



「AWS Solution Days 2017」で披露された国内2社のグローバル先端事例
もうオンプレには戻らない、リクルートとドコモがデータ分析基盤をAWSへ移す理由
2017年08月08日 10時30分更新

“日本の大企業は米国に比べてITの最先端トレンドにキャッチアップするスピードが遅い”と言われることが多いが、ことAWSクラウドの導入に限っていえば、グローバルでも引けを取らず、むしろ先進的な導入事例も少なくない。特にここ最近は、データアナリティクスのコアとしてRedshiftやAthenaといったAWSのマネージドサービスを積極的に活用するエンタープライズが増えている。
本稿では、そうした国内企業の中でも最先端のデータアナリティクス基盤をAWS上に構築する「JAWS-UGビッグデータ支部」の2社、リクルートテクノロジーズとNTTドコモの事例について、7月5日に東京・大崎で開催された「AWS Solution Days 2017 ~ AWS DB Day ~」に登壇した両社の発表内容をもとに紹介したい。
EMRで“キャパシティプランニングの呪縛”から解放された:リクルートテクノロジーズ
“リクルートグループが展開する数多くのサービスの価値を最大化し、ITの側面からサービスを進化させること”をミッションに事業を展開するリクルートテクノロジーズ。同社は数多くのデータ処理基盤を稼働させているが、その中でもHadoopクラスターの運用に関してはグローバルでもトップクラスの実績を誇る。オンプレミス主流の時代からHadoopを運用してきた同社だが、現在はAWSがHadoopのマネージドサービスとして提供する「Amazon EMR(Elastic MapReduce)」も積極的に活用している。

リクルートテクノロジーズ ITソリューション統括部 ビッグデータ部 渡部徹太郎氏
セッションに登壇したリクルートテクノロジーズ ITソリューション統括部 ビッグデータ部 渡部徹太郎氏はEMRを「計算処理だけを行う、使い捨ての分散計算環境」と表現。オンプレミスのHadoopと比較したEMRのメリットとして、次の点を挙げた。
- 計算機能とストレージ(S3)が分離している
- 環境構築に手間がかからない
- ハードウェアのメンテナンスが必要なく、コードによる構成管理が可能で不要になったリソースを破棄できる
- スケールアウトが容易で、データの移動が必要ない
- スケールアウトの限界が(ほぼ)ない
- クラスターの利用料は1時間単位での従量課金
「オンプレミスのHadoopは環境構築も運用も死ぬほど面倒。ちょっとだけ(Hadoopの計算を)使いたいというニーズにはまったく向かない。また、スケールイン/スケールアウトが(EMRに較べて)非常に遅い」(渡部氏)。
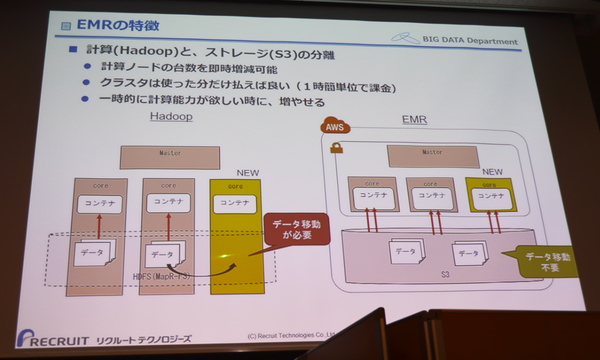
オンプレミスのHadoopと比較したEMRの優位点はいくつもあるが、運用でとくに効いてくるのはデータ移動が必要ないという点。データストアとしてクラウド上のオブジェクトストレージであるAmazon S3を利用できるため、スケールが劇的に容易になる
ここまで聞くと完全にEMRに分があるように思えるが、渡部氏は「EMRにも使いにくい部分があるので、リクルートテクノロジーズではそうした部分を補う独自拡張を実施している」と説明する。
例えばEMRはマスターノードのIPアドレスを固定できないため、ジョブ開発者がジョブの進捗をHadoopのWeb UIで見ることができない。そこでELBをロードバランサーではなく固定FQDNを備えた簡易リバースプロキシとして立て、定期的にEMRのマスターノードに紐づけるWeb UI用のコネクタとして活用している。
また、EMRではHiveクエリの実行が面倒で、開発効率が非常に悪いため、対話的にクエリを実行できる独自クライアントを開発したという。「分析者はあれこれ悩みながらクエリを変えて叩いていくので、結果がすぐに確認できて、引数を変えるだけでクエリを実行するクラスターを変更できるクライアントが必要だった。分析者は同じAPIを頻繁に叩きがちだが、APIの結果をキャッシュできるようにしたことで効率性を高めた」と渡部氏。手軽に利用できる分散処理環境とはいえ、UI/UXに関しては業務にあわせたチューニングが必要なケースも多いようだ。
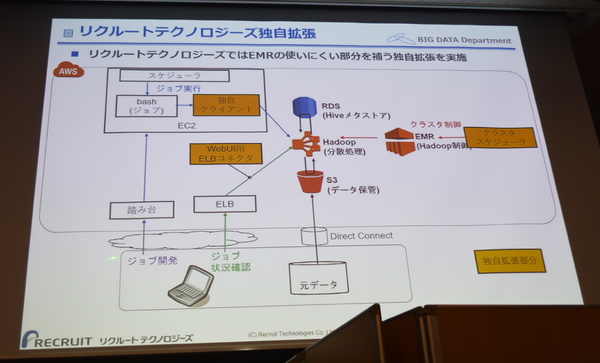
リクルートテクノロジーズではEMRをさらに使いやすくするためにいくつかの独自拡張を行っている。本文中で紹介したもののほかにも、スポットインスタンスの利用を可能にしてコストを抑えるクラスタースケジューラを自作している
EMRで一晩に50ジョブ、30TB以上のデータを処理
ではリクルートテクノロジーズでは具体的にどういった業務でEMRを活用しているのだろうか。渡部氏は一例として「カスタマーとクライアントのマッチングをマシンラーニングで支援」したケースを挙げている。「カスタマー(約1万アクティブユーザー)とクライアント(1万件)のマッチングをバッチ処理で計算し、営業業務の大幅な工数削減を実現、さらにKPIモニタリングデータをBIツールに連携してデータドリブンな意思決定を支援する」(渡部氏)という事例で、毎晩50以上のジョブ、30テラバイト以上(ORC + Snappy圧縮)のデータを処理するという大規模なものだ。
この計算処理をオンプレミスのHadoopで行おうとすると、「施策の領域によって対象のカスタマーの量が変わるので、キャパシティプランニングが困難」(渡部氏)という課題にぶつかってしまう。だがEMRであれば、必要なときに必要な分のクラスターを使えることができるため、キャパシティプランニングの呪縛から解放されることになる。さらにEMRであれば、Hadoopがもつ強力な分散計算能力も利用できるだけでなく、既存(オンプレミス)のHadoopプログラムをそのまま動かせるので、移行工数も低く抑えることが可能だ。
「EMR以外にもクラウドでの移行先を検討していたが、SQLベースの分析ではどうしても物足りない部分が出てくる。自然言語解析やマシンラーニングを実行できるHadoopはやはり魅力的で、その計算能力をオンデマンドで利用できるEMRのメリットは大きい。データ格納にはクラウドストレージのS3を使えるので、データ容量の制限がなくなり、定期的なデータの棚卸しも必要なくなった」(渡部氏)。
リクルートテクノロジーズでは、開発のスピードを加速したいとき、一時的にクラスターの台数を増やすことを通称“界王拳”と呼んでおり、開発効率を上げているという。クリックひとつでいくらでもスケールできるクラウドサービスらしい呼び名だ。「リクルートは“勢いが命”の会社。やることが常に変化しており、3カ月後に必要なキャパシティを予測することは困難。2週間後に何が起こるのか、誰もまったくわからない」と渡部氏。そんな予測不能なニーズに対しても界王拳さながらのパワーとスケールでもって迎え撃てるEMRのようなサービスは、今後のリクルートの事業を支える鍵のひとつとなるに違いない。



