




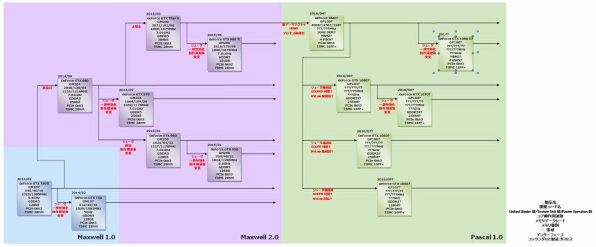
2014年~2016年のNVIDIA GPUロードマップ
GP100のダイサイズは
450mm2が妥当
GTCのタイミングで公開されるGP100が、Tesla向けのモジュールのままなのか、それともPCI Expressカードの形になっているものなのかは不明だが、仮にPCI Expressカードの形になっていたとしても、GeForce GTX Titan(もしくは別ブランド)としてビデオカードとしてリリースできるほどの余力がNVIDIAにあるかどうかは怪しいところだ。理由はダイサイズである。
真偽は不明だが、GP100は4096シェーダー構成でトランジスタ数は170億個に達するというもっぱらの評判である。シェーダー数はGM200の1.3倍ほどの数になるが、GM200はFP64(倍精度浮動小数点演算)能力を省き、その分高密度化・高効率化を図ったダイである。
一方GP100はFP64とFP16(半精度浮動小数点演算)のサポートも追加されているので、比較するとするとGP100よりはその前世代の、やはりFP64をサポートしたGK110と比較したほうが妥当な気がする。
GK110は28nmプロセスを利用し2880シェーダーで70.8億トランジスタ、561mm2のダイサイズとなる。ダイサイズがおおむねシェーダー数に比例して増減すると仮定すると、28nmのままPK100を製造すると798mm2もの巨大なダイになる。
ただしプロセスを16FF+に移行することでおおむね密度が倍になるので、ほぼ400mm2といったところだ。実際にはもう少し大きく、450mm2くらいになると思われる。
2015 Taiwan GTCのスライドをAMDのFijiと比較すると、やや小さいくらいかな? という感じで、ぎりぎり500mm2を切るあたりになるのではないかと予想する。

GTC 2015で、Pascal搭載モジュールを手にするNVIDIAのジェン・スン・ファンCEO。このスライドから察するに、ダイサイズは500平方mmを切ると思われる
いかなTSMCといえども、立ち上がったばかりの16FF+のラインでこれだけ大きなダイを作ると、歩留まりがそうあがらないだろうと思われる。
おまけにSummit/Sierra向けや、その他のスーパーコンピューター(Pascal/Voltaを使うスパコンはSummit/Sierraだけではない)向けの需要を満たすのが最優先であることを考えると、実際にはデスクトップ向けにPascalがリリースされるのが2017年にずれ込んでも不思議ではない。
そこで、一応ロードマップには4月にTitanグレードの製品、2017年にそのダウングレード版をおいてあるが、実際にはTitanグレードが2016年末~2017年、ダウングレード版が2017年6月になっても不思議ではない。
GeForce GTX 1080を
6月のCOMPUTEX前後に発表
では実際にデスクトップ向けとして最初にリリースされる製品はというと、もう少しシェーダー数を削減したGP104コアになると思われる。
登場時期はCOMPUTEX前後で、まだGeForce GTXというシリーズ名を維持するとすればGeForce GTX 1080あたりになり、同時にそのダウングレード版のGeForce GTX 1070あたりがリリースされるだろう。
このGP104コアは、おそらくGeForce GTX 980 Tiと同程度あたりかやや多い程度にシェーダー数を削減するほか、FP64のサポートを抜くなどのダイサイズ削減の可能性もある。
またGP100はNVLinkを複数本サポートすると思われるが、この数が若干減ると思われる。もう1つ大きな違いは、HBM2ではなくGDDR5Xを利用することだ。
HBM2は1024bit幅で1GHz/DDR(つまり2GHz相当)のデータ転送をすることで1スタックあたり256GB/秒の帯域を持つ。GP100はこれを4つ搭載することで合計1TB/秒の帯域となるわけだが、HBM2は相対的に高コストになる。
これに対抗すべく、Micronなどが提唱し、2015年11月にはJESD232としてJEDEC標準化もなされたのがGDDR5Xである。簡単に言えば、既存のGDDR5チップ2つをインターリーブ動作させるような構造であり、これによりメモリーチップそのものは既存のものと同じ技術で倍の速度を出せる。
ただし現在のGDDR5が8n Prefetch×2という構成なのに対し、GDDR5Xは16n Prefetch×2という構成になるため、GPUコアは1回のメモリーアクセスで従来の倍(32Bytes→64Bytes)のデータがやってくることを前提にしないと性能が出ない。
一応GDDR5Xチップは従来と同じDDRモードを使うとGDDR5として動作し、QDRモードを使うとGDDR5Xとして動作することで互換性を保っているが、さすがにこれをGDDR5として使うケースはあまりないと思われる。
JESD232によればGDDR5XはDDRモードで6Gbps、QDRモードで12Gbpsまで対応ということになっているが、MicronのDRAM Component Part Numbering Systemを見ると、すでにGDDR5Xで10/12/14Gbpsの製品がラインナップされている。
どうもこのGP104は、HBMではなくGDDR5を使うことになりそうだ。理由は価格が安いからと言うことと、メモリー構成の変更がやりやすいことからである。
HBM2の場合、スタックの数を減らすか、もしくはスタックのメモリー量を変更することになるが、HBM2がGPUと同じパッケージに搭載されているから、メモリ変更=搭載されるGPUチップそのものの変更になる。
対してGDDR5XはGDDR5同様にx16とx32の構成をサポートしているので、例えば基板表面のみ実装だと4GB、両面実装だと8GBといった変更が簡単に行なえる。
もっとも消費電力的にGDDR5Xが優秀か? というとやや疑問が残る部分でもあり、またHBM2が当初のSK Hynixに加えSamsungも量産を開始したことを考えると、どこまでGDDR5XとHBM2の間に価格差があるかもやや怪しいところではある。
この下のグレードがGP106とGP107で、どちらもGP104の構成をさらにグレードダウンしたものになる。メモリーについてもおそらくGDDR5XのサポートはGP104のみでGP106/107はGDDR5のみとなろうし、NVLinkもGP107からは省かれるかもしれない。
これらの製品はGP104よりもう少し遅く、今年第3四半期~第4四半期にかかるかもしれない。
これ以外に、GM108のアップデートとなるGP108も用意されているらしいが、こちらは引き続きモバイル向けのみということでデスクトップ向けにリリースされる計画はいまのところないようだ。
Voltaが2017年に登場するかは
TSMC次第
最後にVoltaであるが、こちらはPascal比で2倍の性能/消費電力比を実現できるとする。ただその主なものはアーキテクチャーではなくプロセスの方で、要するにTSMCの10FF頼みとなる。
なのでVoltaが2017年中にリリースでき、無事にSummit/Sierraに納入できるかはTSMC次第になる。逆に言えば、それが間に合わなかった場合は、とりあえずPascalで凌ぐしかないわけで、それもあってGP100は当面はTesla向け専用になりそうな気配が濃厚である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















