




今回のスーパーコンピューターの系譜は、GPUを使ったアクセラレーターの話である。GPUを使ったアクセラレーターといえば、まずNVIDIA、ついでAMD、最後にインテルあたりがぱっと思いつくと思う。
他にもARMやImagination Technologyも広義のアクセラレーターとしてはやはり名乗りを挙げているし、細かいところではVivante Corporationもこれに含まれるが、これらのベンダーは今のところモバイル向けSoC用のGPU/GPGPUを提供しており、HPCの枠からは外れるのでと除外すると、この3社が一番有名である。

CSX600
だが、GPUを使ったアクセラレーターとして一番最初に名乗りをあげたのはClearSpeed Technologyである。ClearSpeedのCSX600は、国内では東京工業大学のTSUBAME 1.0にも採用されたので、ご存知の方も多いかと思う。ただし「あれってGPUだっけ?」と思われる方もいると思うので、今回はこのClearSpeedの話をしよう。
幻のビデオカード
「FUZION 1」
ClearSpeed Technologyはイギリスに本拠を置くファブレス企業だが、その前身はPixelfusion plcという、やはりロンドンに本拠地を置くファブレスのグラフィックベンダーである。
1999年8月のHot Chips 11で同社は“Massively Par allel Comput ing on the FUZION Chip”という講演を行なっており、1999年にはFUZION 1という製品を発表することを明らかにしている。

FUZION 1を発表。1999年8月の講演にも関わらず、なぜかスライドの日付が10月2日になっているのは謎。この時点で17年ほど水面下で色々な開発を行なってきて、99年にやっと製品化にたどり着きそう、という話になっている
そのFUZION 1の内部構造が下の画像だ。“AGP/PCI Core Logic”や“Display Unit”、“Video I/O Unit”といった存在が辛うじてビデオカードらしいことを主張しているが、逆に言えばビデオカードらしい部分はこれだけで、肝心のFUZION CoreやLocal Memoryを見ると全然ビデオカードらしくない。
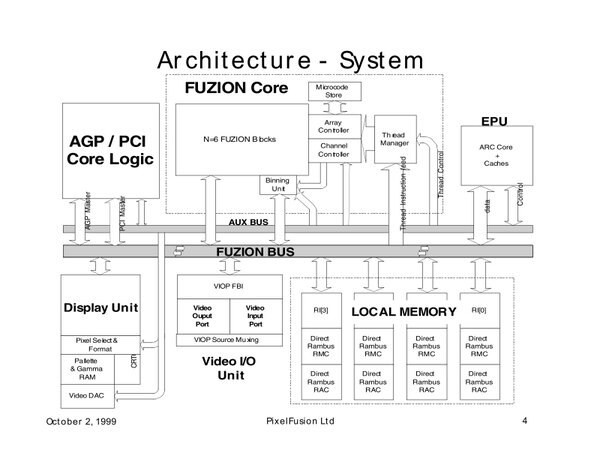
FUZION 1の内部構造。FUZION Coreが肝心の画像処理を行なうのだが、画像処理「しか」できないので、その他全般の処理は右端にあるARCコアが担うという、これもまた極端な構成。メモリーは4chのDirect RDRAMである
FUZION Coreの内部がこちらであるが、6つのFuzion Blockがそれぞれ256のPE(Processor Element)とLocal Memoryを持ち、この256個のPE毎に1つのLEE(Linear Expression Evaluator)を持つ、というおもしろい構造である。
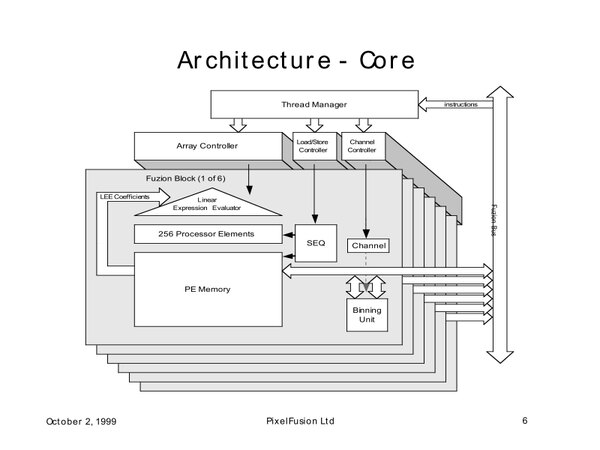
FUZION Coreの内部構造。PEの構造は後述する。正直なところ、LEEは汎用プロセッサーとしては意味があるが、グラフィック向けにこうした機構が必要なシーンがあまり理解できない。普通ならこれを固定機能で持つからだ
LEEの話は後にして先にPEの構造を下の画像に示す。各々のPEは8bitのALUで構成され、32個のLocal Registerを利用できる仕組みだ。
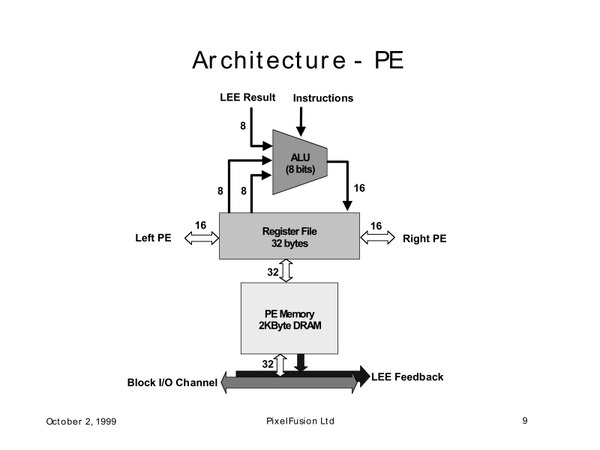
PE(Processor Element)の構造。このPEが256個ということで、Registerは合計で8KB、DRAMは512KBの構成となる
また各々のPEは2KBのメモリーを持つことができる。PE同士は相互に接続されており、連携して作業ができるようになっている。要するにFUZION 1は小規模ながらMPP(Massive Parallel Processing:超並列)の構造を持っているわけだ。
ではLEEはなにをやるかというと、より複雑な計算である。直線の補完やポリゴンの塗りつぶし、シェーディングやZ-Bufferingなど、複数の頂点にまたがる処理がLEEの作業範疇だとしている。

LEEの処理内容。理屈はともかく、この時点で市場から求められていた機能はこうしたものではない気がする
ちなみにこのFUZION 1は、0.25μmプロセスを利用してダイサイズは500mm2以上、消費電力は35W、7000万トランジスタという構成で、しかもeDRAMを使う関係でUMC/USICのみで製造できることになっていた。
性能(予測値)は以下のとおりで、演算性能こそ異様に高いが、肝心のグラフィック性能があまりたいしたことがない。
- 1.5T 8bit演算/秒(Multiply and Add)
- 600GB/秒 on chip DRAM Bandwidth
- 1.2TBytes/秒 PE bandwidth
- 3GFLOPS Processing(IEEE互換)
- 7GMACs(16bit×16bit)
- 150M 3D Transformations/秒
- 50M Triangles/秒
当初の予定ではテープアウトが1999年10月、最初のシリコンは1999年12月初頭、これを搭載した最初のボードの製造が2000年第1四半期、システム検証とOpenGL/Direct3D対応ドライバーの準備ができるのは2000年第2四半期、という勇ましいロードマップを立てていたが、これを搭載したボードが世の中に出ることはなかった。
1999年といえばNVIDIAがNV10ことGeForce 256をリリースした年であるが、そのNV10は0.22μmプロセスを使いトランジスタ数は1700万、ダイサイズは111mm2でしかなかった。
消費電力はわからなかったが、ファンは必須といいつつそう大きいものではなかったから、35Wよりはるかに少ないのは間違いない。
しかもNV10にはハードウェアT&Lを搭載していたが、FUZION 1にはその機能もない。FUZION 1そのものはコンシューマー向けというよりもワークステーション以上を指向した製品風だったため、必ずしもGeForceと競合はしないが、価格/性能比を考えたらどう考えても勝ち目はなかっただろう。
→次のページヘ続く (PixelFusionがプロセッサー製造ビジネスに転換)
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ

















の1台が今ならオトク!")




























")













