




5月23日、日本IBMは企業のビッグデータ活用を支援するソフトウェアとして「IBM InfoSphere BigInsights」と「IBM InfoSphere Streams」を発表した。膨大なデータを高速に分析するために、従来とは異なるアプローチを採っており、今後の発展が期待される先端分野での製品投入となる。
溜めるだけではない
ビッグデータへの取り組み
データ量の爆発的な増大に関しては、各社折に触れて指摘しているところだが、おもにはストレージの問題として、大量のデータをどう保存するか、という視点で語られることが多いように思う。しかし、一般企業にとってデータは「単に保存しておきさえすればよい」ものではなく、データマイニングやBI(Business Intelligence)といった形でデータの分析を行なってそこから有用な情報を抽出したり、何らかの新しい機能やサービスの実現につなげるなど、業務のために役立てることが重要となる。量的にあまりに膨大で、かつその生成頻度が高まっており、時々刻々と大量のデータが積み上がっていく状況でこのデータを適切にハンドリングし、分析するには従来のデータ解析技術だけでは対応しきれない。

日本IBM 理事 ソフトウェア事業 インフォメーション・マネージメント事業部長の俵 雄一氏
まず同社のビッグデータへの取り組みの概要を説明した同社の理事 ソフトウェア事業 インフォメーション・マネージメント事業部長の俵 雄一氏はデータ量の増大ペースに関するデータを紹介し、「全世界の総データ量は2009年には80万ペタバイト(PetaBytes)だったが、2020年には44倍の35ゼッタバイト(ZettaBytes)に増大すると予測されており、しかもその80%は非構造化データだ」と指摘した。BIなどの従来のデータ分析手法はデータベースに格納された構造化データをおもな対象としていることもあり、大容量データの分析には従来の分析システムを単純に量的に拡大するだけでは対応できないことは明らかだ。

データ量の爆発的増大
同氏は、ビッグデータの特性として、Variety(多様性)、Velocity(頻度)、Volume(量)の“3つのV”を挙げた。構造化データ/非構造化データ、画像や音声、動画や各種のセンサーからの出力など、さまざまな形式のデータが時々刻々と膨大な量で生成され続ける、というのがビッグデータだということになる。

ビッグデータの3つの特性
このビッグデータの取り扱いに特化したソフトウェアが、今回発表された「IBM InfoSphere BigInsights」および「同Streams」だ。なお、同社ではビッグデータへの対応を特殊分野におけるポイント・ソリューションという位置づけではなく、企業向けの“情報サプライチェーンを支えるInformation Management製品群”の1つと捉え、既存の製品体系の中に位置づけており、相互連携を意識している点も同社の取り組みの特徴といえるだろう。
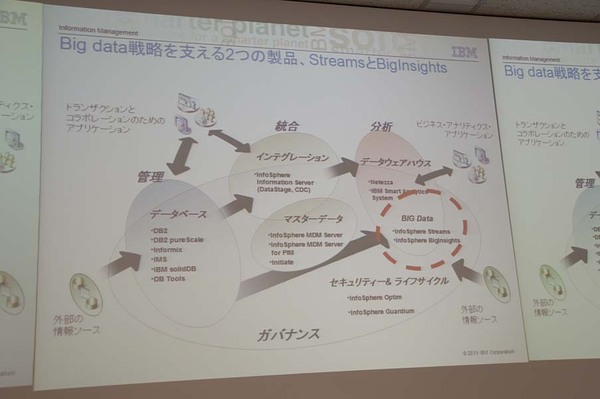
Information Management製品群全体の中での位置づけ
Hadoopに独自の機能を追加
「IBM InfoSphere BigInsights Enterprise Edition V1.1」は、オープンソースのHadoopをベースに同社独自の機能を追加したもので、大量のデータを迅速に分析するためのプラットフォームとなる。機能および対応データ量に制限はあるものの無償で利用できる「IBM InfoSphere BigInsights Basic Edition」も提供される。Enterprise Edition V1.1の価格はデータ量ベースで決定され、1TB当たり285万円から。Basic Editionでは一部機能が限定されるが、データ量は10TBまで対応し、無償で利用できる。
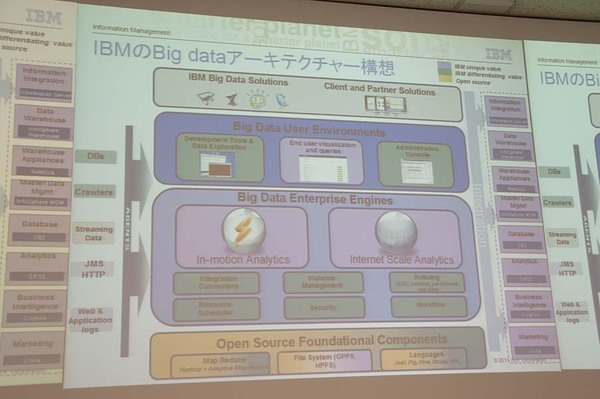
BigInsightsのアーキテクチャー

HadoopをベースにしたBigInsights Enterprise Edition V1.1
「IBM InfoSphere Streams V2.0」は、データをデータベース等に蓄積してから分析を行なうという従来の手法ではなく、CEP(Complex Event Processing:複合イベント処理)と呼ばれる手法で流れてくるデータを逐次分析していくことに対応するソフトウェアとなる。最初のバージョンは2009年にリリースされているが、今回は並列アルゴリズムの改善などで従来比3.5倍の分析速度を実現しているという。価格はプロセッサ単位で、1コア当たり464万円から。

IBM InfoSphere Streams V2.0の概要
イタリアのスマートグリッド事例も紹介
さらに、俵氏はこうしたビッグデータ活用事例として、米IBMの「WATSON(ワトソン)」と伊ENEL社の事例を紹介した。
WATSONは米国で「クイズ王に挑戦」し、勝利を収めたことで話題になったシステムだ。百科事典的に大量のデータを蓄積し、迅速に検索するのはそもそもコンピュータの得意とするところだが、幅広い設問に対応できるだけの膨大なデータを蓄積し、かつクイズ王に勝てるだけの速さで答えを導き出すという処理はまさにビッグデータ分析そのものだ。
また、イタリアの電力会社であるENEL社は、いわゆるスマートグリッドにつながるシステムの構築事例だ。契約家庭約2800万世帯にスマートメーターを配布し、電力使用量を15分ごとに送信することで、昼夜など時間帯ごとに異なる料金体系を適用できるようになったという。従来の電気料金が月1回の検針による積算利用量に基づく単純な体系だったのに対し、需給が逼迫する時間帯は高く、余裕のある時間帯は安く、といった弾力的な料金設定を可能にしている。これは、ビッグデータの活用によって従来は実現できなかった新しいサービスが実現できた例といえるだろう。ENEL社のシステムは今回のソフトウェアのリリース前に構築されたものであり、今回のソフトウェアが利用されているわけではないそうだが、15分ごとに送信されてくるデータの処理にはCEP的なアプローチが使われているだろうことは容易に想像できる。
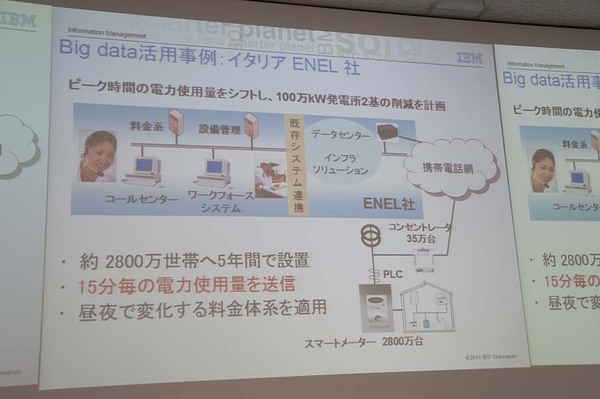
ENELでのスマートグリッド事例
BigInsights/Streamsいずれも、買ってくれば即使えるというものではなく、カスタムシステムの構築のための素材といった位置づけになる製品であり、当面のユーザーは限られると思われるが、さまざまな業種業態での活用への取り組みが始まっているといい、今後の発展が期待できる分野であろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



