



レイトレーシングにDLSS、RTコアやTensorコアの役割、自動OCテスト機能まで!
Turingコアの構造も謎の指標「RTX-OPS」の計算方法も明らかに!徐々に見えてきたGeForce RTX 20シリーズの全貌
2018年09月14日 22時00分更新

謎の指標“RTX-OPS”の計算方法が明らかに
さて、RTX 20シリーズが発表されたスペシャルイベントでは「RTX-OPS」なる新しい性能指標が登場した。言うまでもなくRTX独自機能を利用して処理する能力を比較するためのものだが、RTX 2080 Tiが78T RTX-OPS、RTX 2080が60T RTX-OPS、そしてRTX 2070が45T RTX-OPSとされている。
78T RTX-OPSなら、1秒間に“RTX-OP(RTXの処理)”を78兆回実行できることを示す(ちなみに78TのTの読みはテラが正式のようだ。ジェンスン・ファン氏はTrillionと読んでいたが……)。
ではそもそもRTX-OPSとは何を指しているのか? 既存のGTX 10シリーズは一体何RTX-OPSなのかも解説しておきたい。
1)ハイブリッドレンダリング
RTX 20シリーズで初めてリアルタイムレイトレーシングがハードウェア的に実装されたわけだが、ゲームはもちろんOS(正しくはAPIレベルだが)もレイトレーシングに対応する必要がある。
現在RTX 20シリーズはNVIDIA独自のAPI「OptiX」のほかに「Vulkan」、そしてWindows10のOctober 2018 Updateで盛り込まれる予定のDirectX Raytracingこと「DXR」に対応する。RTX 20シリーズ発売時点でレイトレーシング対応ゲームがないのも無理からぬ話だ。

RTXテクノロジーを構成する要素。1番下がRTX 20シリーズ独自のハードウェアで、RTコアを使ったレイトレーシングのほかに既存のCUDAコアによるラスタライゼーション、AIなどがあり、それらの機能はDXRなどのAPIを通じて行なわれる。そして、DXRやVulkanなどのへアセットデータを渡す規格が1番上のMDL(Material Definition Language)となる。
今後はゲームをこれらの機能をフル活用して作る体制を整えるというのがNVIDIAの戦略だが、レイトレーシングとラスタライゼーションはお互いの良いところを両立させながら使っていくことになる。RTコアで捌けるレイの数には限界がある今、ゲームのすべてをレイトレーシングで構築するのは無理だからだ。
この2つの手法を併用してレンダリングするのを“ハイブリッドレンダリング”と呼ぶが、Turingを使って1フレームをハイブリッドレンダリングした時にどのコアがどの程度働くかを示したのが次の図だ。
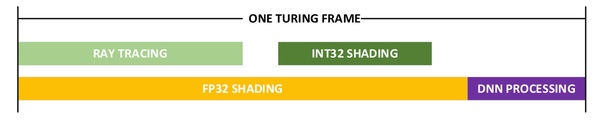
Turingでハイブリッドレンダリングを行なった時の各処理がどの程度の割合かを大雑把に見積もったもの。長いほど時間を取られる処理であることを示すが、当然ゲームによりこの長さは変化する。「いろんな処理をさせてみたところ、こんな塩梅になることが多い」ぐらいに考えておきたい。
2)各コアの仕事量
上の図では、まずRTコアでレイの衝突判定と、CUDAコアの内FP32演算機でジオメトリシェーダーやピクセルシェーダーといったゲームではお馴染みの処理が並列して動く。RTコアの処理時間は、FP32の処理時間のおよそ半分程度になるようだ(※1)。
RTコアでレイトレーシング処理が終わると、今度はCUDAコアの内INT32演算機でテクスチャーなどの処理が実行される。FP32とINT32の処理時間比はおおよそ100:35に落ち着くことが多いようだ(※2)。前述の通り、TuringはFP32とINT32の演算機が分けられているため、両者は並行して処理を進められる。
最後はDNN、Tensorコアでディープラーニングを利用した処理が行なわれる。ここではDLSSを使った処理が想定されているようだ。これは全体の処理時間の20%程度を占める(※3)。
つまり、RTX-OPSとは、上のような「典型的な“Turingでのハイブリッドレンダリング1フレームぶん”の仕事をさせた時の各部の仕事量の総和」を示すものだ。FP32/INT32/RTコア/Tensorコアそれぞれの仕事量(係数)と各コアのピーク演算性能を掛け、それの合計を求めればよい。
3)実際の計算
では上の図から掛け合わせる係数を求めてみよう。RTX 20シリーズのホワイトペーパーによると、係数は次のように求めるとある。
・CUDAコア:FP32演算性能の80%+INT32演算性能の28%……(1)
・RTコア:RTコアの演算性能の40%……(2)
・Tensorコア:Tensorコアの演算性能の40%……(3)
さらにわけのわからない数値が出てきた。まず最後Tensorコアの処理が全体の約20%(前述※3)を占めるのだから、FP32の仕事量は差し引き80%、そして、FP32とINT32の仕事比は100:35(前述※2)だから、INT32の仕事は80%の35%なので28%(1)となる。そして、RTコアの仕事量はFP32の半分だから、80%の半分で40%(2)。正直なところ何がどういう理屈なのかさっぱりだが、実際にこうホワイトペーパーに書いてあるので、そのとおりに計算してみよう。
例として、RTX 2080 Ti Founders EditionのRTX-OPSを計算する。
・FP32の演算性能=14.2TFLOPS
14.2T×0.8=11.36T RTX-OPS
・INT32の演算性能=14.2TIPS
14.2T×0.28=3.98T RTX-OPS
・Tensorコアの演算性能
113.8T×0.2=22.76T RTX-OPS
・RTコアの演算性能(10GigaRays=100TFLOPS)
100T×0.4=40T RTX-OPS
最後のRTコアの演算性能の計算は、RTコアの処理をPascalでソフトウェア・エミュレーションをさせた時にFP32の演算性能10TFLOPSで1Giga Raysという結果をベースにしている。RTX 2080 Ti Founders EditionのRTコアは10Giga Raysなので、100TFLOPS相当というわけだ。ともあれ、これらの結果を合算すると次のようになる。
・合計 11.36T+3.98T+22.76T+40T=78.1T RTX-OPS
若干の端数は出たが確かにRTX 2080 Ti=78T RTX-OPSという結果が得られることが確認できた。RTX 2080や2070も同様に計算できる。
では既存のRTX 10シリーズではどうか……というと、RTX-OPSの正しいところは計算できない、というのが正しい答えだ。Pascal世代のGPUにはINT32演算機がないため、CUDAコアでゴリゴリ計算するが、INT32の計算中はFP32の計算ができない。さらにRTコアもCUDAコアによるソフトウェア・エミュレーションになるため、ここでもFP32の計算とは並列化できない。
ゆえに、RTX-OPSを求めたくてもコアの設計が古すぎてハイブリッドレンダリングを意味有るスピードで並列処理できないので、RTX-OPSは求めたくても求められない、ということになる。
ただし、これはあくまでRTコアやTensorコアを駆使するハイブリッドレンダリングの時の性能であって、従来型のゲームではほぼ意味をなさない指標であることは強調しておきたい。
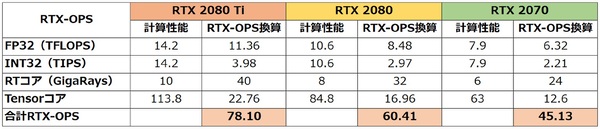
各GPUのスペックをもとに、RTX-OPSをホワイトペーパーの通りに計算したところ、スペック表とほぼ同じRTX-OPS値が得られた。
本記事はアフィリエイトプログラムによる収益を得ている場合があります








&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")


