




ビッグデータ分析導入の第1ステップとしてデータレイク構築を
ビッグデータ分析を導入していくためのステップとして、大川氏は再び、まずは「データを溜める」ことからスタートするべきだと強調した。データを一カ所に集約してデータレイクを構築し、そののちに簡易的な分析によってビッグデータ活用の可能性を探り、徐々に深化させていくというストーリーだ。「ポイントは、最初からステップ4(本格的なビッグデータ解析)を考えようとしないこと」(大川氏)。
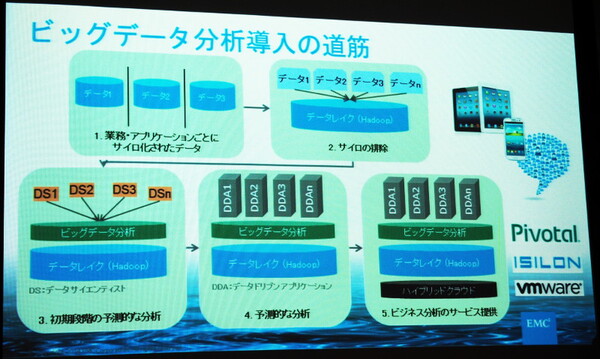
EMCが考えるビッグデータ分析導入の道筋
国内事例として大川氏は、ある大手サービスプロバイダーの事例を紹介した。この企業では、ログデータの集計処理をHadoopで行っているが、ログデータが1日数TBクラスまで増大し、データ準備がバッチ処理に間に合わない(遅延する)事象が多発。そこで、Isilonを用いたペタバイトクラスのデータレイクを構築することで、毎時のバッチ処理を可能にした。「この顧客でも、HDFSへの変換が不要であることが大きなポイントになった。現在は他サービスへの展開も検討されている」(大川氏)。

この事例もまだ「初期段階の分析」ステップだが、「それでも日本では最も先進的な部類に入るのでは」と大川氏
最後に大川氏は、EMCでは、新規顧客向けにIsilonと商用Hadoop「Pivotal HD」をバンドルした「データレイクHadoopバンドル」ソリューションや、既存のIsilon顧客向けの無償版Hadoop(Pivotal HDやCloudera CHD)スターターキットを提供していることを紹介した。




