




WAN高速化で大きな効果を上げるキャッシュ
対向型のWAN高速化装置では、このキャッシュの能力がより顕著に現われる。WAN高速化装置で交換されるデータは、インターネット上にあるWebページやファイルではなく、データセンターや本社のサーバーにある業務データである。つまり、同じWAN回線を何度も行き来することが多いので、キャッシュのヒット率は高くなるわけだ。そこで、WAN高速化装置では、大容量のハードディスクやメモリを搭載し、リモートのデータを極力ローカルにキャッシュする。これにより、WAN上に流れるデータの量を減らせる。
バイト単位とオブジェクト単位
キャッシュは、オブジェクトとバイトの2種類に分かれます(図4)。オブジェクトキャッシングは、ファイルなどOS等で扱う比較的大きなデータ単位のキャッシングを指す。各拠点でユーザーに配布されるExcelファイルなどをキャッシングする場合などは、WAN経由でいちいち本社まで取得しにいかないので済むため、高い効果を得られる。その代わり、更新された場合は、最新のファイルをまるごと取得してくる必要がある。
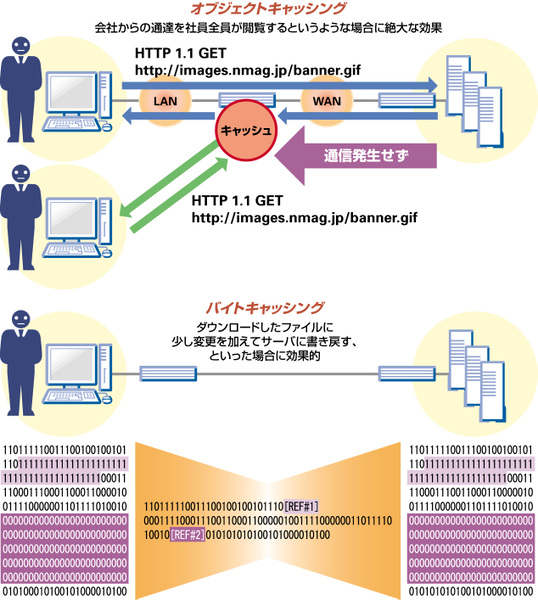
図4 オブジェクト単位とバイト単位の2つのキャッシング
バイトキャッシングは文字通り、流れるバイト列を単位としてキャッシングする方法だ。ファイルの一部が更新された場合などは、更新された部分のみを送受信すればよいので、WANに流れるデータは減る。また、単位がバイト列なので、効果はOSやアプリケーションに依存しない。その代わり、オブジェクトレベルに比べ、CPU負荷が高い。
ファイルの先読みやプッシュ配信
キャッシングの最大の弱点は、誰かが先んじてアクセスを行なうことでローカルにキャッシュを生成しなければ、その効果が発揮できないという点だ。そこで、ユーザーからのアクセスを待つのではなく、リモートにあるファイルをWAN高速化装置側から先読みする技術が用いられる。逆に、頻繁に利用するファイルを、あらかじめ各WAN高速化装置のキャッシュに配置しておくプッシュの機能もある。
辞書学習を用いる圧縮
キャッシングと共に、対向型で有効な技術として、圧縮が挙げられる。圧縮は、コンピュータで汎用的に用いられているデータの削減技術だ。データの冗長な部分を一定のアルゴリズムにしたがって、別の符号などに置き換え、送受信するデータ自体を削減する。一方、圧縮されたデータは、受信側で再度展開され、元のデータに復元されることになる。
通信データの圧縮に関しては、HTTP 1.1でも規定されているほか、ルータでは「IPcomp」と呼ばれる圧縮技術が実装されている。一方、WAN高速化装置では、流れるデータを一定のブロックやバイトレベルで別の符号に置き換え、その対応表を装置間で共有する「辞書圧縮」という方法が用いられる。たとえば、WAN高速化装置間ではABCDをA、EFGHをBに置き換えるといった辞書を作っておき、共有しておけば、データは1/4に削減できるというわけだ(図5)。
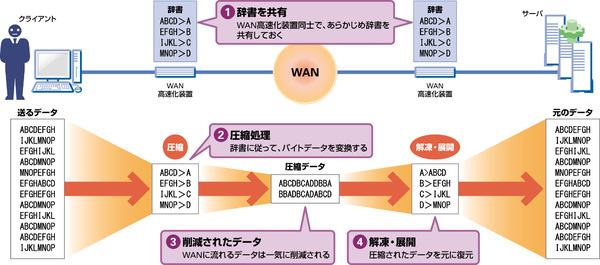
図5 辞書圧縮によるデータの削除
辞書は頻繁に利用するパターンをあらかじめ固定で登録しておく方法と、送受信されるデータのパターンを動的に学習する方法の2つがある。圧縮においては、重複するパターンをいかに効率よく辞書に登録するか、そして処理をいかに高速に行なえるようにするかが、圧縮効果を向上させる大きな鍵になる。
最終回となる次回は最新のロードバランサーやWAN高速化の技術や製品について、見ていきたい。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第5回
ネットワーク
WANの遅延を抑えて、レスポンスアップする -
第4回
ネットワーク
サーバーの処理を肩代わりする「オフロード」とは? -
第3回
ネットワーク
ますます高機能化するロードバランサーの技術 -
第2回
ネットワーク
知っておきたいロードバランサーの基礎技術 -
第1回
ネットワーク
アプリケーションを快適に使うためになにが必要? -
ネットワーク
アプリケーショントラフィック管理入門<目次> - この連載の一覧へ



