




株式会社Laboro.AI
日本語音声コーパスとして最大規模 2,000時間の音声データから構成
株式会社Laboro.AIは、ワンセグTV録画から抽出した約2,000時間の音声データから構成される音声コーパス『LaboroTVSpeech』を開発し、学術研究用に無償公開いたしました。 <今回のポイント> ・︎ 日本語音声コーパスとしては最大規模の約2,000時間のデータ ・︎ TV番組に含まれる音声と字幕データから、音声コーパスを自動構築するシステムを開発 ・︎ 既存の音声コーパスより優れた誤認識率を達成し、商用の音声認識APIにも匹敵する精度を確認

オーダーメイドによるAI・人工知能ソリューション『カスタムAI』の開発・提供およびコンサルティング事業を展開する株式会社Laboro.AI(ラボロエーアイ、東京都中央区、代表取締役CEO椎橋徹夫・代表取締役CTO藤原弘将。以下、当社)は、当社の研究開発として、TV録画から長時間音声と字幕テキストを抽出して音声コーパスを自動構築する独自システムを用い、約2,000時間に及ぶ音声データから構築した日本語音声コーパス『LaboroTVSpeech(ラボロティービースピーチ)』を開発し、学術研究用に無償公開いたしました。
LaboroTVSpeechは、B-CASカードによるアクセス制限がないワンセグ放送を利用しており、複数ジャンルの計9,142番組のTV録画から抽出した約2,000時間の音声データから構成されています。研究用途として代表的な日本語話し言葉コーパス(CSJ:約600時間)や新聞記事読み上げ音声コーパス(JNAS:約90時間)など、これまで公開されている日本語音声コーパスと比較しても最大規模のものです。当社比較実験の結果では、LaboroTVSpeechで構築した音声認識モデルが従来の研究用日本語音声コーパスで構築したモデルを凌ぐ誤認識率となり、さらに商用で提供されている主要な他社製クラウド音声認識APIにも匹敵する誤認識率を確認いたしました。
なお、本年12月2日(水)・3日(木)に開催される(一社)情報処理学会 第246回自然言語処理・第134回音声言語情報処理合同研究発表会にて、LaboroTVSpeechについての報告を実施予定です。
本件について詳細は、以下もしくはこちらのPDF版プレスリリース(全文)からご確認いただけます。
https://prtimes.jp/a/?f=d27192-20201113-2182.pdf
背景 ― これまでの音声認識モデルと音声コーパス(※1)
一般的に音声認識モデルの性能は、その学習データの量に大きく左右され、高品質な音声認識システムを構築するためには大規模な音声コーパスが必要とされています。そのため、英語モデルの開発の場合には、商用目的では数千~数万時間を超える音声データが用いられることもあり、研究目的でもSwitchBoard-Fisherデータセット(約2,000時間)やLibriSpeech(約960時間)などの大規模な音声コーパスが公開されています。
一方、日本語の音声コーパスについては、研究用として代表的な日本語話し言葉コーパス(CSJ※2)で約600時間、新聞記事読み上げ音声コーパス(JNAS※3)で約90時間など、英語と比較すると十分なデータの音声コーパスが存在しているとは必ずしも言えないのが現状です。
この背景としては、音声コーパスの構築に際して書き起こしや録音作業など、人手による手間やコストがかかることが理由として挙げられます。その対応として、これまで人手の作業を伴わず自動的にデータ収集を行う手法が模索されてきました。その一つの方法として挙げられるのが、テレビ放送を用いた音声コーパスの自動構築です。多くのテレビ番組には字幕情報が付与されているため、音声と字幕のテキスト情報を時間的に紐付けることで、コーパスを自動構築できる可能性が示されてきました。

しかしながら、字幕は視聴者にとっての読みやすさを優先して作成されているため、必ずしもテレビ音声の正確な書き起こしにはなっていません。そのため、音声コーパス構築の自動化を行うためには、以下をはじめとする点に留意する必要があり、その実現ハードルは高いのが実際です。

- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
※1 コーパスとは、言語情報を大量に集積したデータベースのことを指します。
※2 国立国語研究所、情報通信研究機構 (旧通信総合研究所)、東京工業大学が共同開発した話し言葉データベース。
※3 日本音響学会が公開している新聞記事を読み上げた音声コーパス。
LaboroTVSpeechについて
今般当社で構築した音声コーパスLaboroTVSpeechは、B-CASカードによるアクセス制限がないワンセグ放送を利用し、2020年2月~9月にかけて放送された、12ジャンル(デジタル放送規格の番組種別)計9,142番組のテレビ番組の録画データを用いており、2,049時間に及ぶ音声データから構成された大規模音声コーパスです。当社では、LaboroTVSpeechをアカデミア領域でのAI技術研究に広く活用いただくことを目的に、学術研究用に無償で公開することといたしました。
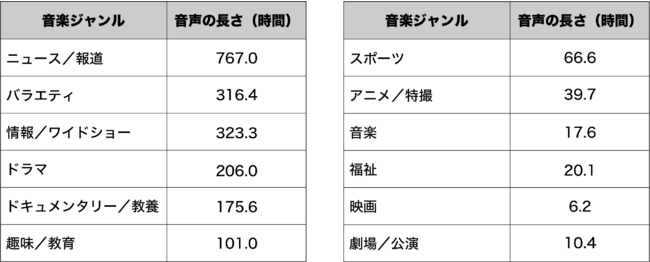
(LaboroTVSpeechを構成する番組ジャンルと音声の長さ)
LaboroTVSpeechは、当社が独自開発したシステムにより構築しています。具体的には、テレビ番組の長時間の音声データと、その不完全な書き起こしである字幕データの時間的な対応関係を抽出する手法である準教師付きデコーディング(lightly-supervised decoding)と呼ばれる手法をベースとしています。これにより、本来であればテレビ番組のデータから音声と字幕がセットになって抽出されるべきところ、先のような何らかの問題で対応した情報として取得できなかった場合に、準教師付デコーディングによる音声と字幕の対応関係の抽出を繰り返し行うことで、一度対応が取れなかった区間からも可能な限りデータ抽出を行う仕組みを採用しています。
なお、LaboroTVSpeechについては、本年12月2日(水)・3日(木)に開催される(一社)情報処理学会 第246回自然言語処理・第134回音声言語情報処理合同研究発表会にて報告を予定しています。
LaboroTVSpeechの比較実験について
LaboroTVSpeechを用いたモデルの音声認識の性能を確認するため、日本語のTEDxを用いて構築した独自の音声認識システム評価用データセット(※4)を用意した上で、従来の日本語音声コーパスCSJで学習されたモデル及び、国内外の主要なクラウド音声認識APIとの比較実験を行いました。その結果、当社開発モデルが従来の研究用日本語音声コーパスで構築したモデルを凌ぐ誤認識率を達成しました。さらに商用で提供されている他社製クラウド音声認識APIとの比較では、LaboroTVSpeech用いることで主要な大手グローバル企業が提供するAPIにも匹敵する誤認識率を確認いたしました。
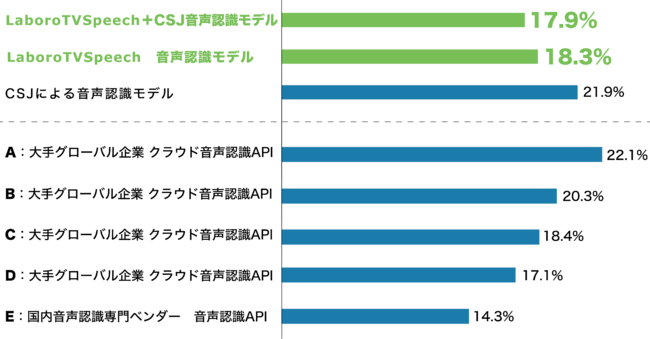
(日本語TEDコーパスに対する誤認識率(CER:Character Error Rate)の比較(※5)
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
※4 YouTube上のプレイリスト「TEDx talks in Japanese」に含まれる動画から、1万発話文の音声とその字幕データを取得した上で、人手で修正を加えたものです。
※5 クラウド音声認識API の評価は、全てデフォルトの音響モデル及び言語モデルを用いて実施しています。上記の結果は、実環境での音声認識システムの性能とは異なる場合があります。
LaboroTVSpeechの今後の可能性
LaboroTVSpeechの利点は、テレビ放送をデータソースとしていることからデータ量を絶えず増加させることが可能な点にあります。当社ではLaboroTVSpeechのデータ量を増強するために定期的なアップデートを実施し、公開することで、国内におけるAI音声認識分野の技術力向上に寄与してまいります。

LaboroTVSpeechの利用について
LaboroTVSpeechに含まれる音声及びテキストデータの権利は、元のテレビ放送の著作権者に帰属していますが、著作権法30条の4に基づき、情報解析等の用途のために、大学等の学術研究機関における非商用利用を対象に当社ホームページ(https://laboro.ai/column/eg-laboro-tv-corpus-jp/)にて無償で公開いたします。ただし、元のテレビ番組の音声を再構成し鑑賞する事を防ぐために、発話単位でランダムに並び替えられており、かつ番組名や放送局等の付加情報は含まれておりません。
営利企業における研究開発用途や商用目的での利用をご希望の場合は、当社ホームページのお問い合わせフォーム(https://laboro.ai/contact/other/)からのご相談をお願いしております。
株式会社 Laboro.AIについて
Laboro.AIは、オーダーメイドのAIソリューション『カスタムAI』の開発・提供を事業とし、アカデミア(学術分野)で研究される先端のAI・機械学習技術をビジネスへとつなぎ届け、すべての産業の新たな姿をつくることをミッションに掲げています。業界に隔たりなく、様々な企業のコアビジネスの改革を支援しており、その専門性から支持を得る国内有数のAIスペシャリスト集団です。
<会社概要>
社 名:株式会社Laboro.AI(ラボロ エーアイ)
事 業:機械学習を活用したオーダーメイドAI開発、およびその導入のためのコンサルティング
所在地:〒104-0061 東京都中央区銀座8丁目11-1 GINZA GS BLD.2 3F
代表者:代表取締役CEO 椎橋徹夫・代表取締役CTO 藤原弘将
設 立:2016年4月1日
URL : https://laboro.ai/







ピックアップ
-

sponsored
有線/2.4GHz/Bluetoothを選べるトリプルモード接続&クリック音アリナシも選択可能
我が家の「深夜うるさい問題」を解決する静音ワイヤレスゲーミングマウス「ED-G3MPRO」
-

sponsored
200mmファンにダスト検知機能!エアフロー最強ケース「ProArt PA602」をレビュー
-

sponsored
JN-GMM1IPS28BKをレビュー
PS5の実力も引き出せる28型4K/144Hz、KVMまで使える万能モデルが7万円はコスパ◎!
-

sponsored
なぜクラウドストレージに切り替える企業が増えているのか
ファイルサーバー/NASとクラウドストレージの違いとは?《基本編》
-

sponsored
購入しやすい価格ながら機能充実、バッテリー長持ちの人気製品
1万円以下ウェアラブルの大定番がさらに進化! 睡眠モニタリング精度アップの「HUAWEI Band 9」レビュー
-

sponsored
eスポーツ大会で採用される24インチクラスの新モデル
180Hzで3万円切りの即買いモデル、スピーカー内蔵のゲーミングディスプレー「G255PF E2」レビュー
-
が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")
sponsored
新たな敵は地中から現れる!
さらなる刺客(シカク)が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック
-

sponsored
JN-MD-OLED156UHDR-Tをレビュー
15.6型4K有機ELのタッチ対応モバイルディスプレーと16型IPSのWQXGAモデル、どちらを買うべきか
-

sponsored
大阪・泉州産のスウェット生地を採用した「AKRacing by BEAMS DESIGN モデル」
スウェット生地のチェアってどう? 編集部員何人かに座った感想を聞いてみた
-

sponsored
セブンアールジャパンの西川氏とASRockの原口氏にコダワリを聞いてきた
パソコンショップSEVENとASRockのコダワリが炸裂! Threadripper PRO 7995WX搭載BTOPC
-

sponsored
従来よりもさらにコスパよくゲーミングPCを組みたい方へ
ゲーミングマザーボード「GAMING PLUS」シリーズ完全解説&自作のオススメ構成例も紹介
-

sponsored
強化ガラス製マウスパッド「ROG Moonstone」など気になるデバイスもまとめて試す!
静音性重視の独自スイッチ“ROG NX Snow”がイイ!「ROG Strix Scope II 96 Wireless」をレビュー
アスキーストア's 人気ランキング ベスト5






