しんでいる」など判断し、状況に応じた反応を返すのだ。BOTやAI音声インターフェースのコミュニケーションの未来として「空気を読む」インターフェースも希求されると考えられる。
若干余談になるが、一般的な音声インターフェースでは、以下のように、対話のきっかけ自体を人間側が作ることが多い。
人間「おはよう」
BOT「おはようございます」
人間「今日の天気を教えて」
BOT「東京の今日の天気はおおむね晴れです」
しかし「Jibo」は、自ら会話の発端となることができる。この技術もとても難しいとされる部分である。「無の状態」からコミュニケーションをつくるためには、対象者の興味関心や人数・時間帯、前後関係など、さまざまな要因をくみ取って発話する(あるいは別アクションをする)ことがロボット側に求められる。
我々人間でも「話題の選択」はセンスが問われるところである。しかし個人ごとのセンシングが進み銘々のタイムラインが把握できていれば、ロボットが「場の空気を読んだ」発話を行なうことも可能であろう。ユーザーが海外出張から自宅へ戻った翌朝、「おはようございます。出張の疲れは取れましたか?」とBOTが語りかけてくるのも決して遠い未来の話ではない。
TVやエアコンのリモコン、エレベーターのボタン操作など、旧来より指摘されていても変わっていないものの方が多い。このように現状のUIはまだまだ不便を感じるところも多いものの、さまざまな事情からイノベーションが妨げられている。「インターフェースはマネタイズが難しい」という人もいるが、私はそうは思わない。ユーザーが提供されているインターフェースを所与として受け入れてしまって無意識下に諦めている可能性は大いにある。ユーザー本人すら気づいていないニーズへのアプローチ(いわゆるインサイト)は、今後ますますマイニングされていくだろう。個人の行動データは取得しやすくなっている。チャンスは大きいと考えている。
アスキーエキスパート筆者紹介─坪井聡一郎(つぼいそういちろう)

一橋大学大学院商学研究科修了。2004年株式会社ニコン入社。ブランディング、コミュニケーション、消費者調査、デジタルカメラのプロダクト・マネジャー等を歴任。2012年より新事業開発本部。2014年、国立研究開発法人農業・食品産業技術総合研究機構より「センシングによる農作物高付加価値化」の研究委託を受け、コンソーシアムの代表研究員を務めた。経産省主催の「始動Next Innovator2015」のシリコンバレー派遣メンバーであり、最終報告会の発表者5名にも選抜された。2016年より大阪イノベーションハブにおいて「OIH大企業イントルプレナーミートアップ」を主宰している。