




パッチから推定できるZenの内部構造
ここまでの情報を元にWaldhauer氏が作成したZenの内部構造推定図がこちらである。基本これは大きく外れてはいないと思うのだが、いくつか考慮すべきポイントが残されていると筆者は考えており(この件でもWaldhauer氏とメールで議論した)、これを反映させた筆者の推定図が下の画像である。
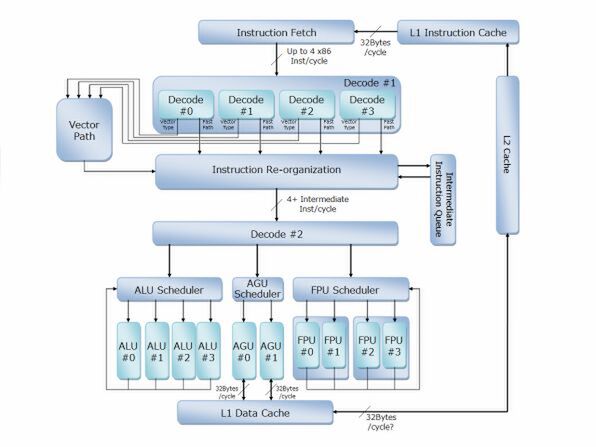
筆者が推定するZenの内部構造図
さて、まずFetchはおそらく32バイト/サイクルで1次キャッシュから命令を取り込むと予想される。
実際のところ、本当にフルにx86を4命令/サイクルで処理しようとすると32バイト/サイクルでも足りない可能性はあるのだが、だからといって倍の64バイト/サイクルに帯域を増やすと間違いなく消費電力の観点で破綻しかねない。
インテルはNehalemの世代で4命令/サイクルのデコーダーと32バイト/サイクルの帯域でうまく性能をマッチさせているから、現実問題として32バイト/サイクルがあれば十分と判断したのだろう。
ここからFetchを経てDecode #1に入る。実際はこの手前にEarly Decode、あるいはPickと呼ばれる処理が入るかもしれない。
これは命令ストリームを解釈して、命令の切れ目にフラグを立てることでデコードをしやすくする処理であるが、大きく見ればFetchの一部ということでまとめてある。
Decode #1は、x86命令をおそらく中間言語に変換する処理になると筆者は予想する。ここでは先に説明した通り4つのデコードが同時に動き、Fast Pathの命令はそのまま変換してInstruction Re-organizationへ、Vector TypeはそこからVector Pathに命令を送り出してこちらで処理する形になるであろう。
では次のInstruction Re-organizationとはなにか? であるが、実はAMDはK8/K10の時代にこれに近いものを実装していた。
下の画像はMicroProcessor Forum 2001におけるK8のアーキテクチャー図であるが、Pickの後で2段のデコードを経て、一度“Pack”と呼ばれる段階を経てもう一度デコードしているのがわかる。
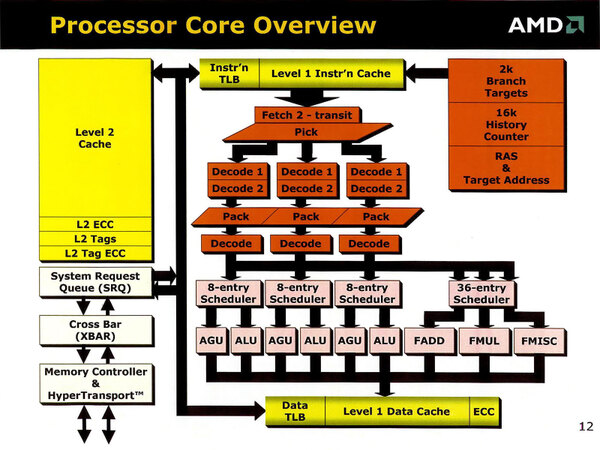
2001年10月のMicroProcessor Forumで、当時のCTOだったFred Weber氏が公開したK8の内部構造。この写真はこの講演の後で行なわれたAMDとのラウンドテーブルの際にもらったスライドのコピーである
これは、まずx86命令を一度分解し、この中で一緒に実行できる命令を組み合わせて(これがPackのステージ)、それからいわゆるmicroOpに変換するという仕組みだ。
要するにInstruction Fusion(インテルではMacroOps FusionおよびMicro Ops Fusionと呼んでいるもの)の処理を行なっていたと想像される。
筆者はZenにもこれに似た構造が盛り込まれていると考えている。ただしその理由はやや異なる。Waldhauer氏はK12コアとZenコアがかなりの部分共通と考えている(関連リンク)。
筆者もその考えには賛成であるが、ということはスケジューラーから下はK12と共通になるという意味である。この場合両者の違い、つまりx86/x64とAArch32/AArch64の差をデコード段だけで吸収して直接microOpを生成する、というのはやや処理的に重いように思われる。
むしろデコード段ではx86/x64やAArch32/AArch64を、比較的処理のしやすい中間命令に変換し、その後にその中間命令を実行に適したmicroOpに変換する、という2段構えの方が実装しやすいように思える。
また、Instruction Fusionを行なうためには、一度デコードの結果を付き合わせる必要があり、その場合にもいきなりmicroOpを生成しないほうが効果的である。これはK8/K10と同じである。
ただし、必ずしもx86/x64命令のすべてがうまく中間命令→microOpの形で変換できるとは限らない。これはAArch32/AArch64の場合も同じだが、2種類のまったく違う命令形態なので、完全に1つのmicroOpに変換するのは難しいと考えるのが普通だ。
こうした場合の例外処理が、先に出てきたVector Typeと思われる。Vector Typeを通る命令の場合、整数演算ならALU 0/1/2/3とAGU 0/1が必ず同期する(この6つの実行ユニットすべてを専有して処理される)し、浮動小数点演算ならFPU 0/1/2/3とAGPU 0/1が同期することになる。
これまでこうした処理の仕方は見たことがなかった。逆に言えば、こんな処理の仕方を導入すること自体が、K12とZenでかなりの部分を共通化していることの傍証になるのではないかと思う。
もう1つ理由を挙げると、昨今のプロセッサーはいずれもフロントエンド(Fetch→Decode)がIn-Order、バックエンド(Schedule→Execute→Retirement)がOut-of-orderの構成になっている。
この際に、両者の間に比較的大きなバッファを設けることで、動作を分離する手法が一般的である。例えばCortex-A7のようなローエンドのプロセッサーですら、デコーダーにInstruction Queueを設けることで、効率化を図っている。
インテルの場合、Nehalemで実装されていたLSD(Loop Stream Detector)がSandy Bridge以降ではDecoded microOps Cacheに進化してこれを実現しており、Zenにもないかしらこうしたバッファ機構が必要と思われる。
そう考えるとInstruction Re-organizationに付属する形で中間言語キャッシュが設けられているのではないか、と想像する。
さて、この後は再びデコード(今度は中間言語をmicroOpに変換)して、それぞれのスケジューラーに分配する形になる。
ちなみに本来ならこの前にReorder Bufferなども入るはずであるが、このあたりは実装の仕方次第ということでRoBの機能も含めてスケジューラーとしている。
このスケジューラーからそれぞれの実行ユニットに対して命令を発行するが、ALUが4つ独立で動作し、FPUも4つが独立して動作可能で、SSE系ならば2つで1組のSSEユニットを、AVXならば4つまとめて動作することになるだろう。これはK12の場合、FPUならば独立、NEONなら2つで1組という形で動作すると思われる。
→次のページヘ続く (Zenのクロックは3GHzと予想)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第872回
PC
NVIDIAのRubin UltraとKyber Rackの深層 プロトタイプから露見した設計刷新とNVLinkの物理的限界 -
第871回
PC
GTC 2026激震! 突如現れたGroq 3と消えたRubin CPX。NVIDIAの推論戦略を激変させたTSMCの逼迫とメモリー高騰 -
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 - この連載の一覧へ





















ディスプレーが3万円台! 超高解像度な3:2画面で仕事がはかどりまくること間違いなし")








の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")













