




前回に引き続いて、今回も「Haswell」の詳細を解説する。まずは追加された「AVX2」命令から説明しよう。
HaswellでのAVXの強化
1サイクルで256bitの演算が可能に
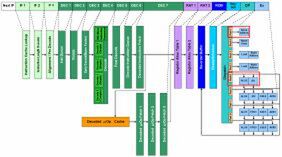
図1 Haswellの内部構造図。赤枠内がSandy Bridgeからの主な変更部分
AVX2命令は、Sandy Bridge世代で投入された「AVX」命令の機能と性能を拡張するものである。大きなポイントは以下の3点だ。
- 性能が2倍
- 浮動小数点のFMA(Fused Multiply-Add)演算をサポート
- いくつかの新命令を搭載
まず性能が2倍の根拠はなにか。Sandy Bridge世代でのAVX演算は、既存のSSE用演算器を流用して実装されていた。SSEはご存知のとおり、1サイクルあたり最大128bitの演算を行なう(関連記事)。そのためAVX演算の場合は、128bitずつ2回に分けて演算を行なうことになっていた。
これに対してHaswellでは、SSE演算器がすべて拡張され、AVXにあわせて1サイクルあたり256bitの演算が可能になっている。そのため、従来だと2サイクルを要していた演算が全部1サイクルで可能となり、これだけ見れば性能が倍になった形だ(Photo01)。ただし、残念ながら「それならSSEを使えば、1サイクルあたり2つのSSE命令が実行できる」とはいかない。あくまでもAVX命令を使った場合のみ有効である。

1サイクルあたりのSSE/AVX/AVXの演算可能な数。Single Precision(SP、単精度浮動小数点演算)なら1サイクルあたり最大32個。Double Precision(DP、倍精度浮動小数点演算)でも1サイクルあたり16個が演算可能になっている
次のFMA(Fused Multiply-Add)とは、乗算と加算が混じった形の演算である。
- A=A×B+C
この演算を1回で行なうというものだ。実はこの形の演算は、自然科学の分野では非常に広範囲で使われており、シミュレーションを初め多くの分野で利用されている。AVX命令もこのFMAをサポートしているのだが、Sandy Bridgeの世代では整数演算でしか利用できなかった。Haswellではこれを、浮動小数点演算に拡張した点が大きな差となっている。
この連載の記事
-
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 -
第853回
PC
7つのカメラと高度な6DOF・Depthセンサー搭載、Meta Orionが切り開く没入感抜群の新ARスマートグラス技術 - この連載の一覧へ

中古ノートPC,SSD512GB/軽量1.38kg/パソコン/日本語キーボード/WIFI/HDMI/USB3.1 (整備済み品)")

 FMVWK3E175_AZ")

")




















")












")
+380 5色マルチパック BCI-381+380/5MP 長さ:5.3cm 幅:13.9cm 高さ:10.75cm")

 扉付タップラン 電源タップ 延長コード 125V 3m 3個口 ホワイト WBT-N3030B(W)")
 2025 用/iPad 第10世代 2022 用 10.9インチ フイルム ガイド枠付き 強化 ガラス 保護フイルム あいぱっど 11世代/10世代 対応 NTB22I574 1枚")
/iPad 各種対応(シルバー 0.9m)")




