
ソケットの使い方そのものはシンプルです。 繋いでしまったら、書き出し、読み込み、クローズしかありません。 APIリファレンスを読めれば、とりあえず使うことはできるでしょう。
ですが、ソケットまわりのパフォーマンスはユーザの体感に直結します。通信が切れる、タイムアウトなどのエラーが発生する可能性も多々あります。 最大の効率を得るには、ボトルネックを中心に最適化を行うしかありません(これは『ザ・ゴール』というビジネス書で「制約理論」として示されている問題でもあります)。
今回は、前回に引き続き、HTTPの機能を再現しながらソケットの使い方について学んでいきます。 HTTPの歴史を通して、ソケットの実行効率を向上させる方法を具体的に見ていきましょう。
圧縮
HTTPの速度アップ手法としてよく使われているのが圧縮です。 昔よりもインターネットやWifiの性能は向上しましたが、それでもCPUを使って圧縮することにより通信量を減らすほうが、まだメリットが大きい場合が多々あります。 前回の記事で作ったHTTPサーバとクライアントに、一般的なブラウザでも使われているgzip圧縮を実装してみましょう1。
圧縮をしてもパケット伝達の速度は変わりませんが、転送を開始してから終了するまでの時間は短くなります。
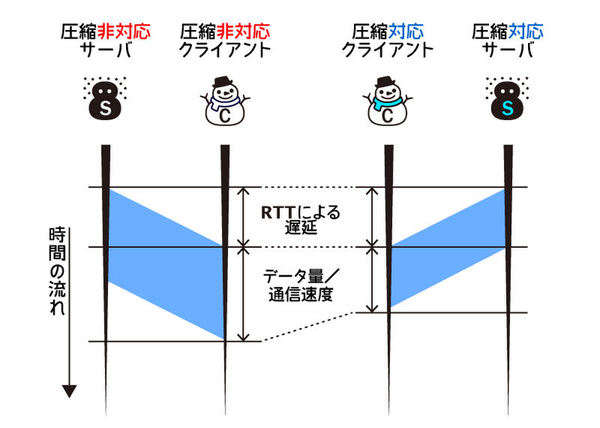
gzip圧縮については、第2回のio.Writerのフィルタの項目で紹介しました。 第2回では、ファイルシステム上で展開できる圧縮ファイルを作成しましたが、今回はバイト列をgzip圧縮します。 そのため、第2回のときのようにヘッダーでファイル名を指定する必要はありません。
gzip圧縮に対応したクライアント
前回のKeep-Alive版のコードをベースにクライアントを改造していきます。 変更する箇所は3つです。
まず、importに"compress/gzip"と"io"、"os"を追加します。
次に、リクエスト生成部を改造して、自分が対応しているアルゴリズムを宣言するようにします。 サーバから自分が理解できない圧縮フォーマットでデータを送りつけられても、クライアントではそれを読み込めないからです。 下記のように、リクエストヘッダの"Accept-Encoding"に「このクライアントはgzip圧縮を処理できます」という表明を入れます。
request, err := http.NewRequest(
"POST",
"http://localhost:8888",
strings.NewReader(sendMessages[current]))
if err != nil {
panic(err)
}
request.Header.Set("Accept-Encoding", "gzip")3つめの変更箇所は、レスポンスを受け取る部分です。 希望した方式でサーバがデータを圧縮してきたかを確認し、圧縮されている場合は復元するようにします。
dump, err := httputil.DumpResponse(response, false)
if err != nil {
panic(err)
}
fmt.Println(string(dump))
defer response.Body.Close()
if response.Header.Get("Content-Encoding") == "gzip" {
reader, err := gzip.NewReader(response.Body)
if err != nil {
panic(err)
}
io.Copy(os.Stdout, reader)
reader.Close()
} else {
io.Copy(os.Stdout, response.Body)
}httputil.DumpResponse()は圧縮された内容を理解してくれないため、2番目のパラメータにfalseを設定してボディを無視するように指示しています。
Accept-Encodingで表明した圧縮メソッドにサーバが対応していたかどうかは、Content-Encodingヘッダーを見ればわかります。 表明したアルゴリズムに対応していれば、そのアルゴリズム名がそのまま返ってきます。 今回は1種類だけですが、複数の候補を提示してサーバに選ばせることもできます。 実際、HTTPには、1応答の間に最適なアルゴリズムのネゴシエーションを行う仕組みが備わっています。
gzip圧縮されていたら、gzip.NewReader()を使って展開し、それをコンソールに書き出します。 これはio.Readerインタフェースを満たす構造体であればなんでも入力にできます。 第3回、第4回で紹介したio.Readerの仲間です。
GZIP圧縮に対応したサーバ
次はサーバ側のコードを見てみましょう。 前回は全部1つの関数内で処理していましたが、1セッションの通信をprocessSession()関数に切り出しています。
package main
import (
"bufio"
"bytes"
"compress/gzip"
"fmt"
"io"
"io/ioutil"
"net"
"net/http"
"net/http/httputil"
"strings"
"time"
)
// クライアントはgzipを受け入れ可能か?
func isGZipAcceptable(request *http.Request) bool {
return strings.Index(strings.Join(request.Header["Accept-Encoding"], ","),
"gzip") != -1
}
// 1セッションの処理をする
func processSession(conn net.Conn) {
fmt.Printf("Accept %v\n", conn.RemoteAddr())
defer conn.Close()
for {
conn.SetReadDeadline(time.Now().Add(5 * time.Second))
// リクエストを読み込む
request, err := http.ReadRequest(bufio.NewReader(conn))
if err != nil {
neterr, ok := err.(net.Error)
if ok && neterr.Timeout() {
fmt.Println("Timeout")
break
} else if err == io.EOF {
break
}
panic(err)
}
dump, err := httputil.DumpRequest(request, true)
if err != nil {
panic(err)
}
fmt.Println(string(dump))
// レスポンスを書き込む
response := http.Response{
StatusCode: 200,
ProtoMajor: 1,
ProtoMinor: 1,
Header: make(http.Header),
}
if isGZipAcceptable(request) {
content := "Hello World (gzipped)\n"
// コンテンツをgzip化して転送
var buffer bytes.Buffer
writer := gzip.NewWriter(&buffer)
io.WriteString(writer, content)
writer.Close()
response.Body = ioutil.NopCloser(&buffer)
response.ContentLength = int64(buffer.Len())
response.Header.Set("Content-Encoding", "gzip")
} else {
content := "Hello World\n"
response.Body = ioutil.NopCloser
(strings.NewReader(content))
response.ContentLength = int64(len(content))
}
response.Write(conn)
}
}
func main() {
listener, err := net.Listen("tcp", "localhost:8888")
if err != nil {
panic(err)
}
fmt.Println("Server is running at localhost:8888")
for {
conn, err := listener.Accept()
if err != nil {
panic(err)
}
go processSession(conn)
}
}少々長いですが、重要なポイントはレスポンスを作成している部分です。 前回のコードでは、コンテンツとそのサイズを、すべてhttp.Responseに入れていました。 今回は、クライアントがgzipが受け入れ可能かどうかに応じて、中に入れるコンテンツを変えています。
圧縮にはgzip.NewWriterで作成したio.Writerを使います。 圧縮した内容はbytes.Bufferに書き出しています。 さらにContent-Lengthヘッダーに圧縮後のボディサイズを指定します。
このコードを見て分かる通り、ヘッダーは圧縮されません。 そのため、少量のデータを通信するほど効率が悪くなります。 20バイト足らずのサンプルの文字列ではgzipのオーバーヘッドの方が大きく、サイズが倍増してしまっていますが、大きいサイズになれば効果が出てきます。 ヘッダーの圧縮はHTTP/2になって初めて導入されました。
なお、HTTPで圧縮されるのはレスポンスのボディだけで、リクエストのボディの圧縮はありません。
チャンク形式のボディ送信
これまで紹介してきた通信処理は、一度のリクエストに対して、必要な情報をすべて一回で送るというものでした。 そのため、全部のデータが用意できるまでレスポンスのスタートが遅れます。結果として最終的な終了時間も伸び、実行効率は下がります。
この方法には、巨大なファイル(Linuxディストリビューションなど)をクライアントに返すときに全体がメモリにロードされてしまい、それだけ多大なリソースが必要になるという問題もあります。 HTTPでは、チャンク形式のレスポンスをサポートすることで、これらの問題に対処しています。
チャンク形式ではヘッダーに送信データのサイズを書きません。 代わりに、Transfer-Encoding: chunkedというヘッダーを付与します。
ボディは、16進数のブロックのデータサイズの後ろに、そのバイト数分のデータブロックが続く、という形式です。 通信の完了は、サイズとして0を渡すことで伝えます。
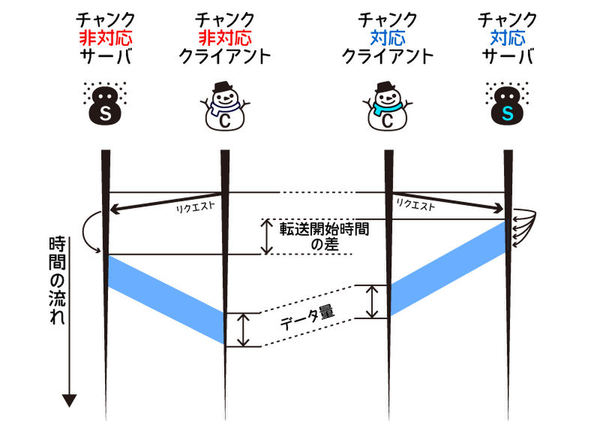
チャンク形式であれば、準備ができた部分からレスポンスを開始できるため、レスポンスの初動が早くなります。 特にファイルサイズが大きくなると効果が大きくなります。 ファイルから細切れに読み込んで少しずつソケットに流していければ、データ全体を保持するために大量のメモリを確保するというオーバーヘッドも減らせます。 ヘッダーにサイズを入れる必要もないので、最終的なデータのサイズが決まる前に送信を開始することもできます。
チャンク形式のサーバの実装
まずはチャンク形式でデータを送信するサーバの実装を見てください。「ごんぎつね」の文章を100バイトずつぐらいレスポンスとして返すサーバです。 import文まわりとmain()関数については、gzip圧縮版のサーバと同じコードなので省略します。
// 青空文庫: ごんぎつねより
// http://www.aozora.gr.jp/cards/000121/card628.html
var contents = []string{
"これは、私わたしが小さいときに、村の茂平もへいというおじいさんからきいたお話です。",
"むかしは、私たちの村のちかくの、中山なかやまというところに小さなお城があって、",
"中山さまというおとのさまが、おられたそうです。",
"その中山から、少しはなれた山の中に、「ごん狐ぎつね」という狐がいました。",
"ごんは、一人ひとりぼっちの小狐で、しだの一ぱいしげった森の中に穴をほって住んでいました。",
"そして、夜でも昼でも、あたりの村へ出てきて、いたずらばかりしました。",
}
func processSession(conn net.Conn) {
fmt.Printf("Accept %v\n", conn.RemoteAddr())
defer conn.Close()
for {
// リクエストを読み込む
request, err := http.ReadRequest(bufio.NewReader(conn))
if err != nil {
if err == io.EOF {
break
}
panic(err)
}
dump, err := httputil.DumpRequest(request, true)
if err != nil {
panic(err)
}
fmt.Println(string(dump))
// レスポンスを書き込む
fmt.Fprintf(conn, strings.Join([]string{
"HTTP/1.1 200 OK",
"Content-Type: text/plain",
"Transfer-Encoding: chunked",
"", "",
}, "\r\n"))
for _, content := range contents {
bytes := []byte(content)
fmt.Fprintf(conn, "%x\r\n%s\r\n", len(bytes), content)
}
fmt.Fprintf(conn, "0\r\n\r\n")
}
}http.Responseは、ファイルサイズ指定がないとConnection: closeを送ってしまうため、ここではfmt.FprintfでHTTPレスポンスを直接書き込んでいます。レスポンスボディは次のような形式になっています。
75
これは、私わたしが小さいときに、村の茂平もへいというおじいさんからきいたお話です。
45
中山さまというおとのさまが、おられたそうです。
:
075とありますが、16進数なので実際のバイト数は117です。 サイズ、本文の末尾は\r\nで区切られています。
このサーバはHTTP標準なので、たとえばcurlコマンドでアクセスすることもできます。
チャンク形式のクライアントの実装
クライアント側も実装してみましょう。 やはり前回のクライアント実装をベースにしますが、Keep-Alive版のクライアントは実験のためにループでわざと三回送信するようにしていたので、そのループは省いてあります。
package main
import (
"bufio"
"fmt"
"io"
"net"
"net/http"
"net/http/httputil"
"strconv"
)
func main() {
conn, err := net.Dial("tcp", "localhost:8888")
if err != nil {
panic(err)
}
request, err := http.NewRequest(
"GET",
"http://localhost:8888",
nil)
if err != nil {
panic(err)
}
err = request.Write(conn)
if err != nil {
panic(err)
}
reader := bufio.NewReader(conn)
response, err := http.ReadResponse(reader, request)
if err != nil {
panic(err)
}
dump, err := httputil.DumpResponse(response, false)
if err != nil {
panic(err)
}
fmt.Println(string(dump))
if len(response.TransferEncoding) < 1 ||
response.TransferEncoding[0] != "chunked" {
panic("wrong transfer encoding")
}
for {
// サイズを取得
sizeStr, err := reader.ReadBytes('\n')
if err == io.EOF {
break
}
// 16進数のサイズをパース。サイズがゼロならクローズ
size, err := strconv.ParseInt(
string(sizeStr[:len(sizeStr)-2]), 16, 64)
if size == 0 {
break
}
if err != nil {
panic(err)
}
// サイズ数分バッファを確保して読み込み
line := make([]byte, int(size))
reader.Read(line)
reader.Discard(2)
fmt.Printf(" %d bytes: %s\n", size, string(line))
}
}ヘッダーを受信するところまではgzip対応クライアントと同じです。 その後はforループでチャンクごとに読み込んでいます。 その際のテキスト解析には、第4回で紹介したbufio.Readerが活躍します。 「改行を探し、サイズを取得したら、そのサイズの分だけ読み込む」という処理を末尾まで繰り返しています。
パイプライニング
HTTP通信を効率化する手法として、圧縮により通信量を削減する手法と、リクエストごとのレスポンスの初動をチャンク送信で高速化する手法を、ソケットを使って実装してみました。 最後に紹介するのは、送受信を非同期化することでトータルの通信にかかる時間を大幅に減らす方法です。
この機能はパイプライニングと呼ばれ、HTTP/1.1の規格にも含まれています。 パイプライニングでは、レスポンスがくる前に次から次にリクエストを多重で飛ばすことで、最終的に通信が完了するまでの時間を短くします。
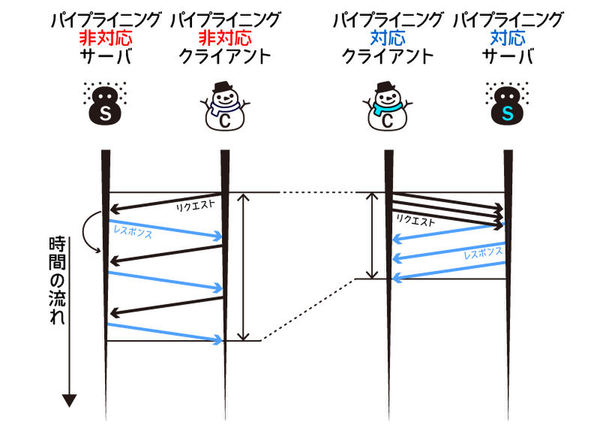
残念ながら、パイプライニングはHTTPの歴史におけるもっとも不幸な機能でした。 規格には入りましたが、後方互換性がない機能であるため、HTTP/1.0しか解釈できないプロキシが途中にあると通信が完了しなくなるという問題があったのです。 サーバの実装が不十分な場合もありました。
ブラウザ側の対応も十分とはいえませんでした。 Netscape Navigatorでは、サーバが自称するX-Powered-Byヘッダーを見てパイプライニングを使うかどうかを決める条件分岐ロジックが組まれていました。 Chromeブラウザでは、いったん実装されたものの、後で削除されました。 Safariでも、画像が入れ替わるバグを誘発するという問題がありました。 サポートされているブラウザにしても、何度か通信してサーバの対応を確認してから有効化するような実装になっています。
完全に仕様を満たすものを作るのは大変ですが、ここではソケットを使ってHTTPパイプライニングの簡易実装に挑戦してみましょう。
パイプライニングのサーバ実装
まずはサーバ実装を見ていきましょう。 サーバを実装するうえで注意すべきパイプライニングの仕様は次の2点です。
- サーバ側の状態を変更しない(安全な)メソッド(GETやHEAD)であれば、サーバ側で並列処理を行ってよい
- リクエストの順序でレスポンスを返さなければならない
Keep-Alive対応版のサーバをパイプライニング対応版に改修したものを下記に示します。 import文まわりとmain()は省略してあります。
// 順番に従ってconnに書き出しをする(goroutineで実行される)
func writeToConn(sessionResponses chan chan *http.Response, conn net.Conn) {
defer conn.Close()
// 順番に取り出す
for sessionResponse := range sessionResponses {
// 選択された仕事が終わるまで待つ
response := <-sessionResponse
response.Write(conn)
close(sessionResponse)
}
}
// セッション内のリクエストを処理する
func handleRequest(request *http.Request,
resultReceiver chan *http.Response) {
dump, err := httputil.DumpRequest(request, true)
if err != nil {
panic(err)
}
fmt.Println(string(dump))
content := "Hello World\n"
// レスポンスを書き込む
// セッションを維持するためにKeep-Aliveでないといけない
response := &http.Response{
StatusCode: 200,
ProtoMajor: 1,
ProtoMinor: 1,
ContentLength: int64(len(content)),
Body: ioutil.NopCloser(strings.NewReader(content)),
}
// 処理が終わったらチャネルに書き込み、
// ブロックされていたwriteToConnの処理を再始動する
resultReceiver <- response
}
// セッション1つを処理
func processSession(conn net.Conn) {
fmt.Printf("Accept %v\n", conn.RemoteAddr())
// セッション内のリクエストを順に処理するためのチャネル
sessionResponses := make(chan chan *http.Response, 50)
defer close(sessionResponses)
// レスポンスを直列化してソケットに書き出す専用のゴルーチン
go writeToConn(sessionResponses, conn)
reader := bufio.NewReader(conn)
for {
// レスポンスを受け取ってセッションのキューに
// 入れる
conn.SetReadDeadline(time.Now().Add(5 * time.Second))
// リクエストを読み込む
request, err := http.ReadRequest(reader)
if err != nil {
neterr, ok := err.(net.Error)
if ok && neterr.Timeout() {
fmt.Println("Timeout")
break
} else if err == io.EOF {
break
}
panic(err)
}
sessionResponse := make(chan *http.Response)
sessionResponses <- sessionResponse
// 非同期でレスポンスを実行
go handleRequest(request, sessionResponse)
}
}リクエストごとに非同期処理でレスポンスを返す処理(handleRequest())を呼び出しています。 今回はただ文字列を返しているだけなので処理時間が変動することはありません。
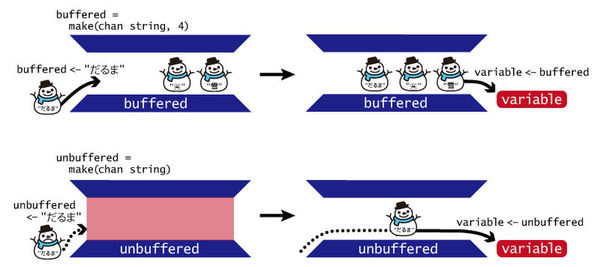
レスポンスの順番を制御するためには、Go言語のデータ構造のチャネルを使っています。 チャネルはFIFOのキューで、バッファなしとバッファありの2種類があります。 利用するには、下記のように型を指定して初期化します。
// バッファなし
unbuffered := make(chan string)
// バッファあり
buffered := make(chan string, 10)データの入出力には<-演算子を使います。また上記のサーバ実装のようにforループを使うこともできます。
// データ投入
buffered <- "データ"
// データ取り出し
variable <- bufferedバッファありの場合は、指定した個数までは自由に投入できますが、 指定した個数のデータが入っているときにさらに追加でデータを投入しようとすると、投入しようとしたスレッド(ゴルーチン)がブロックされます。 他のゴルーチンで値を取り出してきて個数が減ると、ブロックが解除されてデータが投入できます。
バッファなしの場合は、投入しようとするスレッドは即座にブロックします。 第4回のio.Readerの説明の中で紹介したio.Pipeと似ています。
パイプライニング対応版サーバの実装では、まず並列処理でレスポンスを書き込むwriteToConn()関数が順序を守って書けるように、先頭から1つずつデータを取り出すための順序整理用のキューとしてバッファなしのチャネルを使っています。 さらに、リクエスト処理が終わるまで待つため、送信データをためるバッファなしのチャネルを内部にもう一つ用意しています。 待つ側のコードはwriteToConn()の中に、送信側のコードはhandleRequest()の最後にあります。
チャネルまわりの構成を図にするとこんなイメージです。

パイプライニングのクライアント実装
package main
import (
"bufio"
"fmt"
"net"
"net/http"
"net/http/httputil"
)
func main() {
sendMessages := []string{
"ASCII",
"PROGRAMMING",
"PLUS",
}
current := 0
var conn net.Conn = nil
var err error
requests := make(chan *http.Request, len(sendMessages))
conn, err = net.Dial("tcp", "localhost:8888")
if err != nil {
panic(err)
}
fmt.Printf("Access: %d\n", current)
defer conn.Close()
// リクエストだけ先に送る
for i := 0; i < len(sendMessages); i++ {
lastMessage := i == len(sendMessages)-1
request, err := http.NewRequest(
"GET",
"http://localhost:8888?message="+sendMessages[i],
nil)
if lastMessage {
request.Header.Add("Connection", "close")
} else {
request.Header.Add("Connection", "keep-alive")
}
if err != nil {
panic(err)
}
err = request.Write(conn)
if err != nil {
panic(err)
}
fmt.Println("send: ", sendMessages[i])
requests <- request
}
close(requests)
// レスポンスをまとめて受信
reader := bufio.NewReader(conn)
for request := range requests {
response, err := http.ReadResponse(reader, request)
if err != nil {
panic(err)
}
dump, err := httputil.DumpResponse(response, true)
if err != nil {
panic(err)
}
fmt.Println(string(dump))
if current == len(sendMessages) {
break
}
}
}クライアントでは、まずリクエストだけを先行してすべて送ります。 その後、結果を1つずつ読み込んで表示しています。 レスポンスをダンプするのにリクエストが必要なため、後から取得できるようにチャネルを使っています。
今回は簡易実装なので、POSTなどの安全ではない処理が混ざった場合の対処を省略しています。 ですが、パイプライニングのだいたいの雰囲気はつかめるでしょう。
パイプライニングとHTTP/2
Go言語ではHTTP/2のデータを取り扱うAPIが公開されておらず、コードがどうしても長くなってしまうこともあってコードの紹介はしませんが、基本的には今回の連載で紹介した内容の延長でHTTP/2で取り入れられた非同期通信の機能も実装できます。
パイプライニングでは、1回の送信・受信内容は通常のHTTP/1.1の通信とまったく同じでした。 HTTP/2では、ここをバイナリ化して、小さい単位(フレーム)に分割します。 また、パイプライニングで必須だったリクエストとレスポンスの順序の保証が不要になりました。 リクエストされていないコンテンツをサーバ側から送ることもできます。
フレームには、ヘッダー用やボディー用など、いくつかの種類かあります。HTTP/1.1と異なりヘッダーの圧縮もできるようになっています。 HTTPでいうところの1つのリクエストは「ストリーム」という単位で扱われます。 ストリームは仮想的なソケットのように説明されることもありますが、TCPソケットの視点で見れば、同じストリームID(32ビットの数値)を持ったフレームの論理的なグループです。
パイプライニングでは順序を維持する必要があったため、巨大なデータが先にリクエストされると、通信路を占拠してしまうという問題がありました。 HTTP/2では、完全に問題が解決されているわけではありませんが、サーバ側で優先度を決めてレスポンスの順序も変更できるようになっています。
まとめと次回予告
前回と今回は、HTTPが持つ機能を実装することで、ソケットを効率よく使用する方法をいくつか紹介しました。 HTTPの変遷を見ると、シンプルなプロトコルから出発し、後方互換性を保ちつつTCPの性能を引き出す進化を遂げてきたことがわかります。
| 手法 | 効果 |
|---|---|
| Keep-Alive | 再接続のコストを削減 |
| 圧縮 | 通信時間の短縮 |
| チャンク | レスポンスの送信開始を早める |
| パイプライニング | 通信の多重化 |
ソケットの使用効率向上で言うと、I/O多重化のシステムコールやAPIもあります。 select、kqueue、epollといった名前を聞いたことがある人も多いでしょう。 Goのランタイムには、これらのシステムコールも組み込まれています。 今後の記事ではこれらのシステムコールについても紹介する予定です。 とはいえ、結論から述べると、とくに何もしなくてもGo言語を使っている限りはこれらの機能の恩恵を受けています。
ソケットのAPIの使い方は書籍などで見かけますが、それを効率的に活用したプロトコルの設計となると、あまりまとまった情報はありません。 オリジナルのプロトコルをゼロから設計して開発する機会はあまりないかもしれませんが、RFC化されたプロトコルを実装することはあるでしょう。 HTTPの事例だけですべてを語れないとはいえ、前回と今回の記事では、その歴史をたどることでプロトコル設計におけるソケットの生かし方を学んでいただけたと思います。 最終的なアーキテクチャは結果でしかありません。そこに至る、その場その場の機能改善の意思決定こそが、ソフトウェア設計だといえます。
次回は、TCPとともに多くのOSでサポートされているUDPについて紹介します。
ローカルエリアの通信の場合はレイテンシーが低いLZ4(http://lz4.github.io/lz4/)などのほうが効果が高いこともあります。↩
この連載の記事
-
第20回
プログラミング+
Go言語とコンテナ -
第19回
プログラミング+
Go言語のメモリ管理 -
第18回
プログラミング+
Go言語と並列処理(3) -
第17回
プログラミング+
Go言語と並列処理(2) -
第16回
プログラミング+
Go言語と並列処理 -
第15回
プログラミング+
Go言語で知るプロセス(3) -
第14回
プログラミング+
Go言語で知るプロセス(2) -
第13回
プログラミング+
Go言語で知るプロセス(1) -
第12回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(3) -
第11回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(2) -
第10回
プログラミング+
ファイルシステムと、その上のGo言語の関数たち(1) - この連載の一覧へ










")












