
Ryzenで初めて実装された
AMD独自のインターコネクト
ところでコアそのものとは関係ないが、もう一つRyzenを構成する重要な要素があるので、これも一緒にご紹介したいと思う。それは内部のインターコネクトにまつわる話である。
インターコネクトの重要性が最初に認識されたのは、AMD初のAPUであったLlanoの世代である。この時AMDは独自のAMD Fusion Compute Linkを開発して実装、続いてその後も世代毎に改良を加えながら独自Linkを利用し続けた。

Fusion Compute Linkの概要。この画像と次の画像が1枚のスライドになっているのだが、入りきらなかったので分割させていただいた

Naples絡みの話は次回解説する
理由はあって、当時のAPUで利用できるような適切なインターコネクトが存在しなかったからだ。ただその後Fusionの機能が上がり、部分的なキャッシュコヒーレンシーがだんだん取り込まれていくようになると、そのたびごとにその機能を追加したり、バスを分離したり、と結構複雑なことになっていた。
こうしたカスタマイズのコストを削減したい、というのがCTOだったPapermaster氏の強い願いであったという。
余談になるが、28nm世代ではGlobalfoundriesの28SHPという、事実上AMD専用のハイパフォーマンスプロセスを利用していたが、14nm世代ではバルクの14LPPを使っている。
これも同じことで、専用プロセスをわざわざ開発して利用するのはコストがかかりすぎるので、汎用プロセスを使ってコストを削減したいという強い欲求があったのだそうだ。
実際専用プロセスの場合、まずファウンダリーにそのプロセスを開発してもらうためのコストがかかるし、EDAツールもそのプロセスの特徴にあわせたスペシャル版が必要になる。
そうした追加コストを誰が被るか、というのはどれだけそのプロセスが他にも転用できるかで変わってくるが、いずれにせよAMDがコスト0で利用できるという話には絶対にならない。
おまけにGlobalfoundriesの28SHPは立ち上げにやや苦労した関係で製品投入まで遅れることになったため、その繰り返しは絶対に避けたかったのだろう。
そうしたことから、SoC内部のインターコネクトも、汎用のものを共通で使うという方針が定められ、これを最初に実装したのがRyzen、次いでVEGA/Naplesということになり、その後に出てくるRyzen Mobileもこれを継承するという。このインターコネクトの名前が、Infinity Fabricである。

AMD独自のインターコネクト「Infinity Fabric」。スライドによっては「∞Fabric」と書かれている場合もあった
これはあくまでもAMD独自のインターコネクトで、SoC内部のモジュール間や、MCM(Multi-Chip Module)のチップ間、さらには1枚のボード上の複数チップの間の接続にも利用可能と説明されている。
逆に言えばボードの外(Papermaster氏の表現では“Out of box”)に使うことは考えていないという。AMDはこうしたOut of boxの接続には業界標準規格を使うつもりで、そうした標準規格がおよばない内部の接続のみに、このInfinity Fabricを利用するとしている。
とはいえ、AMDの独自インターコネクトなのであまり意味のある説明はないのだが、大きくScalable Control FabricとScalable Data Fabricの2つから構成されることがわかっている。

Scalable Control Fabric。実体としてはコントローラーにあたるものが存在するのだとは思うが、それ自身もスケーラビリティーがあるらしい
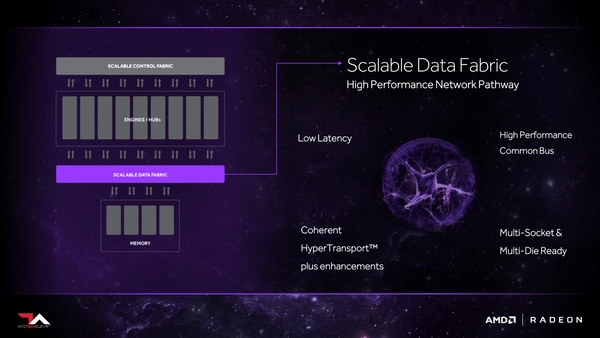
Scalable Data Fabric。メディア非依存で、既存のバスの上に通すこともできるらしい。意味があるかどうかはともかく、それこそUSBでもPCIeでも10GbEでも可能ということになる
おもしろいのは上のScalable Data Fabricの画像で、HyperTransportの名前が出てくることだが、Papermaster氏曰く、HyperTransportのアイディアを拡張したという話であって、物理的にHyperTransport Linkとの互換性はないし、サポートするわけではないそうだ。
この話が重要なのは、現在のRyzen 7/5自身もおそらくInfinity Fabricを利用していると思われるのだが、それよりもVegaとRyzen Mobileのことだ。
現在のAPUの後継はRyzen Mobileになるわけだが、ここに集約されるGPUコアはPolarisではなくVegaであることがはっきりしたためだ。理由は簡単で、PolarisはInfinity Fabricに対応していない。これはPapermaster氏に確認して、明確にそうだという返事を得ているからである。
つまりPolarisは本当に過渡期の製品になりそうなことがこれでわかった。過去の例で言うならば、VLIW4構造を採用したCaymanコアのRadeon HD 6900シリーズなどがやはり短命であるが、それでもVLIW4アーキテクチャー、は一応Trinity/Richlandという第2世代APUにも採用されたことを考えると、Polarisはもっと不遇ということになりそうなのは少し残念である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 - この連載の一覧へ












